Improve HMA1 modeling & sampling time
Hi there,
What I have tried:
Using HMA model to generate traffic demand data. Libraries are updated.
The trip dataset contains generally origin-destinations as categoric variables, which creates a big load on memory, for example if you have 4000 origin destinations, it creates 4000^2 columns with one hot encoding. I tried switch from one hot encoding to categorical_fuzzy in my code, but still it was not sufficient to solve this complexity. Dimensionality reduction wouldn't work because I want to keep the trip data. Are there any strategy to handle with such big cardinality?
Kind Regards.
Hi @Erenhub, is the traffic demand dataset a publicly available one? If not, are you able to provide metadata for it?
I tried switch from one hot encoding to categorical_fuzzy in my code, but still it was not sufficient to solve this complexity.
I'm curious what measures you are using to say it's "not sufficient" (time, memory usage etc.). Usually switching to categorical fuzzy encoding solves the problem. If you can paste in the code where you are creating your model, I can see if there is anything being mishandled in the fuzzy computation.
Surely I can! This is household travel survey data from Australia:
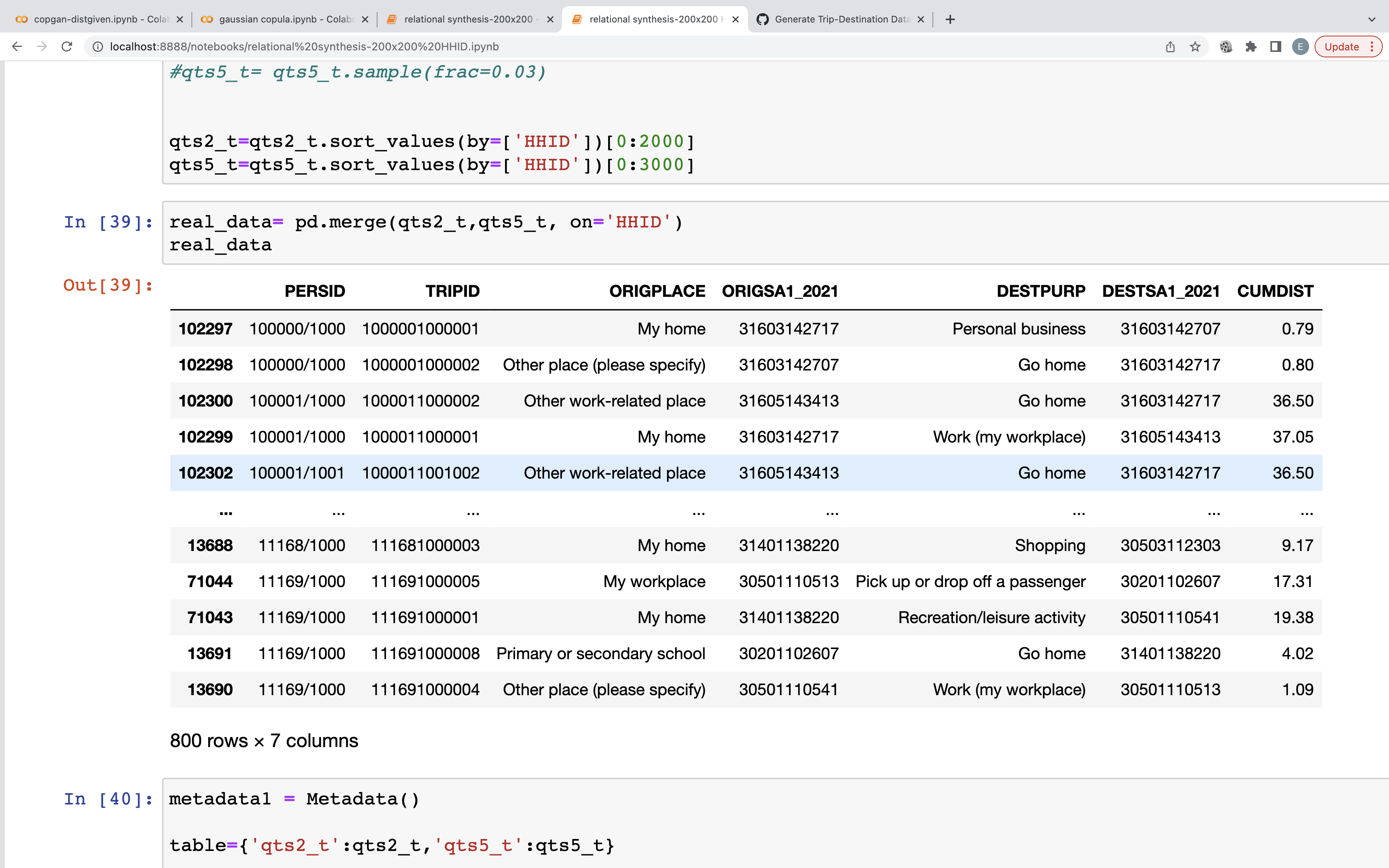
What I have been trying is :
fields_metadata = { 'ORIGSA1_2021': { 'type':'categorical' }, 'DESTSA1_2021': { 'type':'categorical' } }
from sdv.relational import HMA1 fuzzy = {'categorical_transformer': 'categorical_fuzzy'} model = HMA1(metadata1,model_kwargs=fuzzy)
model.fit(table),
where fitting takes enormous time as origin-destinations exceeds number of 400x400 (I have 50.000 observations)
Many thanks
Thanks for the detailed info @Erenhub. I can confirm that the code looks correct for what you're trying to do.
The SDV team is actively working the performance characteristics. Though this is not your intended usage, I'm curious what the performance is like without the constraint?
Some other things to try:
- I've had more success using
{'categorical_transformer': 'label_encoding' }for high dimensionality data. You might want to give this a try. - We recently released a
FAST_ML TabularPresetthat is optimized for speed. Though this is only for a single table, this might give you a useful datapoint re best case speed. This User Guide has more details, including the following benchmarks:- Datasets with around 100K rows and 50-100 columns will take a few minutes to model
- Larger datasets with around 1M rows and hundreds of columns may take closer to an hour
If it's ok with you, I suggest we re-purpose this issue to be about the HMA1 performance characteristics and keep it filed as a feature request.
Hi @npatki , thanks for your guidance. I have been trying to do it with coordinates to reduce complexity. Since it is not categoric, It works perfectly, however, It is far from generating realistic trips between two point. Do you think there could be any constraint to solve this problem?
Without the constraints, the performance did not change much.
Thanks.
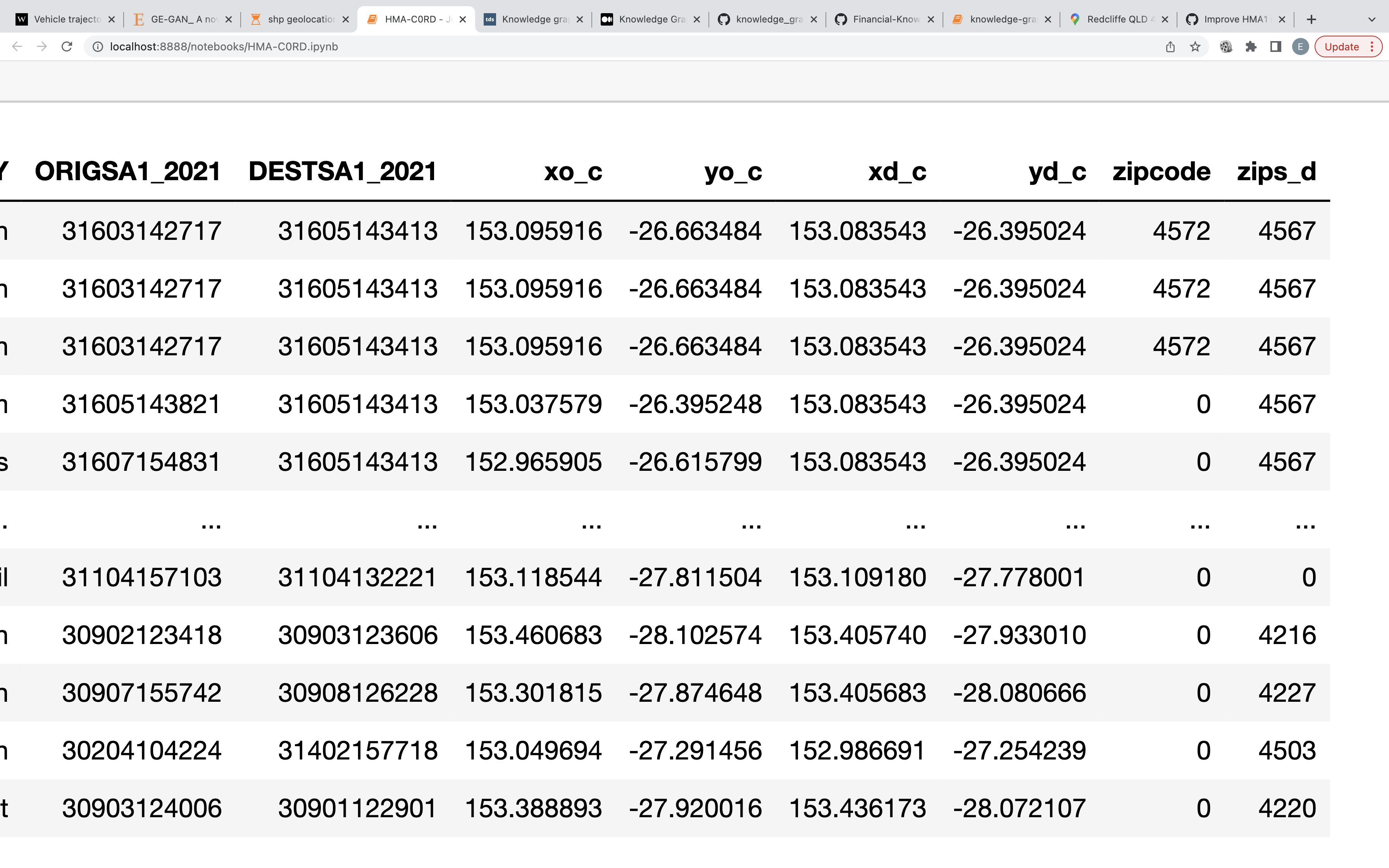
@Erenhub are these GPS coordinates? You could use a FixedCombinations constraint to recycle the start/end points you see in the real data.
However, the favorable solution might be to actually process the GPS coordinates -- extract relevant region info and then recreate it. We recently added Contextual Anonymization to our RDT library. As a concrete example, we can extract region info from phone number data. Would you be interested in something like this for geo locations?
Closing off this older issue. Since the last discussion, the team has made a number of updates with SDV 1.0+
- The HSASynthesizer is now the preferred approach for dealing with large datasets or complex schemas. This synthesizer is much faster than HMA for both modeling and sampling. Note that it requires a paid SDV plan. To learn more, visit our plans page.
- We have added a GPS column relationship specifically for lat/lon pairs see API