Improve correlation for low cardinality, discrete data
Environment Details
Please indicate the following details about the environment in which you found the bug:
- CTGAN version: 0.4.3
- Python version: 3.8.5
- Operating System: Linux
Error Description
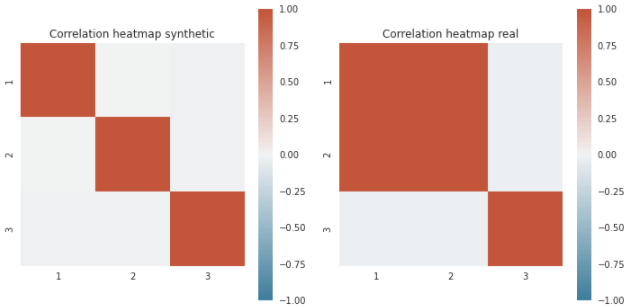
When I generate data with CTGAN on numerical data, the correlation is not maintained between the different columns ( see figure ). It is possible to reproduce my experiment below:
Steps to reproduce
Unfortunately I have this problem with most of the datasets I'm using even when I'm trying to recreate some of the work that has been done in recent papers. I provide here a small example of a dummy dataset.
# create dummy data, where column "1" and "2" are clearly correlated while the "3" is just random
dummy_data = pd.DataFrame({
'1': [1,2] * 100,
'2': [4 ,5] * 100,
"3": [random.randint(0,9) for x in range(200)],
})
# fit CTGAN on said data
ctgan = CTGAN()
ctgan.fit(dummy_data)
# generate samples
samples = ctgan.sample(1000)
Hi @Kaabachi, thanks for filing. I am seeing some improved results with the newest version of CTGAN, particularly if I increase the number of epochs. Below is an example of running with 2500 epochs.

Another challenge might be the fact that there are only 2 unique values in the dummy data, columns '1' and '2'. Depending on the meaning of the data, it might make more sense to model these as categorical variables, not numerical. Which recent work are you replicating? Does it frequently feature columns with a low number of distinct values?
From trying out CTGAN on a variety of datasets, we are seeing that it is generally converging to better and better quality correlations, especially for continuous data. Since your example is for low cardinality, discrete data, I'll make this issue more specific to that. I suspect that this may work better if (a) it is modeled as categorical or (b) if we pre-process such data to add noise.
Hello, I'm closing this issue off since we've had some discussion and we're seeing some improvements.
The issue is a bit old too -- we just released a new, SDV 1.0 library that will also take advantage of the latest techniques in data preprocessing. Check it out and let's create a new issue if this problem persists!