Render buffering optimization
Based on reading http://hacksoflife.blogspot.com/2010/02/double-buffering-vbos.html and other similar things. We appear to use that trick in several places but not everywhere. It's possible some of these changes are redundant or superfluous, but extensively benchmarking a decently high load cutscene level showed in the area of 10% improvement of framerate.
Looks good and works on my tests. Given there is precedence for using this trick and the quite good improvements in performance, I definitely support adding this change. I'd be interested in hearing what @asarium might think, too.
I'll be honest, if there are performance improvements due to this then I do not know where they come from. Please do more benchmarking to check exactly where that additional performance is coming from since the changes I see here, I would classify as inconsequential at best.
@asarium My profiling consisted of running a reasonably constrained cutscene mission, Blue Planet's Icarus, with a lua script to end the mission and restart it after exactly 150 seconds of play. This was set to run for 15 cycles, at which point the script ends the game. I used release builds identical except for these changes, with care taken to try to have them run in similar computing conditions, and data was collected on release builds with the -profile_write_file flag's output.I overlaid the data and graphed through python scripts that identify the loop point of the mission(there's a single abnormal frametime at the start of each loop to sync off of) and combined the runs for an overall performance picture.
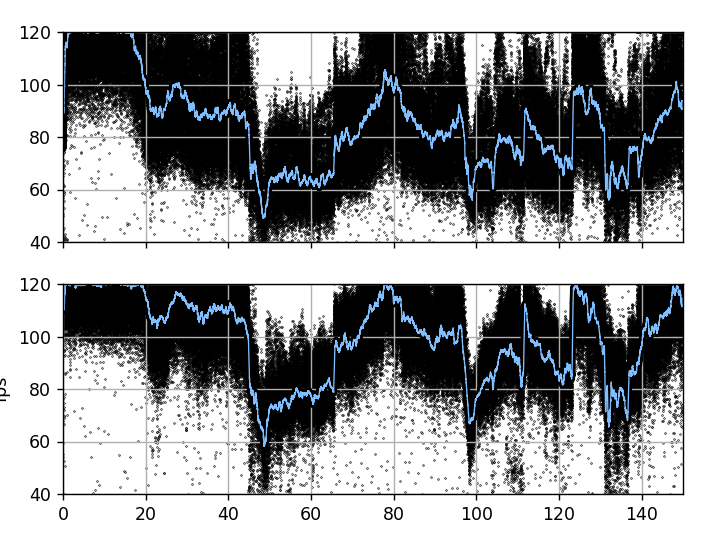
The scatter plots are fps (inverse frametime, strictly speaking) from individual frames, with the blue line being a rolling average. Top is the before build and bottom is the after.
I won't pretend I intimately understand the code or system I'm dealing with here, so I did my bet to be certain of the impact before submitting. What would you consider sufficient benchmarking? Do you need me to use more raw data than the ~37 minutes each collected here? Do you have a particular context you need to see it tested in? Must I benchmark each changed line individually? I can likely do any of these, in time.
The first thing to check is what change made the difference so yes, please benchmark with either of the files reverted back to master to determine which one of those changes actually causes the performance increase.
Furthermore, none of the changed code should be called often so that is why I am not sure why there is a performance difference. What GPU are you using? Maybe that additional glBufferData in gr_opengl_map_buffer somehow triggers a better path in the driver somehow.
Furthermore, none of the changed code should be called often so that is why I am not sure why there is a performance difference. What GPU are you using? Maybe that additional
glBufferDataingr_opengl_map_buffersomehow triggers a better path in the driver somehow.
GeForce RTX 3060
Ok, then you are definitely using the persistent mapping path here which is the only location where gr_opengl_map_buffer is used.
@asarium I did some profiling runs tonight with some permutations on the changes submitted. Crunching the numbers in any detail will have to be anotgher day, but the preliminary results suggest:
- The changes in gropengldeferred.cpp produce mildly reduced overall frame-rates when only that set of changes is included.
- Including either or both of the changed lines in gropengltnl.cpp produces comperable overall improvements in framerate, all three being close enough as to be probably insignificantly different.
- Including the changes of both files produces results in line with changing just gropengltnl.cpp.
Ok, so the improvements are definitely in the buffer mapping code. I checked the OpenGL spec again and (unless there is a bug in our code), the change should produce a GL_INVALID_OPERATION error since glBufferData is called on a buffer that was initialized with glBufferStorage which should make the buffer immutable.
If such an error is not produced then this may be a bug in the Nvidia driver. Do we have any data on what happens either with an AMD card or maybe another driver implementation (e.g. the open source Linux drivers)?
If I can find any clearer version of this down the line I'll reopen it, but for now I'll take it off the backlog.