reduce payload size further
low hanging fruit:
- enable gzip
- optimize JSON structure
current structure:
{
"commits": [
[1594068256, "8981dbbc36f1575b0a417b6849767bde29e7c6b4"],
[1594083404, "70f9d23b916f2db7da711aa4a0317a218997ba42"],
],
"benchmarks": {
"regression-31157": { // benchName
"check": { // buildKind
"full": { // cacheState
"is_interpolated": [122,23,523, ...],
"points": [719798144, 719807680, ...],
}
}
},
}
}
this is still wasteful, since is_interpolated appears to be shared across the entire benchName, so moving it up 2 levels will significantly reduce duplication in both keys and values. something like:
{
"commits": [
[1594068256, "8981dbbc36f1575b0a417b6849767bde29e7c6b4"],
[1594083404, "70f9d23b916f2db7da711aa4a0317a218997ba42"],
],
"benchmarks": {
"regression-31157": { // benchName
"interpolated": [122,23,523, ...],
"kinds": {
"check": { // buildKind
"full": [719798144, 719807680, ...] // cacheState: y-values
}
}
}
}
}
even smaller would be to squash "kinds" level and just skip "interpolated" in the buildKind/for-in loop. i'm size/perf obsessed, so i'd personally go for this:
{
"commits": [
[1594068256, "8981dbbc36f1575b0a417b6849767bde29e7c6b4"],
[1594083404, "70f9d23b916f2db7da711aa4a0317a218997ba42"],
],
"benchmarks": {
"regression-31157": { // benchName
"interpolated": [122,23,523, ...],
"check": { // buildKind
"full": [719798144, 719807680, ...] // cacheState: y-values
}
}
}
}
cc @Mark-Simulacrum
I'm working in this area and just wanted to note that is_interpolated may not be the same for each series within a benchmark. You can see this when there are the differences in the pink parts of the graphs:
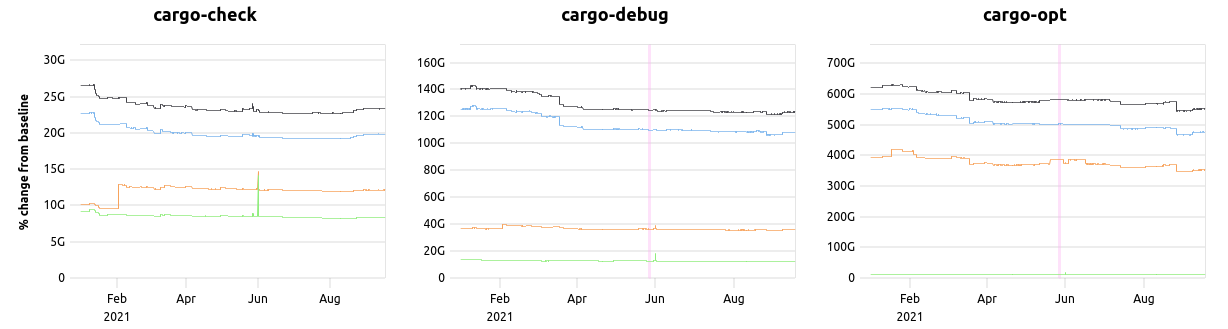
Of course, you could optimize for the cases where they are the same for each series in a benchmark, but I suspect the complexity wouldn't be worth it.