HiFiplusplus-pytorch
 HiFiplusplus-pytorch copied to clipboard
HiFiplusplus-pytorch copied to clipboard
HiFi++: a Unified Framework for Neural Vocoding, Bandwidth Extension and Speech Enhancement

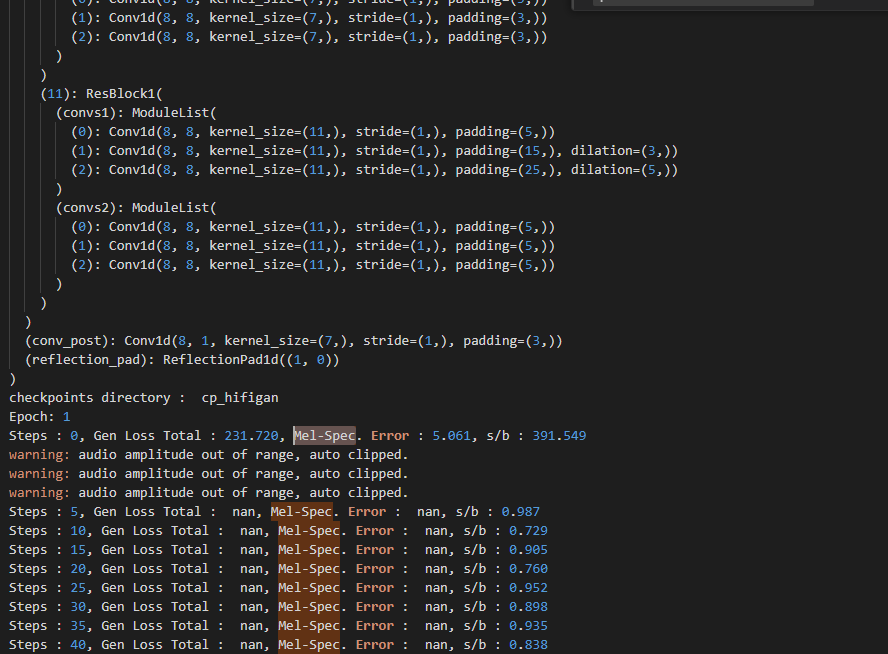 mel_error is nan in the first step when training by config_v2.json, is there anyone who meets the same problem? And how to fix it?
 I trid modifying code a bit but the issue is still the same. Can you help?
Hi, I traned a model for the Bandwidth expansion task using the code and VCTK dataset. But I got bad generated wavs, which contain Single frequency lines in Spectrogram ,...
which is better for TTS, hifigan vs hifi++?
Metadata
Owner
Metadata
HiFi++: a Unified Framework for Neural Vocoding, Bandwidth Extension and Speech Enhancement