Benthos v4 pipeline using kafka sarama input and kafka sarama dynamic outputs producing errors not seen with v3
We have a simple pipeline that reads from a kafka topic, and depending on each message's metadata it will publish the msg to another kafka topics created dynamically (dynamic outputs). The pipeline has been running smoothly for a long time using benthos v3, sarama 1.30.1. We've just migrated to benthos v4 and we've been hitting some strange errors that we haven't seen on other pipelines using also benthos v4, the same sarama version, but with kafka outputs created statically in the pipeline.
The new version v4, on load, with some considerable consumer lag, while it ends up delivering the messages, looks very unstable and produces a lot of errors not seen before:
"Failed to send '44' messages: circuit breaker is open"
"Failed to send '68' messages: kafka: client has run out of available brokers to talk to (Is your cluster reachable?)"
"Failed to send '48' messages: EOF"
Rolling back to the previous version the errors stop.
As a side effect of maybe not being able to write the messages immediately, our pods also consume a lot more memory than the previous versions (the exact same config).
With the previous versions, we never hit this error and now we do it constantly: https://github.com/anovateam/benthos/blob/6975c18d94cbf0bc63c6507bfbfb1adb8857b4ad/internal/impl/kafka/output_sarama_kafka.go#L420
When we have some load we also see this fatal error that is crashing the process:
fatal error: concurrent map read and map write
stack trace log.txt
We've also noticed that some default values changed on the consumer, for instance, checkpoint_limit which changed from 1 to 1024, but we already were using the same value so it shouldn't affect.
I know this isn't much information, but I'm only hoping that these symptoms might ring the bell of something that was changed on v4 probably on dynamic outputs.
Maybe not relevant but we're using Azure Event Hubs with kafka interface. The exact same ones on both versions.
Hey @mfamador, sounds like possibly more than one issue here. The fatal error should be quick to fix but unfortunately the trace you've attached is missing the beginning which is where the important info is. Can you try grabbing the whole thing? If it's too big then try using fewer threads and outputs as that'd reduce the amount of noise in there.
I've got the stack trace from loki so the last line is the first. Since we've reverted we don't have the new version running anymore to get a new stack trace. But I'll try again and get a new one tomorrow morning.
There's the full stack trace for the fatal error we're getting.
About the errors on the dynamic outputs, here's a screenshot where we ran the pipiline using benthos v4 from 10:04 to 10:14 and despite the consumer lag decreased there are a lot of errors when sending the msgs. After 10:14 we reverted to the one using benhos v3 and the errors stoped while the consumer lag probably decreased faster. We don't see this behaviour in other pipelines using statically created kafka outputs. And we have another kubernetes cluster where we've made the same tests and we're getting the fatal error and this "Failed to send x messages" only a few times.
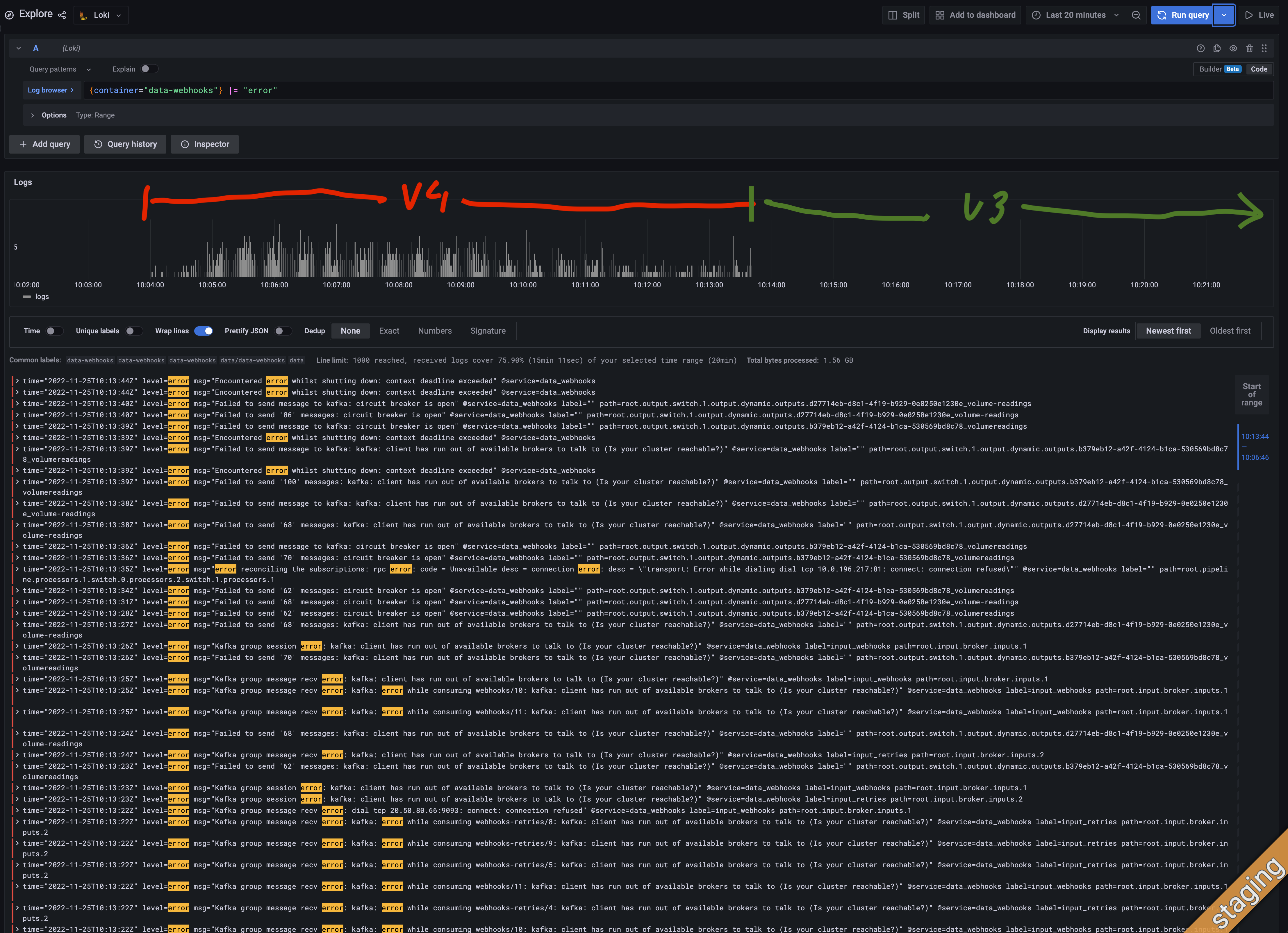
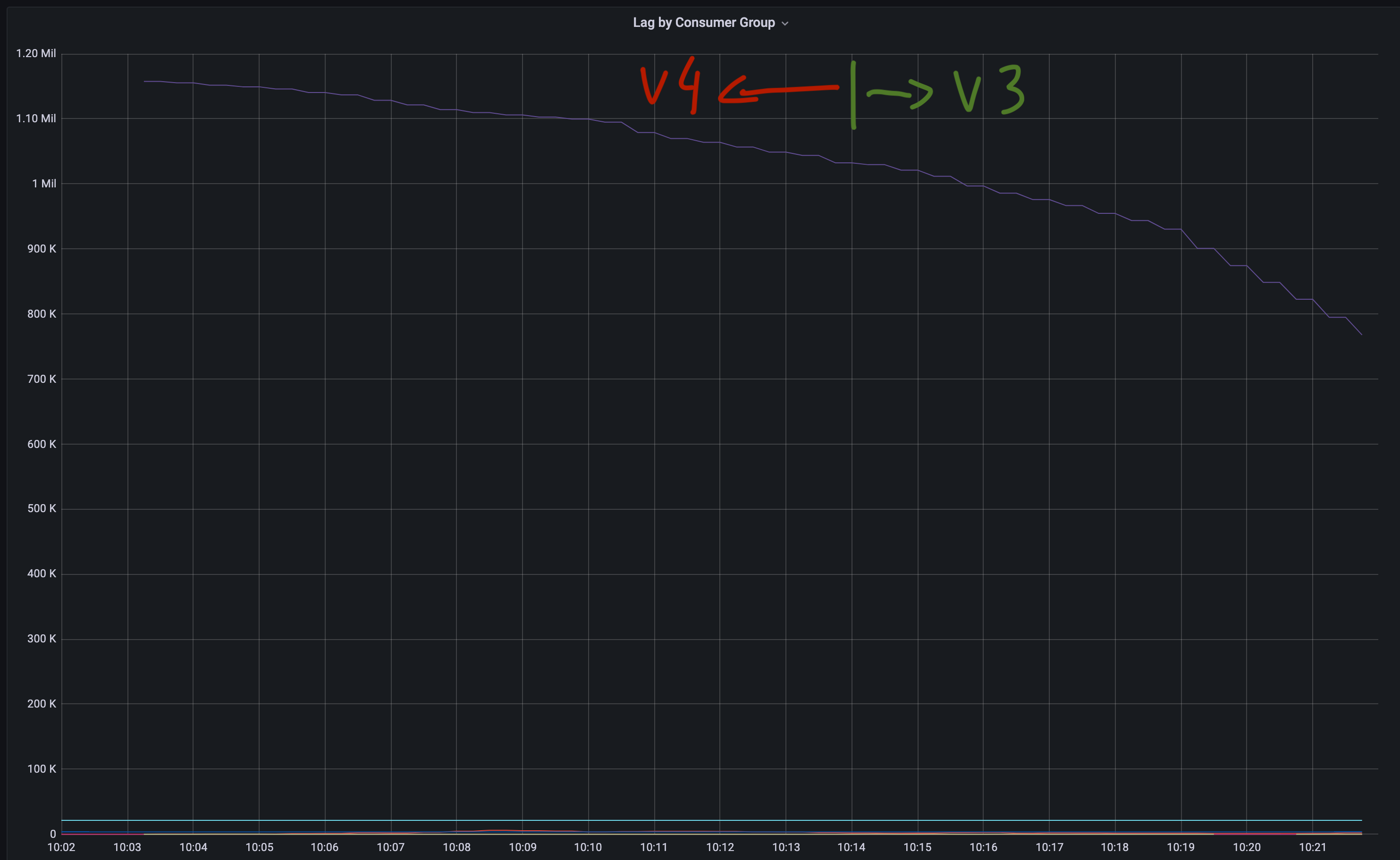
Interesting, it's possible there was a small regression in the dynamic output refactor, I've done a bit of tidying up that'll possibly help: https://github.com/benthosdev/benthos/commit/e221ea85f2b5710e434d47bb636d5f9dca6a1a2f.
Unfortunately the trace isn't helping narrow down the error. It looks as though some component is duplicating messages without respecting shallow or deep copying, I won't be able to narrow that down without seeing the config but if you're running custom plugins it's worth just doing a quick check to make sure you're calling a copy on any messages you're doing complex stuff with.
Thanks, @Jeffail. We'll try to debug it to understand if there's any issue or any timeout on the sarama output (or even the input might be ingesting more messages on this version) that might have changed which justifies the different behaviour. We'll let you know if we find something.
Definitely, there are two different issues.
About the first "Failed to send '44' messages: circuit breaker is open" I couldn't figure out much, just that it already happened before with v3 after all, but way less frequently, maybe something changed on the defaults and we're just trying to write more.
About the second, I'm getting different results using 4.10 or 4.11.
Using 4.10, my pipelines keep crashing with the concurrent map writes, basically setting the metadata on the same message from different go routines.
fatal error: concurrent map writes
goroutine 11640 [running]:
github.com/benthosdev/benthos/v4/internal/message.(*messageData).MetaSetMut(...)
/go/pkg/mod/github.com/benthosdev/benthos/[email protected]/internal/message/data.go:176
github.com/benthosdev/benthos/v4/internal/message.(*Part).MetaSetMut(...)
/go/pkg/mod/github.com/benthosdev/benthos/[email protected]/internal/message/part.go:142
github.com/benthosdev/benthos/v4/public/service.(*Message).MetaSet(0x33f1bbe?, {0xc007c81040, 0x34}, {0x33ee9d2?, 0x2?})
/go/pkg/mod/github.com/benthosdev/benthos/[email protected]/public/service/message.go:221 +0x176
dev.azure.com/anovateam/Mapleleaf/datawebhooks/internal/processor.(*matcher).Process.func1(0xc008c64be0, {0xc001a34510?, 0xc006f3c210?})
/build/internal/processor/matcher.go:159 +0x1b6
created by dev.azure.com/anovateam/Mapleleaf/datawebhooks/internal/processor.(*matcher).Process
/build/internal/processor/matcher.go:153 +0x3de
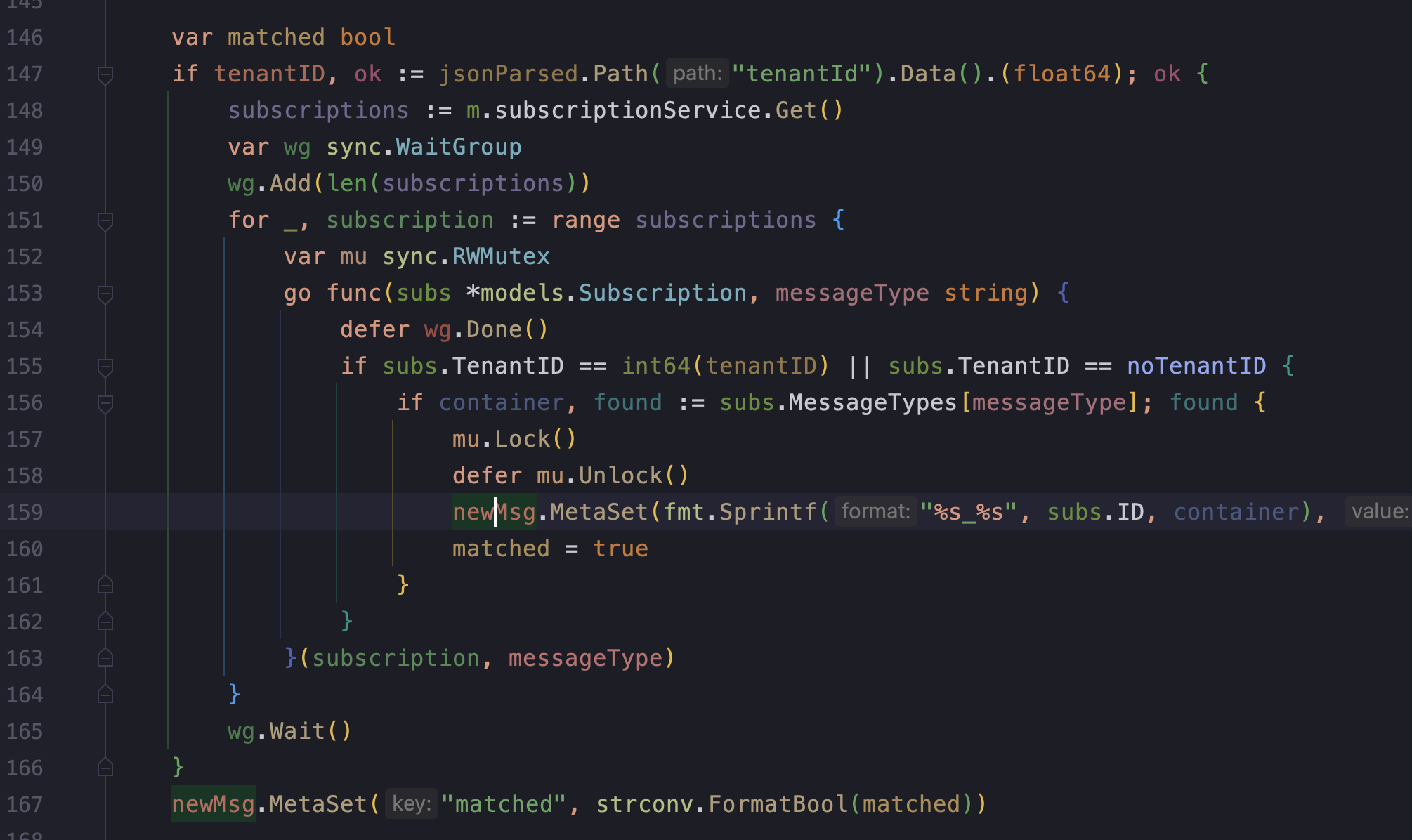
Upgrading to 4.11 the concurrency fatal error apparently is solved (maybe less frequently at least) but now some replicas with kafka inputs just get stuck and some partitions keep lagging ... maybe not related, maybe if the replica keeps crashing the partition rebalancing problem is just offuscated. Restarting the replicas all messages are consumed and the lag goes to zero.
This issue is a mess, feel free to close it, I'll try to gather more intel on this problem and try to create separate issues if it makes more sense.
Maybe on 4.11 when it was solved the concurrency crash might have caused now a deadlock (?)
Edit: it still crashes on the same line on 4.11, we just didn't have sop much load at the time
We have many other kafka pipelines without this lag problem. The big difference is that on this one the sarama outputs are dynamic and have this small processor that reveals the concurrency issue. If we remove the goroutines and we still have the lag issue we might maybe consider the culprit are indeed the dynamic outputs on v4.
We're setting now the metadata outside of the goroutines it should fix the concurrency problem, but I wonder if we should take care of it also on benthos (maybe it was on v3 since we didn't see this issue?)
Running for about 40 min a new version not setting metadata in goroutines concurrently - no crashes We're also fixating the number of replicas - no HPA now - and we're also not seeing the missing partitions on rebalancing.
I'll try to force rebalancing to see if there's any problem assigning the partitions too often - maybe crashing was forcing rebalancing too often causing some of them not to be consumed?
I think we can close this one and I'll create other ones if it makes sense and when I gather more concrete info.
- should MetaSet be thread safe - as apparently it was on v3?
- rebalancing sarama dynamic outputs too often misses some partitions and causes consumer lag to grow (?)
After one hour, 2 pods (of 12) were replaced and somehow another partition is missing causing the consumer lag to grow, all pods are consuming even the new ones, just a partition is missing. Killing one pod, probably a rebalancing was made, and the consumer lag dropped abruptly.
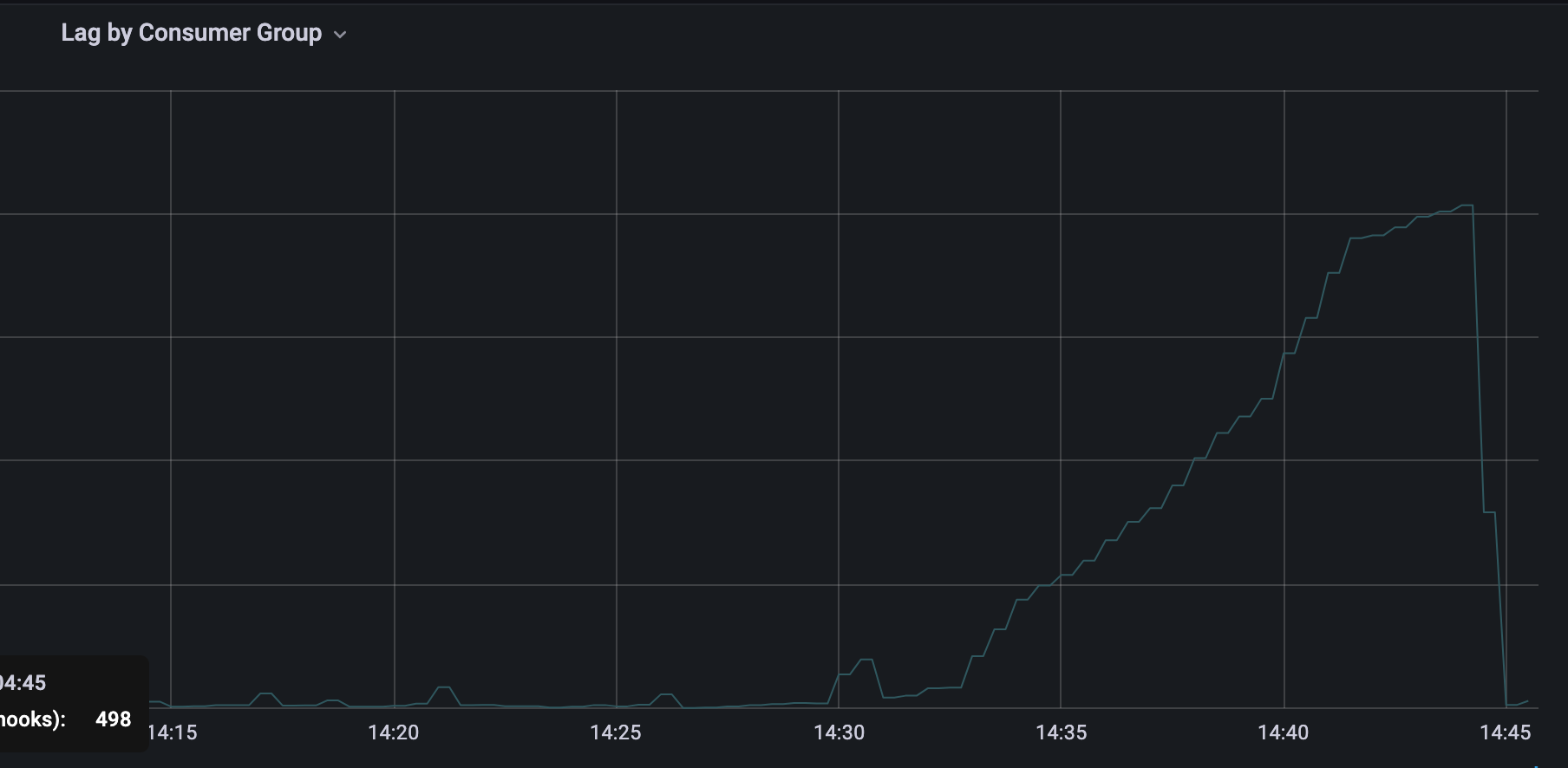
After removing the autoscaling, thus not having rebalancing too often (one or two pods were replaced at the beginning), all partitions are still being consumed without any consumer lag.