[Migration] TorchAudio Beamforming Module Migration
TorchAudio Beamforming Module Migration
Overview
torchaudio supports an integrated MVDR module under torchaudio.transforms. To use it, users need to provide ref_channel and solution (options: [ref_channel, evd, power]) when initializing the module, and give the multi-channel complex-valued spectrum, time-frequency masks of speech and noise as the input arguments. For example:
mvdr = torchaudio.transforms.MVDR(ref_channel=0, solution="ref_channel")
batch_size, channel, freq, time= 1, 6, 257, 100
spectrum = torch.rand(batch_size, channel, freq, time, dtype=torch.complex64)
mask_speech = torch.rand(batch_size, freq, time)
mask_noise = torch.rand(batch_size, freq, time)
enhanced_spectrum = mvdr(spectrum, mask_speech, mask_noise)
Here are some limits of the module as discussed in #2158:
- The current MVDR module computes the power spectral density (PSD) matrices internally by using the input spectrum and time-frequency masks. In research, users may want to manipulate the PSD matrices manually (e.g., estimate the PSD matrix using a neural network, add regularization, etc).
- The optimal reference channel may change if there are variant microphone arrays, it's better to be decided when calling
forwardmethod. - The MVDR module composed three different solutions. Separating them into different modules helps users have better understandings of the functionality.
Migration Stages
We will perform the migration in multiple stages.
Stage 0
Add separated methods for each stage of beamforming processing. This includes:
-
psd(compute PSD matrix of the spectrum w/- or w/o time-frequency mask) -
mvdr_weights_souden(Compute the mvdr weight by the method proposed by Souden et, al.) -
mvdr_weights_rtf(Compute the mvdr weight based on the relative transfer function (RTF) and power spectral density (PSD) matrix of noise) -
rtf_evd(Estimate the relative transfer function (RTF) or the steering vector by eigenvalue decomposition) -
rtf_power(Estimate the relative transfer function (RTF) or the steering vector by the power method) -
apply_beamforming(Apply the beamforming weight to the multi-channel noisy spectrum to obtain the single-channel enhanced spectrum)
Stage 1 (Refactor the current modules in transforms)
Replace the internal functions in torchaudio.transforms.PSD and torchaudio.transforms.MVDR with the new beamforming methods above. This will verify the above methods on the real multi-channel data in the tutorial.
Stage 2 (Add deprecation message to the current MVDR module)
Stage 3 (Add new beamforming modules in transforms)
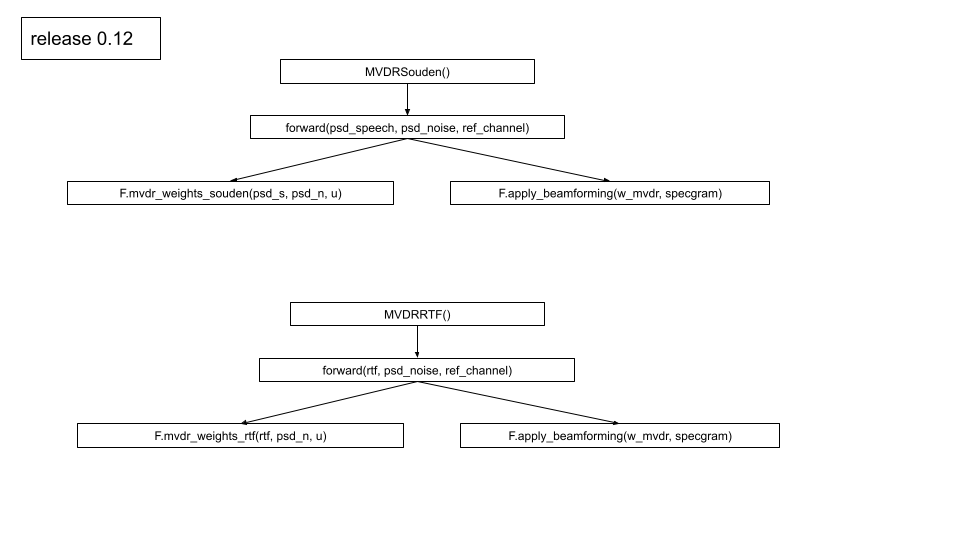
The MVDR module will be separated into two modules: MVDRSouden, MVDRRTF.
MVDRSouden uses spectrum, psd_speech, psd_noise, ref_channel as arguments in forward method.
MVDRRTF uses spectrum, rtf, psd_noise as the arguments in forward method.
Stage 4 (Remove torchaudio.transforms.MVDR module)
After the new release that includes the new beamforming methods is out, remove the MVDR module in the main branch.
Timeline
| Migration Phase | 1 | 2 | 3 | |
| PyTorch/torchaudio versions | 1.11.1 / 0.11.1 | 1.12 / 0.12 | TBD | |
| Class / function | ||||
T.MVDR
| Deprecated | Deprecated | Removed | |
F.psd,
F.mvdr_weights_souden,
F.mvdr_weights_rtf,
F.rtf_evd,
F.rtf_power,
F.apply_beamforming |
Added | Added | Added | |
T.MVDRSouden,
T.MVDRRTF |
Added | Added |
Affected Functions

PRs
phase 1 (Add beamforming methods to functional
- [x] #2227
- [x] #2228
- [x] #2229
- [x] #2230
- [x] #2231
- [x] #2232
- [x] #2369
phase 2 (Add new beamforming modules in transforms)
- [x] #2367
- [x] #2368
phase3 (Refactor MVDR module to use the methods in functional)
- [x] #2382
- [x] #2383
phase 3 (Update MVDR tutorial by using the new methods and modules)
cc @mthrok @anjali411 @Emrys365 @popcornell @boeddeker