Use SP-GiST indexes when available
Since PostGIS 2.5 and PostgreSQL 11, spgist indexes are available for 2d and 3d geometries. PostGIS performance testing indicates they are beneficial with many overlapping objects. This is the situation with most osm2pgsql tables.
I collected some real-world data on the differences between the indexes. To better emulate tile server queries I turned parallelism and jit off.
| Property | GiST | SP-GiST |
|---|---|---|
| polygon Build time | 2h38m | 2h4m |
| polygon Index size¹ | 71 GB | 21 GB |
| PIP query | 22.4s | 11.9s |
| polygon bbox query | 189ms | 188ms |
| point build time | 31m18s | 25m51s |
| point index size | 7.6 GB | 7.0 GB |
| point tile query | .212ms | .222ms |
The difference in polygon performance is likely to be more significant on servers with less RAM or when more queries are running, increasing the size of the working set. Mine has enough RAM to keep the entire GiST index cached in memory.
Most polygon and linestring tables will have objects that bbox overlap, so we should use spgist indexes for those tables. I could go either way on points.
Queries
Point in polygon (PIP)
create materialized view vancouver_addresses as
select way from planet_osm_polygon
where "addr:housenumber" is not null
and way && st_setsrid( st_makebox2d( st_makepoint(-13749536,6275628), st_makepoint(-13575258,6350078)), 3857);
select *
from vancouver_addresses v
join planet_osm_polygon p on (st_intersects(v.way, p.way))
where p.building is not null;
polygon bbox
select * from planet_osm_polygon where way && st_setsrid( st_makebox2d( st_makepoint(-13749536,6275628), st_makepoint(-13575258,6350078)), 3857);
point tile
select * from planet_osm_point where way && st_setsrid( st_makebox2d( st_makepoint(-13706082,6321652), st_makepoint(-13704853,6322874)), 3857);
Footnotes
1: Index sizes are based on a single index build, but at least GiST index size is variable
@pnorman , yes, you can use SP-GiST quite successfully for indexing line type tables, but be aware of this limitation:
You cannot use an SP-GiST type spatial index on the 'way' column as input for the PostgreSQL CLUSTER command. It is quite coincidental, but I just found this out today attempting to use CLUSTER against a line table with an SP-GiST index. PostgreSQL returned a:
"cannot cluster on index <INDEX_NAME>" because access method does not support clustering"
type error. I already knew this was the case with BRIN, and for BRIN this limitation is a logical consequence of the techical structure of the index, which excludes it as input type for a clustering operation, but hadn't expected the same limitation for SP-GiST.
So it seems PostgreSQL is currently only capable of using GiST type indexes as input for CLUSTER.
And you are probably also aware of the ongoing work for re-writing the GiST implementation in PostgreSQL, to make indexing (potentially parallel and) much faster, e.g.: https://commitfest.postgresql.org/31/2824/
PostgreSQL 13.1 / PostGIS 3.0.3 by the way.
So it seems PostgreSQL is currently only capable of using GiST type indexes as input for CLUSTER.
We don't cluster on the geometry indexes, and in fact doing so would make the table ordering worse.
We don't cluster on the geometry indexes, and in fact doing so would make the table ordering worse.
I can see how clustering based on the spatial index would not be as good as the Hilbert curve's results as created by an 'ORDER BY way' clause, but it does seem to result in at least significantly more spatially coherent data. The first image below is a fetch of the first 5000 records as shown in DBeaver, and as returned from a much larger Germany dataset with OpenStreetMap's main road classes, and clearly shows signs of severe spatial fragmentation after the particular processing done on the dataset. The second image shows a similar 5000 record fetch of the same dataset after spatial defragmentation using CLUSTER with the spatial index as input.
Before clustering:
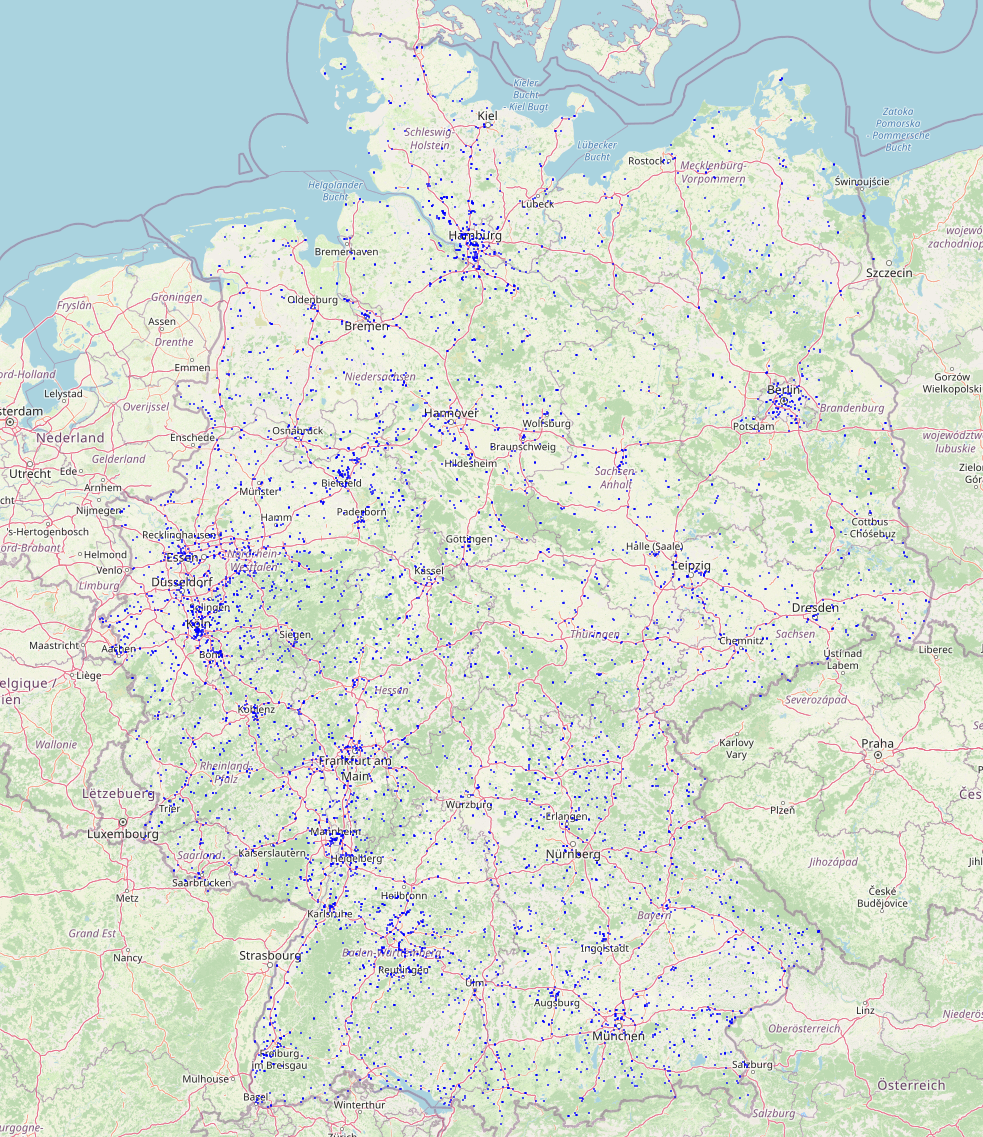
After clustering:
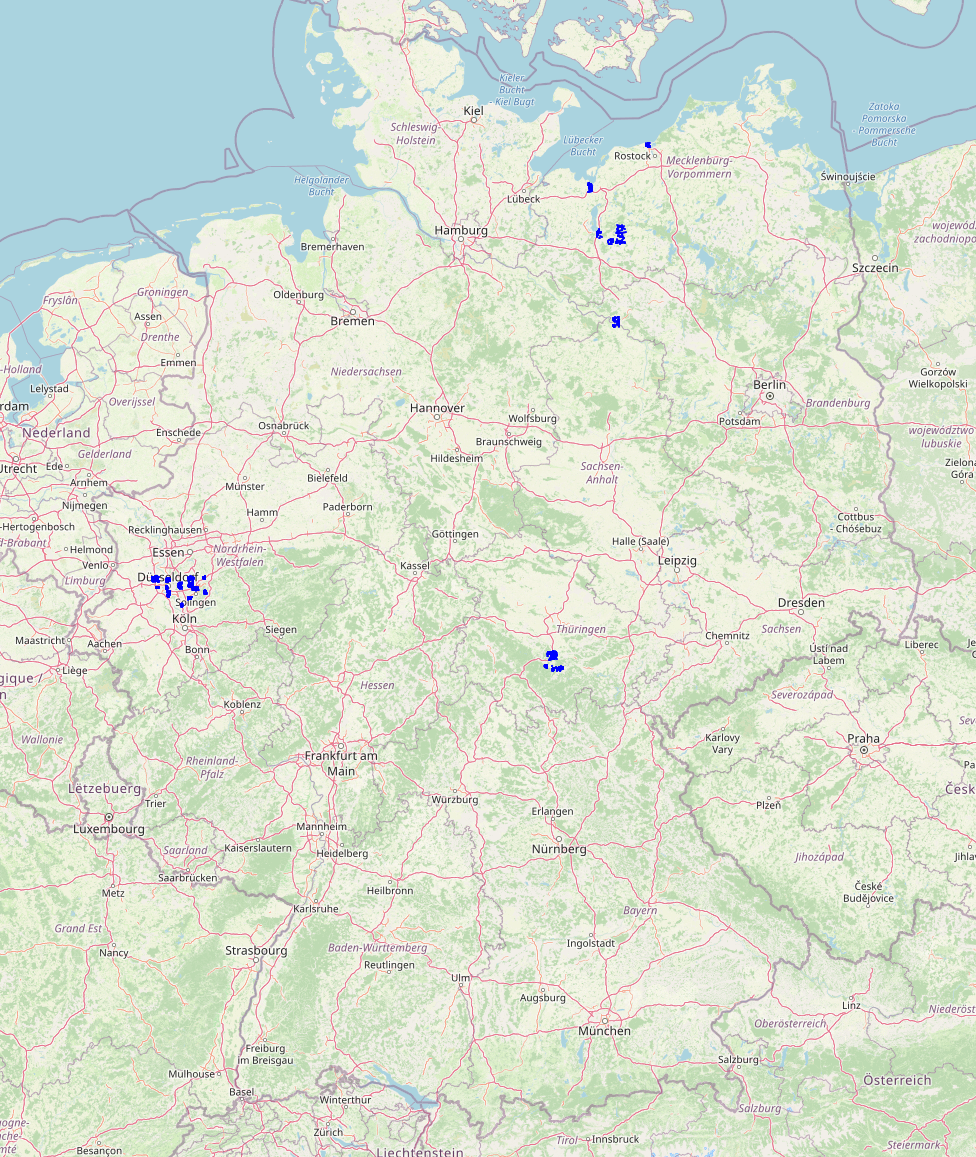
I can see how clustering based on the spatial index would not be as good as the Hilbert curve's results as created by an 'ORDER BY way' clause, but it does seem to result in at least significantly more spatially coherent data. The first image below is a fetch of the first 5000 records as shown in DBeaver, and as returned from a much larger Germany dataset with OpenStreetMap's main road classes, and clearly shows signs of severe spatial fragmentation after the particular processing done on the dataset. The second image shows a similar 5000 record fetch of the same dataset after spatial defragmentation using CLUSTER with the spatial index as input.
If you're getting this behavior, can you open up a new issue with details including the osm2pgsql command line, postgresql and postgis versions, and testing methods.
If you're getting this behavior, can you open up a new issue with details including the osm2pgsql command line, postgresql and postgis versions, and testing methods.
@pnorman, there's no need for this. The spatial fragmentation I showed was the consequence of some custom PostgreSQL / PostGIS processing I developed, and that required the CLUSTER step to solve it, and is unrelated to osm2pgsql.
osm2pgsql's output is fine using the ORDER BY and Hilbert Curve result of PostGIS 3.x.
I've reindexed my planet database right after an initial import.
The size benefit is clear, almost 1/3 of GIST index (except for planet_osm_point). The spped benefit is also there; started indexing during the initial import, the spgist finished before the gist ones.
All tests done with PG 13 and postgis 3.1.
All my conditionnal indices are now spgist too, with the same benefit.
I've reindexed my planet database right after an initial import.
The size benefit is clear, almost 1/3 of GIST index (except for planet_osm_point). The spped benefit is also there; started indexing during the initial import, the spgist finished before the gist ones.
All tests done with PG 13 and postgis 3.1.
All my conditionnal indices are now spgist too, with the same benefit.
What about speed of actually using SP-GIST versus GIST indexed data, e.g. during rendering in some toolchain, or display in e.g. QGIS? Do you have any experiences to share? E.g. I know from experience that using BRIN significantly slows down spatially accessing Polygon and Line type data in a GIS.
Here is a comparison, done on an idle server with a fresh planet import:
I kept the best EXPLAIN ANALYZE time of 10 runs.
GIST
osm=# create index on planet_osm_roads using gist(way);
CREATE INDEX
Time: 275889,369 ms (04:35,889)
public.planet_osm_roads_way_idx | 1913 MB (index)
EXPLAIN ANALYZE select count(*) from planet_osm_roads where way && st_transform(st_envelope(st_buffer(st_geogfromtext('SRID=4326;POINT(2.35 48.85)'), 239062.5)::geometry), 3857);
Aggregate (cost=454451.80..454451.81 rows=1 width=8) (actual time=188.350..188.351 rows=1 loops=1)
Output: count(*)
Buffers: shared hit=44022
-> Bitmap Heap Scan on public.planet_osm_roads (cost=11925.94..453188.08 rows=505487 width=0) (actual time=61.695..164.610 rows=467675 loops=1)
Recheck Cond: (planet_osm_roads.way && '0103000020110F000001000000050000008A984F390992F8C0A8995B9EFC7A56418A984F390992F8C055909B831C42594127357A78A00C234155909B831C42594127357A78A00C2341A8995B9EFC7A56418A984F390992F8C0A8995B9EFC7A5641'::geometry)
Heap Blocks: exact=36496
Buffers: shared hit=44022
-> Bitmap Index Scan on planet_osm_roads_way_idx (cost=0.00..11799.57 rows=505487 width=0) (actual time=56.365..56.366 rows=467675 loops=1)
Index Cond: (planet_osm_roads.way && '0103000020110F000001000000050000008A984F390992F8C0A8995B9EFC7A56418A984F390992F8C055909B831C42594127357A78A00C234155909B831C42594127357A78A00C2341A8995B9EFC7A56418A984F390992F8C0A8995B9EFC7A5641'::geometry)
Buffers: shared hit=7526
Planning Time: 0.545 ms
Execution Time: 188.387 ms
SP-GIST
osm=# create index on planet_osm_roads using spgist(way);
CREATE INDEX
Time: 116051,852 ms (01:56,052)
public.planet_osm_roads_way_idx | 731 MB (index)
EXPLAIN ANALYZE select count(*) from planet_osm_roads where way && st_transform(st_envelope(st_buffer(st_geogfromtext('SRID=4326;POINT(2.35 48.85)'), 239062.5)::geometry), 3857);
Aggregate (cost=449537.00..449537.01 rows=1 width=8) (actual time=205.947..205.948 rows=1 loops=1)
Output: count(*)
Buffers: shared hit=71597
-> Bitmap Heap Scan on public.planet_osm_roads (cost=7011.14..448273.28 rows=505487 width=0) (actual time=88.011..182.291 rows=467675 loops=1)
Recheck Cond: (planet_osm_roads.way && '0103000020110F000001000000050000008A984F390992F8C0A8995B9EFC7A56418A984F390992F8C055909B831C42594127357A78A00C234155909B831C42594127357A78A00C2341A8995B9EFC7A56418A984F390992F8C0A8995B9EFC7A5641'::geometry)
Heap Blocks: exact=36496
Buffers: shared hit=71597
-> Bitmap Index Scan on planet_osm_roads_way_idx (cost=0.00..6884.77 rows=505487 width=0) (actual time=82.911..82.911 rows=467675 loops=1)
Index Cond: (planet_osm_roads.way && '0103000020110F000001000000050000008A984F390992F8C0A8995B9EFC7A56418A984F390992F8C055909B831C42594127357A78A00C234155909B831C42594127357A78A00C2341A8995B9EFC7A56418A984F390992F8C0A8995B9EFC7A5641'::geometry)
Buffers: shared hit=35101
Planning Time: 0.344 ms
Execution Time: 206.379 ms
There is a small 10% impact on a single query but of course all the data is in the cache and possible benefit of have more index/data in the cache thanks to small spgist index is lost in this single test. A real world test with a full speed rendering run is needed to have a better idea. I'll try to do that soon...
There is a small 10% impact on a single query but of course all the data is in the cache and possible benefit of have more index/data in the cache thanks to small spgist index is lost in this single test.
Thanks, that appears not to bad. It would also be interesting to see a comparison for other geometry types, especially Polygon.
It is now possible to use an SP-GiST index (as well as any other index type) with the flex output. See https://osm2pgsql.org/doc/manual.html#defining-indexes for details.