ppq
 ppq copied to clipboard
ppq copied to clipboard
PPL Quantization Tool (PPQ) is a powerful offline neural network quantization tool.

* 添加了许多新的使用说明文件 * 移除了 PPLCUDA_INT4_Quantizer, PPLCUDAMixPrecisionQuantizer以及相关的内容 * 在tqc中添加了属性 require_export 用于后续控制导出逻辑 * 修复了一个子图切分的bug,当block直接连接图的input时可能造成切分错误 * 调整一些程序逻辑使得新的样例可以运行
1. update new dispatchers for quantizing all ops in quantable ops, this is used for npu backend 2. update prelu
## 目的 支持 ncnn ViT int8 。WIP。 ## 方案 * 新增 Concat/Add/LayerNorm/mha/Gelu 量化支持 * LayerNorm 用 channel-wise power-of-2 方法 * ncnn 要支持对应 opr 推理 * mha int8 已完成 https://github.com/Tencent/ncnn/pull/3940
my device is i7-8750H Start Benchmark with openvino (Batchsize = 1) Time span (FP32 MODE): 68.0568 sec Time span (INT8 MODE): 85.6443 sec i don't konw what is happend, how...
切到 `08dc0f8b10ecc8f41e52d7a0d4e7b5dc89a92f66` 会报错。 ```bash 2022-06-05 18:02:30,982 - mmdeploy - ERROR - name 'NCNNRequantizePass' is not defined 2022-06-05 18:02:30,982 - mmdeploy - ERROR - onnx2ncnn_quant_table failed. ``` 切 `54c0e3f6f7f469a1a184f54c8c565d93777c6e74` 没事。多加点 CI...
该更新将核心升级至0.6.6,将修改图调度与异构执行策略,并添加了动态量化与FP8量化的能力,我们目前使用E4M3进行FP8的量化,下表展示了FP8的模型量化精度。 | Inceptionv3 | mnasnet 0.5 | mnasnet 1.0 | squeezenet | shufflenet | resnet18 | mobilenetv2 | mobilenetv3 | efficientnet-b0 | efficientnet-b1 -- | -- | -- | --...
请问一下我这边有个模型,量化分析的时候误差比较大,这个怎么优化处理?选的TargetPlatform.PPL_CUDA_INT8 默认设置。 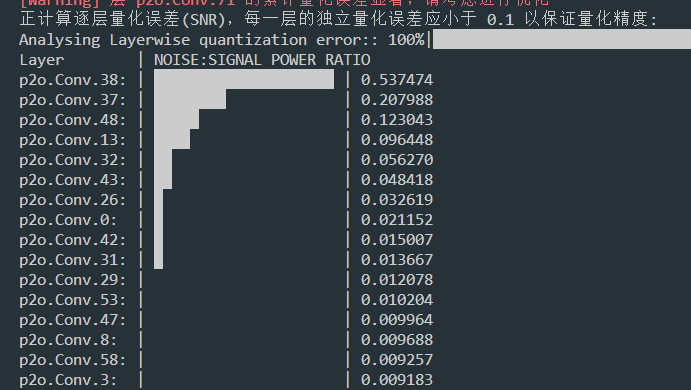
你好,我在跑yolo样例代码时,利用02_Quantization.py代码生成了batchsize 为32的int8量化的tensorrt的engine(基于yolov6s模型),利用04_Benchmark.py进行评估时,报一下错误。 [executionContext.cpp::enqueue::282] Error Code 3: API Usage Error (Parameter check failed at: runtime/api/executionContext.cpp::enqueue::282, condition: batchSize > 0 && batchSize
Metadata
Owner
Metadata
PPL Quantization Tool (PPQ) is a powerful offline neural network quantization tool.