FairFace Bias experiments: misclassification rates much lower when using released models
Once again thank you for your work on CLIP, for releasing pre-trained models and for conducting the experiments described in the paper.
I've recently tried to recreate the experiments that were done on the FairFace dataset, as described in Section 7.1: Bias of the paper. My goals are:
- to better understand the dependency on the chosen prompts,
- to study the effect of the model size, and
- to better assess what the impact of the bias would be when applying CLIP to new problems.
Of course, I cannot exactly reproduce the experiments because I can only use the released models. Still, I've reached the surprising conclusion that with the released models the misclassification rate into the non-human categories is much lower than reported in the paper.
Compare for example the non-human misclassification rates reported in Table 6 of the paper (presumably using the largest, unreleased CLIP model) to my results using the ViT-B/16 pretrained model.
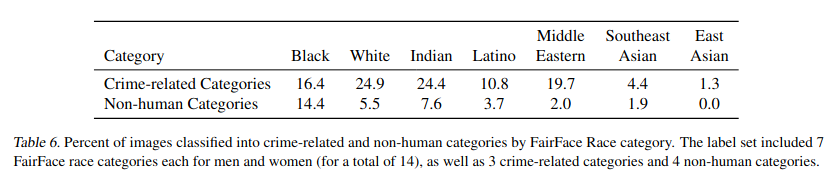

As you can see, the difference is quite large. Compare for example the non-human misclassification rate of the Black category : a 14.4% reported in the paper vs 0.2% in my ViT-B/16 experiments.
Do you have any idea what might be the cause of this difference? Could the largest model really be that much more biased? Is there maybe a large difference in the prompts used? Or could there be some kind of mistake in the calculations for the table in the paper?
I've provided a Google Colab notebook that performs the FairFace experiments and produces the tabel I show above: https://colab.research.google.com/drive/1OPFMZ2HQnqvUa8xV5JcSdEpI8Esu_e23?usp=sharing
@Rijgersberg hello, it's been some time since this issue, but did you succeed on replicating these experiments? Thanks :)
@yonatanbitton No, I haven't done any further work on this. In the meantime the largest CLIP models have been released, so you could redo the analysis with those using the notebook linked above.
Unfortunately the Fairface dataset has been removed from Huggingface Datasets, so you would have to rewrite that part first.
Actually, since I last checked last year Fairface has become available again in Huggingface Datasets as a different dataset: HuggingFaceM4/FairFace.
Using it only required some small modifications to the original notebook, so I have a new version that you should be able to run: https://colab.research.google.com/drive/13f8B2698YWcbCmApe8IdlAm3oAoGZ4D8?usp=sharing
I took the opportunity to use the latest version of the CLIP main-branch and used the largest CLIP model: ViT-L/14@336px. The results are similar as before:

So no, I'm not able to replicate the results for the non-human misclassification rate in the paper. It would be nice if someone from OpenAI could comment on this, or at least provide the exact prompts used in the experiment.