Unable to load some lamma.cpp models
Describe the bug
Some models load fine and work with llama.cpp as well however some models load in llamma.cpp but not in text-gen-webui. I get the following error. Note both models only have 2 files in their respective model directory a bin file and a readme.
===================================BUG REPORT=================================== Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
CUDA SETUP: Required library version not found: libsbitsandbytes_cpu.so. Maybe you need to compile it from source?
CUDA SETUP: Defaulting to libbitsandbytes_cpu.so...
/home/user/miniconda3/envs/textgen/lib/python3.10/site-packages/bitsandbytes/cextension.py:31: UserWarning: The installed version of bitsandbytes was compiled without GPU support. 8-bit optimizers and GPU quantization are unavailable.
warn("The installed version of bitsandbytes was compiled without GPU support. "
Loading eachadea_ggml-gpt4-x-alpaca-13b-native-4bit...
Traceback (most recent call last):
File "/home/user/text-generation-webui/server.py", line 276, in
Is there an existing issue for this?
- [X] I have searched the existing issues
Reproduction
Try running a converted gpt4all model to run in llama.cpp, test that it runs in llama.cpp. Try running the model in text-gen-webui.
Screenshot
No response
Logs
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
CUDA SETUP: Required library version not found: libsbitsandbytes_cpu.so. Maybe you need to compile it from source?
CUDA SETUP: Defaulting to libbitsandbytes_cpu.so...
/home/user/miniconda3/envs/textgen/lib/python3.10/site-packages/bitsandbytes/cextension.py:31: UserWarning: The installed version of bitsandbytes was compiled without GPU support. 8-bit optimizers and GPU quantization are unavailable.
warn("The installed version of bitsandbytes was compiled without GPU support. "
Loading eachadea_ggml-gpt4-x-alpaca-13b-native-4bit...
Traceback (most recent call last):
File "/home/user/text-generation-webui/server.py", line 276, in <module>
shared.model, shared.tokenizer = load_model(shared.model_name)
File "/home/user/text-generation-webui/modules/models.py", line 50, in load_model
model = AutoModelForCausalLM.from_pretrained(Path(f"{shared.args.model_dir}/{shared.model_name}"), device_map='auto', load_in_8bit=True)
File "/home/user/miniconda3/envs/textgen/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 441, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/home/user/miniconda3/envs/textgen/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 908, in from_pretrained
config_dict, unused_kwargs = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/user/miniconda3/envs/textgen/lib/python3.10/site-packages/transformers/configuration_utils.py", line 573, in get_config_dict
config_dict, kwargs = cls._get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/user/miniconda3/envs/textgen/lib/python3.10/site-packages/transformers/configuration_utils.py", line 628, in _get_config_dict
resolved_config_file = cached_file(
File "/home/user/miniconda3/envs/textgen/lib/python3.10/site-packages/transformers/utils/hub.py", line 380, in cached_file
raise EnvironmentError(
OSError: models/eachadea_ggml-gpt4-x-alpaca-13b-native-4bit does not appear to have a file named config.json. Checkout 'https://huggingface.co/models/eachadea_ggml-gpt4-x-alpaca-13b-native-4bit/None' for available files.
System Info
8 vcpu 16 gb system ram, ubuntu 20.04
Ahh I did not know, that seems to do the trick, thanks. Also I am running into an issue where the ai will reply once but the second question I ask it spikes the cpu usage for a minute then stops, no errors even. I have to do some more testing to get a full bug report for it.
@oobabooga I tried around 4-5 different ggml models that loaded yday/day before, but now it's stuck here
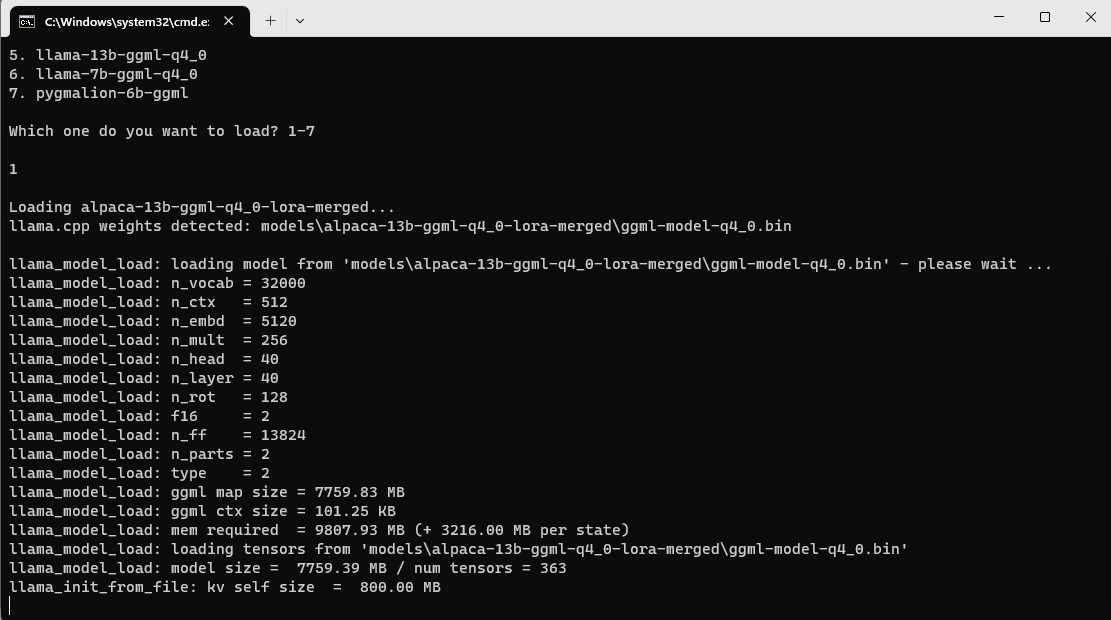
Did I do something wrong or something changed? Also any news about context size/crashes for ggml stuff?
I have just tested with llama-7b that I converted myself to ggml-model-q4_0.bin and it worked normally. We are waiting for an update to llamacpp-python, I see that that are some new commits by @thomasantony but no new version has been released yet
For most ggml-model on the net, it was complained by "too old" need to re-convert it, but I always failed to do the convertion. Any alpaca model in huggingface that will work out of the box? Thanks.
I tried launching webui today and running a ggml model and it says "no module named llama_cpp"
Tried deleting everything and rerunning installer, same result. Did something change?
Loading llama-13b-ggml-q4_0...
Traceback (most recent call last):
File "D:\textgen\oobabooga-windows\text-generation-webui\server.py", line 308, in <module>
shared.model, shared.tokenizer = load_model(shared.model_name)
File "D:\textgen\oobabooga-windows\text-generation-webui\modules\models.py", line 106, in load_model
from modules.llamacpp_model_alternative import LlamaCppModel
File "D:\textgen\oobabooga-windows\text-generation-webui\modules\llamacpp_model_alternative.py", line 9, in <module>
from llama_cpp import Llama
ModuleNotFoundError: No module named 'llama_cpp'
Try this
pip install llama-cpp-python==0.1.23
I'm trying an alternative python library. It was left out of the requirements.txt because at the moment it requires visual studio to be installed on Windows for the pip command to work
https://github.com/oobabooga/text-generation-webui/wiki/llama.cpp-models#using-llamacpp-in-the-web-ui
Thanks.
How should I make the webui see that it's installed?
Collecting llama-cpp-python==0.1.23
Using cached llama_cpp_python-0.1.23.tar.gz (530 kB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.toml) ... done
Collecting typing-extensions>=4.5.0
Using cached typing_extensions-4.5.0-py3-none-any.whl (27 kB)
Building wheels for collected packages: llama-cpp-python
Building wheel for llama-cpp-python (pyproject.toml) ... done
Created wheel for llama-cpp-python: filename=llama_cpp_python-0.1.23-cp310-cp310-win_amd64.whl size=119422 sha256=9c0bfab2a95d9b4618c622c6ce1b5415ca7d442f021fbe550eeccff9f89f37bd
Stored in directory: c:\users\imi\appdata\local\pip\cache\wheels\0c\9d\13\32ea975731a542916c4f6fe614eb89cd0a951a1b68276033f7
Successfully built llama-cpp-python
Installing collected packages: typing-extensions, llama-cpp-python
Attempting uninstall: typing-extensions
Found existing installation: typing_extensions 4.4.0
Uninstalling typing_extensions-4.4.0:
Successfully uninstalled typing_extensions-4.4.0
Successfully installed llama-cpp-python-0.1.23 typing-extensions-4.5.0

Ok to close this issue since llama.cpp no longer supports GGML, and the problematic model no longer exists on HF?