hanzi
 hanzi copied to clipboard
hanzi copied to clipboard
HanziJS is a Chinese character and NLP module for Chinese language processing for Node.js

* [SUBTLEX-CH: Chinese Word and Character Frequencies Based on Film Subtitles](https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0010729) Arguably better quality for teaching than Junda written corpora. See also #52
Do you maintain or know of a similar tool for Japanese, and/or Korean?
Add the possibility to get wubi codes for a characters sequence. Add the possibility to get pinyin in utf8 with accent rather that ascii with tone digit code.
C:\Users\yangh>var hanzi = require("hanzi"); 'var' is not recognized as an internal or external command, operable program or batch file. I successfully installed node and npm, but I am having trouble...
For my purposes, I needed a more exact lookup functionality. For example: `console.log(hanzi.dictionarySearch('小孩', 'only'))` gave 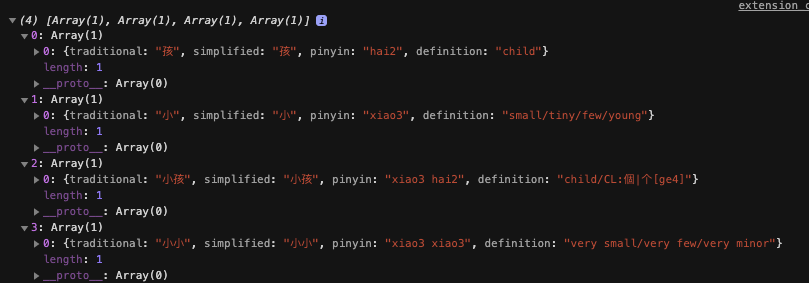 `console.log(hanzi.dictionarySearch('小孩'))` gave  But now this `console.log(hanzi.dictionarySearch('小孩', 'exact'))` gives 
How hard would it be to add pinyin lookup? Ex: get all exact matches for "xia4 xue3", ordered by frequency?
It seems that there are several characters over at HanziCraft that do not have any High Frequency words, but only Medium Frequency words. For example, the page for [幌](http://www.hanzicraft.com/character/%E5%B9%8C) states...
``` > hanzi.getPinyin('只') [ 'zhi1' ] ``` but there are actually several matches in the dictionary
Just found this repo and I'm really loving it. However, I landed on hanzijs.com first and the site appears to be down at the moment. FYI in case it's not...