Is Deepsparse specially optimized for certain model architectures regardless of the sparsity?
Hi there,
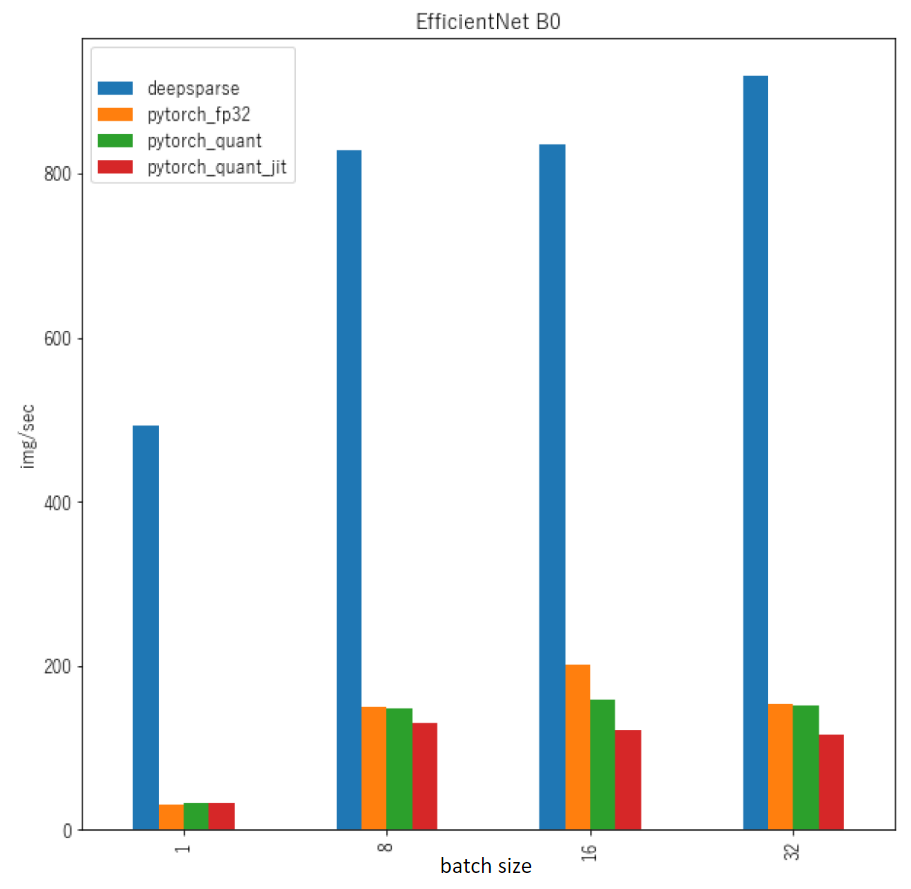
I have been experimenting with the DeepSparse engine, and this is my second issue. I thought initially that DeepSparse engine is a general engine designed to exploit the sparsity in a model to achieve faster inference speed. However, recently I discovered that regardless of the sparsity of the model, model's architecture seems to play a bigger role in the final inference speed achieved by the DeepSparse engine. For example, when I compared the Resnet models' inference speed with and without the DeepSparse engine (all models having zero sparsity) , the inference speed using the DeepSparse engine is much faster despite the zero sparsity. This is the same with the EfficientNet models and the MobileNet models. But, the previously described behavior is not observed in networks like ResNext, SeResNext, ViT, etc. I have a feeling that when using DeepSparse engine, pruning/ high model's sparsity plays a secondary role, and the main reason for the speed up is the model's architecture.
May I know what is the view of the NeuralMagic team about the observation/ opinion above regarding the DeepSparse engine?
Thank you.
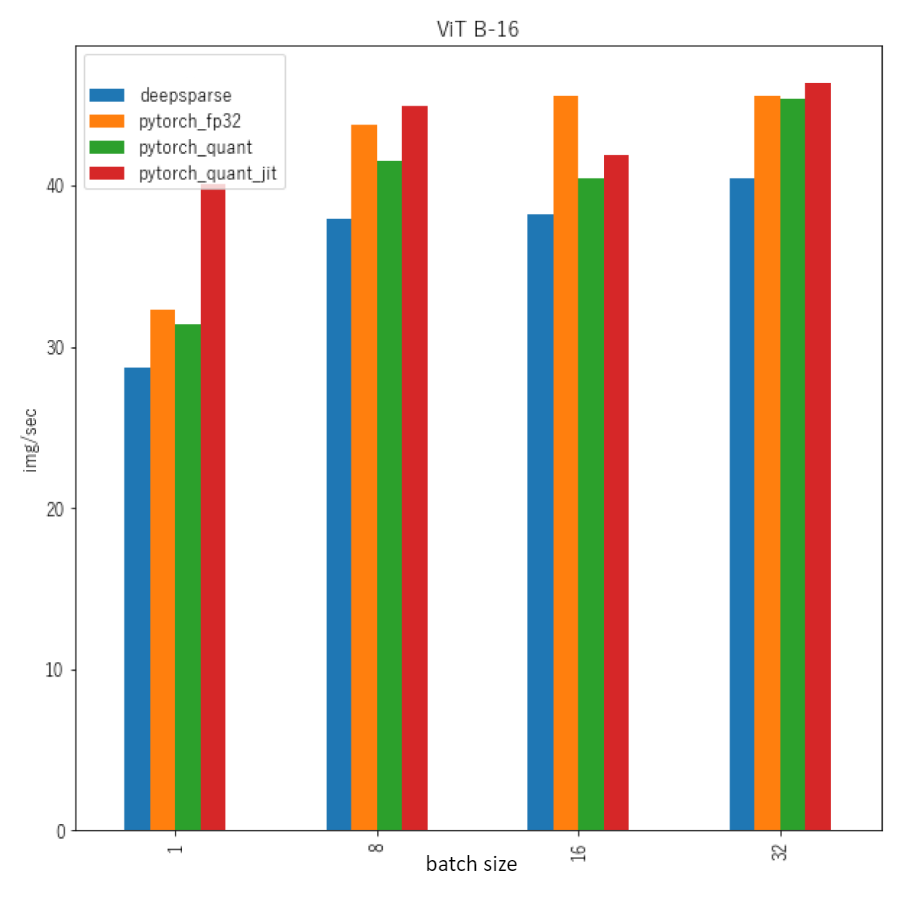
Hi @jz-exwzd, we do optimize for performance for known architectures. We have not had a chance to support the group convolutions in ResNext and SEResNext yet, unfortunately, so any models containing those are not going to be very performant. ViT should be fairly well supported, though, for performance speedup. Do you have an example ONNX for that one we can take a look at to figure out more?
For the MobileNet and EfficientNet models, we have optimized for depthwise convolutions which is why these see better speedup. EfficientNets don't lend themselves well to speed up from sparsity currently because they're very memory bound. MobileNet v1 does, however, for pruning the 1x1 convs. MobileNet v2 and above will be largely memory-bound like EfficientNet.
Hi @markurtz,
Thank you for your detailed replies. Glad that my observations were not wrong. That explains why some models perform better with the DeepSparse engine even without any sparsity. About the memory-bound issue, basically the memory-bound behavior becomes the bottleneck to the performance?
About the ViT, it is just the onnx format of the checkpoint from the Timm libraries. More specifically, in the examples I showed below, it was the ViT B-16 with input size 224x224. As you can notice in the case of the EfficientNet, the throughput of the DeepSparse engine is significantly higher than all the other variants of the model, while this is not the case with the ViT as can be seen in the second image. I wonder if this is expected?
Hi! Good discussion, thank you that!
And is there a place where we can check the supported layer types?
@markurtz Hi, may I ask, where is the optimized inference code? I mean, you have customized quantization op, how do u inference it? onnxruntime doesn't support such spec.
Hi @jinfagang, the optimized inference code is kept closed source, so unfortunately not available. For the quantization op, we do support the ONNX standard specs for QLinearConv, QLinearMatMul, and QuantizeLinear, and these are what the DeepSparse inference engine expects for quantized inputs. For these, we expect the quantized inputs to be static rather than dynamic, which is what ONNXRuntime typically optimizes support for. Let me know if you have any further questions there!
Hi @rafafael03, we don't currently have that public for the list of supported layer types, but we will update docs for this soon! For now, you can run the DeepSparse engine, and while it's compiling, it will print out the percentage of the graph supported to give a quick sense of whether the model is supported. Additionally, we'll have a new analyze API coming out on nightly/with the 1.6 release to enable this clearly and give more detailed information.
Hope the detail was helpful! Feel free to re-open if you have further questions, thanks