data.table implementation
directory sandbox currently contains a bin_data implementation using data.table.
For discussion, my suggestion is that this would be the standard implementation and that change the ffbase dependency into a Suggest, so that it is still possible to use extremely large data files without resorting to ff/ffbase. @mtennekes any thoughts?
Thanks @edwindj ! Make sense.
I image three variants on how to set the engine:
- Use an argument in
tableplot, e.g.use_ff. - Use a global option.
- Use
data.tableif the data frame is smaller than some size-treshhold, and otherwise useff.
Which do you prefer? (ping @cfholbert, @RobertSellers, @sfd99)
Just started the data.table implementation in the datatable branch, using option 1 (use_ff argument) for now. However, it doesn't work yet. bin_data expects a prepared object, but bin_data_dt (as I renamed it) expects a dataframe/table. Even with p <- p$data I got a strange looking tableplot:
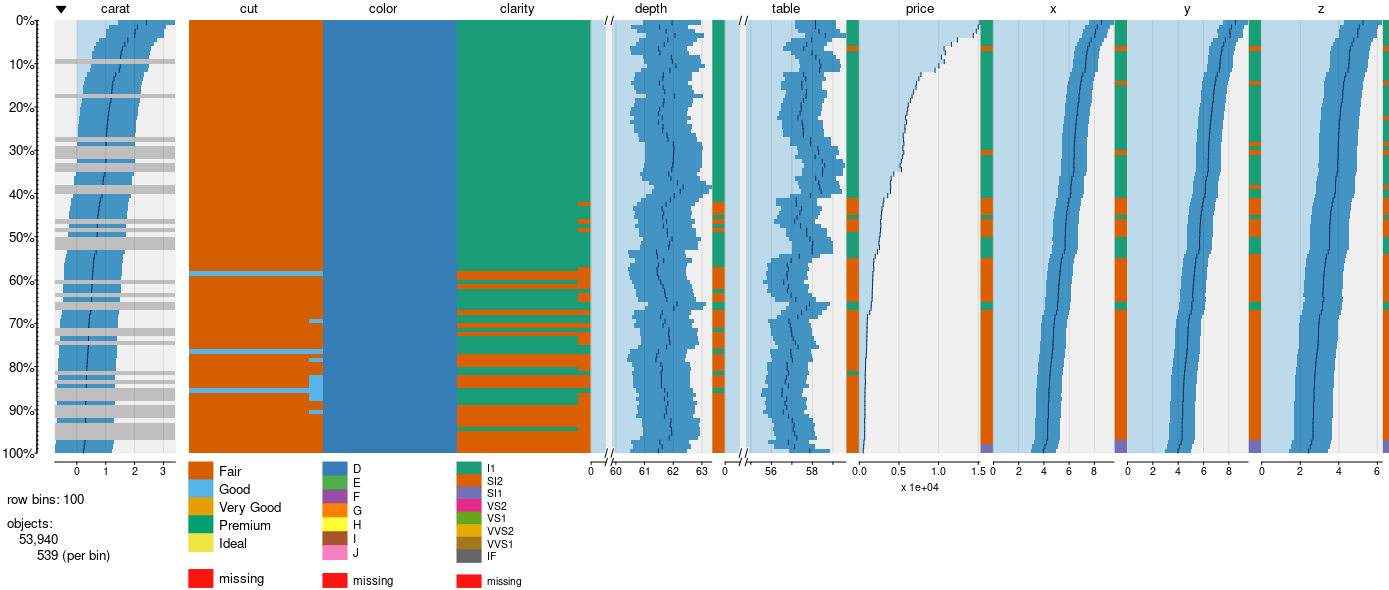
If we are going to use data.table and move ff, bit and ffbase into suggests, then we'll have to re-implement (or skip) tableprepare, and re-implenent bin_hcc_data as well.
Unfortunately, I have almost no time to do this myself this year (even though it shouldn't take much time).
Yeah, we would need to skip tablePrepare for the data.table implementation.
Alternative approach:
- when the tableplot function is called with a data.frame/data.table we use the data.table implementation (because appearantly the data fits into memory...
- when the tableplot function is called with a ff (or csv file), then we use the ff implementation.
I suspect it might be less work than you think because the ff code is mostly separated from the rest. I will give it a try next week in branch data.table?