WIP Mne eyetrack revisions [ci skip][skip azp][skip actions]
refactored code initially pushed in PR #10855 by @dominikwelke and reviewed by @larsoner and @drammock. Starting a new PR as suggested by @larsoner
briefly: When plotting the test_eyelink.asc file, The eye channel traces now appear at the beginning of the time series as expected. I also added a dataframes attribute to the RawEyelink class, which returns the pandas dataframes that are created while loading the file.
@dominikwelke I'll leave some comments on the code in your PR to explain some of the changes I made in the code refactoring, and you can let me know if you agree, and we can discuss what needs to be worked on next!
@sportnoah14 also cc'ing you here so that you can stay in the loop.
@scott-huberty looks like this needs a rebase or a merge-main. If it were me, I'd probably
git rebase -i 4a390cc^
and then change pick to s (or squash) for all the commits @dominikwelke did. That way you're only applying 3 commits on top of current main instead of 27 so resolving the merge conflicts might go much more smoothly.
git rebase -i 4a390cc^
Thanks @drammock - I think I did that correctly.. I had to force push because my local branch was behind remote after rebasing.
I think I did that correctly.. I had to force push because my local branch was behind remote after rebasing.
Force-push is expected here (you have now 2 commits where GitHub had 27), and the monster multiline commit message for 5efcf53 suggests that you did it correctly... except that this was only the first step. Now you have to fetch upstream main and then git rebase upstream/main, to then actually fix the merge conflicts.
I think I did that correctly.. I had to force push because my local branch was behind remote after rebasing.
Force-push is expected here (you have now 2 commits where GitHub had 27), and the monster multiline commit message for 5efcf53 suggests that you did it correctly... except that this was only the first step. Now you have to fetch upstream main and then
git rebase upstream/main, to then actually fix the merge conflicts.
Sorry for the delay - While doing git rebase upstream/main I needed to manually resolve conflicts that couldn't be merged, it was the first time I've done this but I hopefully did it correctly.
hi @scott-huberty i think ill finally find some time to work on this again, while working on pupil-size data.. what is the status on your branch?
i saw you did quite some reorganisation of the eyelink parser code.. generally ok with me, i am not bound to my initial layout yet, maybe worksplitting makes sense to avoid double structures? i am currently working with data that has already been synchronized with EEG, so i can focus on basic integration (e.g. the ch_types FIFF stuff) and (pre)processing after having it loaded, while you further work on the parser?
what do you think?
@dominikwelke I think this is a great idea!
I should wrap up the code for the parser next week. Then I can start advancing the test-suite that you started.
I can also create a new local branch and cherry-pick your recent commits to make sure the parser code remains compatible with the development on channel types etc you are doing right now.
I'll follow up with you next week when the parser code is finalized, and maybe we can start to merge our work then.
Hey @dominikwelke , I think the parser is looking good!

I haven't really touched your code on setting channel and FIFF types, but I see you did some refactoring of that last week. So I will try to pull your recent commits to a copy of this branch.
On that note, this Parser should be robust to reading all the various eyelink channel types that can be present in an eyelink file (Gaze, Pupil, Resolution, Velocity, Head target (remote mode), and DINS). But, I'm not sure what coils/units etc we should give these channels, what do you think?
I've started a github repo that contains various eyelink files that I've been using to test code during development, including monocular files and files with resolution/head target/DIN channels. Feel free to check it out.
One comment on the DIN (digital input port) data in Eyelink files.. Eyelink tracks the pin downs/ups of a DIN port for every sample of the file, so if I'm not mistaken, I think that we could load this data in as a stim channel. In my lab, we are sending info to the eyelink host PC's DIN port, and get integer values between 0-3 in our files (0 being pin down, and 1,2, or 3 depending on what pin is up).

One comment on the DIN (digital input port) data in Eyelink files.. Eyelink tracks the pin downs/ups of a DIN port for every sample of the file, so if I'm not mistaken, I think that we could load this data in as a
stimchannel.
Following up on that, if we read in the DIN data as a stim channel, this is an example of what it would look like.
for this example file, a photodiode was connected to Eyelinks DIN port. This is a pupillary light reflex task, so a white flash on the screen triggers the photodiode (and thus a change in the pins of the DIN port). This is why, in this file, just after the DIN value changes at around 2-seconds, you see the pupil size constrict (in the pupil channel).

nice, great progress @scott-huberty ! i'll test it with some of my files soon and give feedback.
immediate comments:
- my initial parser function was based on an already existing project. if you kept any of it, we should acknowledge the author (and the copyright note, as it's MIT licensed)
this Parser should be robust to reading all the various eyelink channel types that can be present in an eyelink file (Gaze, Pupil, Resolution, Velocity, Head target (remote mode), and DINS). But, I'm not sure what coils/units etc we should give these channels, what do you think?
- treating DINS as stim channel makes sense, imo.
- for the other channel types:
we can define new coil types, if needed.
but what do you think is the priority of it? do ppl actually use these data?
i think setting specific channel info makes sense IF there will be methods for these data types. otherwise we can simply give them the
miscchannel type and leave it to the users to treat the data as wanted. an alternative/addition could be anot implementedwarning
how should we proceed? (also @drammock @larsoner )
if you want @scott-huberty - and your work on the parser is more or less done - i can deal with the integration of our branches.
i would do so by merging your branch into mine, as the associated PR has had a bit more public discussion than yours here.
of course your branch can stay active and news can be merged again down the line
treating DINS as stim channel makes sense, imo.
Agreed
for the other channel types: we can define new coil types, if needed. [...] otherwise we can simply give them the
miscchannel type
misc makes sense to me unless there is a compelling reason to add a more specific channel type
treating DINS as stim channel makes sense, imo.
Agreed
for the other channel types: we can define new coil types, if needed. [...] otherwise we can simply give them the
miscchannel type
miscmakes sense to me unless there is a compelling reason to add a more specific channel type
Ok, let's start with misc, I can look at some test files after to make sure everything looks okay.
- my initial parser function was based on an already existing project. if you kept any of it, we should acknowledge the author (and the copyright note, as it's MIT licensed)
The code from that project isn't in this branch anymore. The code in this branch I developed along with @christian-oreilly , (who I've listed as a 3rd contributor in the eyelink.py file). The code you wrote for initializing the RawEyelink class, creating the channel/coil types, starting the test-suite etc. is in this branch too.
how should we proceed? (also @drammock @larsoner ) if you want @scott-huberty - and your work on the parser is more or less done - i can deal with the integration of our branches. i would do so by merging your branch into mine, as the associated PR has had a bit more public discussion than yours here. of course your branch can stay active and news can be merged again down the line
What do you think about the idea of finishing up this PR (basically wrapping up setting the channel types as discussed, and completing the test-suite and docs), which won't include the preprocessing functions that you've been working on in your branch. Then, assuming the PR is approved, you could merge main from your branch and carry forward the preprocessing functions in a second PR (the one currently open). IMO, this might create a nice "separation of concerns" as far as testing, documenting, and reviewing read_raw_eyelink and the additional preprocessing functions. If so, you could pull this branch now and make your own commits to it too, which we could merge into the PR.
Alternatively, yes we could merge this into your branch, and continue working on it from there. In that case, there's a small amount of refactoring I wanted to do, but I can do it before or after the merge. just let me know what you're thoughts are! (Others please feel free to weigh in on this too if you don't like my proposed idea).
What do you think about the idea of finishing up this PR (basically wrapping up setting the channel types as discussed, and completing the test-suite and docs) [... and then] carry forward the preprocessing functions in a second PR
I have not read all previous responses, but I will say from a reviewer perspective ideally the I/O and preprocessing could go in separate, sequential PRs. It will make reviewing much easier for us!
i tested with some of my files and everything seems to work swiftly! thanks for moving this forward! :)
also thanks for updating me on the contributions.
even better this way!
concerning the choice of branch/PR: moving the preprocessing code from my current branch into a separate branch+pr would be a matter of seconds, as it happens in entriely different files. also no real discussion of this code has happened in the PR so far.
my further arguments for merging into my branch were:
- it would probably generate the cleaner git history (your commits stay your's of course)
- related: tbh your history of force-pushing altered commits made me a bit wary of having your branch as the "main" because this can lead to nasty git pains (of course it's necessary some times, no offense!)
- and as mentioned: the next integration steps are largely mine (fiddling with the FIFF types) and it seemed very convoluted to me to generate a copy of your branch to merge parts of my branch into, to then merge into yours again :)
but we've discussed this long enough - you have a preference yor your branch and the reviewers dont seem to care so lets take your branch :)
i'll integrate the latest status of my FIFF and channel type settings into a copy of it, and then we can merge these branches. so please, no changing of the git history in your branch from now on. just have a new commit for it if you change smth - this also makes changes more transparent and enables review :) (plus the final merge into MNE main will collapse everything to a single commit anyway.. )
Concerning the choice of branch/PR: moving the preprocessing code from my current branch into a separate branch+pr would be a matter of seconds, as it happens in entriely different files. also no real discussion of this code has happened in the PR so far.
my further arguments for merging into my branch were: [...but ] we've discussed this long enough - you have a preference yor your branch and the reviewers dont seem to care so lets take your branch :)
It's up to you - Either way, I'm just glad we've progressed to the stage that we can start working on a common branch!
so please, no changing of the git history in your branch from now on.
Perhaps I made a faulty assumption that no one had fetched this remote branch - of course, we'll keep the history linear from now on!
i tested with some of my files and everything seems to work swiftly!
Awesome!
Thanks for figuring out a plan and workflow @scott-huberty @dominikwelke -- feel free to clean up / modify this PR as necessary then ping me in a comment for review!
From a very quick look at the PR, it looks like there is no new entry in tutorials/io or `tutorials/preprocessing' -- maybe add one to the latter that just shows you can read some data, epoch it, and make an average of some sort (e.g., of pupil size)? Even if really messy because the preprocessing functions are missing it's a good place to see that at least some things are working as expected. Then we can build the tutorial up as standard methods are added
... probably not terribly useful, but in case you want some inspirition here is a tutorial I made ages ago for the defunct pyeparse
https://github.com/pyeparse/pyeparse/blob/master/examples/plot_from_raw_to_epochs.py
maybe add one to the latter that just shows you can read some data, epoch it, and make an average of some sort (e.g., of pupil size)? Even if really messy because the preprocessing functions are missing it's a good place to see that at least some things are working as expected. Then we can build the tutorial up as standard methods are added
Thanks @larsoner ! Will do. I also saw some pydocstyle/docstring errors too, I'll look at them tomorrow.
@dominikwelke I merged your PR on the work you did with the FIFF types - I'm going to give it a closer look tomorrow and may have some suggestions if that's okay with you.
FYI I think you have push privileges on this branch now. I'm okay with you pushing directly here, I think we will be able to manage : )
Thanks again @dominikwelke for merging in your updates - I can tell that you put a lot of work into this!
As I understand it, to create the info object and set the channel types/coil types/units etc, the code is broken down into these steps:
1. Create a list of channel names
2. Create a list of channel types
3. Create an mne.Info object using mne.create_info
4. Iterate over each dict in info['chs'], and specify the coil_types, units etc.
I find this to be a bit complicated because I think some mistakes are being made in step 2 and step 3 and so we are spending a lot of time in step 4 correcting things
- In step 2, all the channels are given the type
'eyetrack', even if it is not an eyetracking channel (the'DIN'channel should be astimtype):
https://github.com/mne-tools/mne-python/blob/b5ca7f97c968486ca7df059308bcf9f93d06044d/mne/io/eyetracking/eyelink.py#L590
- Even for the channels that are rightly
'eyetrack'channels, in step 3mne.create_infodoes not correctly set the'unit', 'coil_type, and'loc'keys in theinfo['chs']dictto what we want them to be.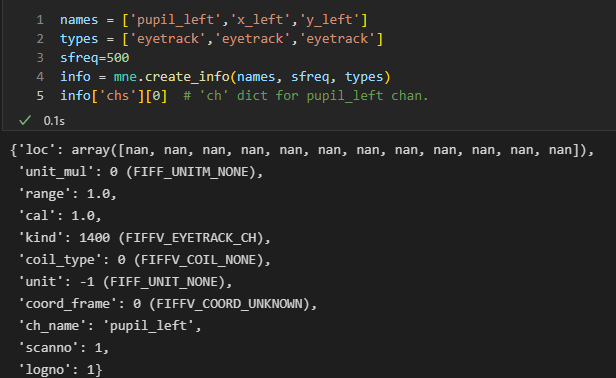
Take the example above. From what I understand of the code, we actually want
-
Pupil channels to have a
'coil_type'ofFIFF.FIFFV_COIL_EYETRACK_PUPILand aunitofFIFF.FIFF_UNIT_MM, -
xpos/ypos channels we want a
'coil_type'ofFIFF.FIFFV_COIL_EYETRACK_POSand aunitofFIFF.FIFF_UNIT_PX -
Thus in step 4, we spend this whole block of code iterating over the
info['chs']dict, correcting the values that weren't set correctly before: https://github.com/mne-tools/mne-python/blob/b5ca7f97c968486ca7df059308bcf9f93d06044d/mne/io/eyetracking/utils.py#L117-L200
Can't we amend mne.io.pick.get_constants, to split eyetrack into two types, (something like eyetracking_pupil, eyetracking_pos), setting the coil_types, units etc. accordingly, so that mne.create_info, will return the info correctly? : ) It looks like this is what is done for fnirs channels, so we could follow a similar approach.
https://github.com/mne-tools/mne-python/blob/b5ca7f97c968486ca7df059308bcf9f93d06044d/mne/io/pick.py#L18-L104
I think this would make things much simpler for us!!!
Thanks again for starting all that work! I'm sure it was a big undertaking.
FYI I think you have push privileges on this branch now. I'm okay with you pushing directly here, I think we will be able to manage : )
yup, i accepted the invitation but my pushs were still rejected. hope i can solve this for subsequent commits.
find this to be a bit complicated ... we are spending a lot of time in step 4 correcting things
i totally agree! the complexity here comes from the necessity to chose between different channel/coil types (position/pupil/...) based on suboptimal information (channel name).
..and there are different possible units for the coil types:
px, deg, mm(?) for position, and au or mm for pupil
but thats less of a problem..
Can't we amend mne.io.pick.get_constants, to split eyetrack into two types, (something like eyetracking_pupil, eyetracking_pos)
yes, this would be my suggestion to reduce the complexity too. and this actually bothered me for a while :) i didnt do that in the initial design because of the drafting/discussions during the code-sprint and (of course) because i wasnt fully aware of the consequences and the details of the fiff handling. then it stuck.
yet it makes total sense to have different channel_types for different channel types and separating them on the highest implementation level will also be useful as preprocessing and analysis methods will (at least partly) differ.
i will change this today, its not much work
yup, i accepted the invitation but my pushs were still rejected. hope i can solve this for subsequent commits [...] i will change this today, its not much work
I think the issue was on my end. I changed this branch's settings so let me know if you still have the issue when you try to push your commits today.
..and there are different possible
units for the coil types:px,deg,mm(?) for position, andauormmfor pupil but thats less of a problem..
As I understand, mne.io.pick.get_constants typically sets a single kind, coil_type, and unit based off the channel_type, so we should probably choose the coil_type/unit that are most commonly reported for the channel_type across systems (eyelink/Tobii). I think that would be pixels for eye-position and arbitary units for Pupil.
yet it makes total sense to have different
channel_types for different channel types and separating them on the highest implementation level
Agreed! eye-position and pupil data are not on the same scale, and they are commonly reported across eyetracking systems (so If that Tobii I/O ever gets picked back up, they would likely utilize the pupil/pos channel_type's too), so it makes sense to me to have two eyetracking channel types. As for the other channels that eyelink can output (velocity etc.), we can just set the channel_type to misc as discussed above.
Thanks!
pushing worked now, thanks!
i now implemented it as discussed, and yes - defaults can be defined and i set them to be px for eyetrack_pos and mm for eyetrack_pupil (though i guess most eyetrackers probably spit out AU - anyway, that's minor)
edit: just saw that you said the same thing :) i can change the pupil default from mm back to None/AU in the next commit
out of the box the reader now guesses eye and x/y axis (and
unit, but thats usually not there) from the ch_name and puts NaN otherwise. this should be fine for the start and most cases, but i kept the more flexible setting function in utils because it might be needed down the line (e.g. for anaylses requiring binocular recordings)
read_raw_eyelink gives misc type to everything it doesnt recognize as pos/pupil/stim.
some other reader functions (e.g. the eeg ones) have input arguments to specify channels with certain types (misc/eog...) we could include smth like this here as well, though i am not sure it is too important. what do you think?
some other reader functions (e.g. the eeg ones) have input arguments to specify channels with certain types (misc/eog...) we could include smth like this here as well, though i am not sure it is too important. what do you think?
If you mean that this could allow a user to set a channel that currently will be be set as a misc type (velocity, head-distance channel from an eyelink file), to the eyetrack_pos/eyetrack_pupil type, I suppose we could do that, if the scalings of those channels are comparable with the defaults in eyetrack_pos/eyetrack_pupil? I also don't have a strong opinion about it at the moment.
I also don't have a strong opinion about it at the moment.
ok, then lets not do it for now. if the reviewers think it makes sense, it can be added later.
... probably not terribly useful, but in case you want some inspirition here is a tutorial I made ages ago for the defunct
pyeparsehttps://github.com/pyeparse/pyeparse/blob/master/examples/plot_from_raw_to_epochs.py
Also @dominikwelke do you have any interest in spearheading the sphinx documentation for this PR (per @larsoner 's suggestion a few threads above)? If I'm not mistaken you've done more work on docs with MNE than I have.
If so, I can start working on the pytest suite for this PR while you work on that. Of course if you don't have time to work on the docs feel free to let me know too.
Also @dominikwelke do you have any interest in spearheading the sphinx documentation for this PR (per @larsoner 's suggestion a few threads above)? If I'm not mistaken you've done more work on docs with MNE than I have.
alright, i'll start with that.
looks like your renaming removed all the git history of the files (deleting file -> creating new file with all new code without history)
if you use git mv instead of renaming in the file explorer the history is kept (see e.g. https://stackoverflow.com/questions/2641146/handling-file-renames-in-git)
looks like your renaming removed all the git history of the files (deleting file -> creating new file with all new code without history)
if you use
git mvinstead of renaming in the file explorer the history is kept (see e.g. https://stackoverflow.com/questions/2641146/handling-file-renames-in-git)
Sorry just saw this.. Thanks for that tip - I didn't know that!
Shall I roll back my head to b6e5a5b and redo this as you suggested?
We will squash+merge when merging anyway, which will destroy any history of mv or whatever. In the end all lines will look like they were committed by a single person (@scott-huberty as author of the PR) with co-author credit to @dominikwelke . So I wouldn't bother with rolling back and doing git mv unless it's important for you to have git blame to work on your branch for the next few days / weeks / whatever until we merge...
We will squash+merge when merging anyway, which will destroy any history of
mvor whatever. In the end all lines will look like they were committed by a single person (@scott-huberty as author of the PR) with co-author credit to @dominikwelke . So I wouldn't bother with rolling back and doinggit mvunless it's important for you to havegit blameto work on your branch for the next few days / weeks / whatever until we merge...
Ok, thanks for clarifying @larsoner
@dominikwelke is that okay with you?