I got a crash when i trainning with this code.
I got a crash when I trainned with this code. Maybe something wrong that I did. Did anyone also get this problem? Thanks!
crash position: File "FastSpeech2_Ming\model\modules.py", line 126, in forward x = x + pitch_embedding RuntimeError: The size of tensor a (48) must match the size of tensor b (57) at non-singleton dimension 1
where x.shape = torch.Size([80, 48, 256]), and pitch_embedding.shape = torch.Size([80, 57, 256])
What dataset are you using? You should check your MFA process and make sure you got the right TextGrid files.
hello I have the same problem I use biaobei PhoneLabeling/0000X.interval change it as 0000X.TextGrid Then I run train.py show a problem x = x + pitch_embedding RuntimeError: The size of tensor a (52) must match the size of tensor b (56) at non-singleton dimension 1
hello I have the same problem I use biaobei PhoneLabeling/0000X.interval change it as 0000X.TextGrid Then I run train.py show a problem x = x + pitch_embedding RuntimeError: The size of tensor a (52) must match the size of tensor b (56) at non-singleton dimension 1
Do not use the interval files from Biaobei. I believe some alignments from Biaobei dataset are not correct. You should use MFA to generate TextGrid files.
hello I have the same problem I use biaobei PhoneLabeling/0000X.interval change it as 0000X.TextGrid Then I run train.py show a problem x = x + pitch_embedding RuntimeError: The size of tensor a (52) must match the size of tensor b (56) at non-singleton dimension 1
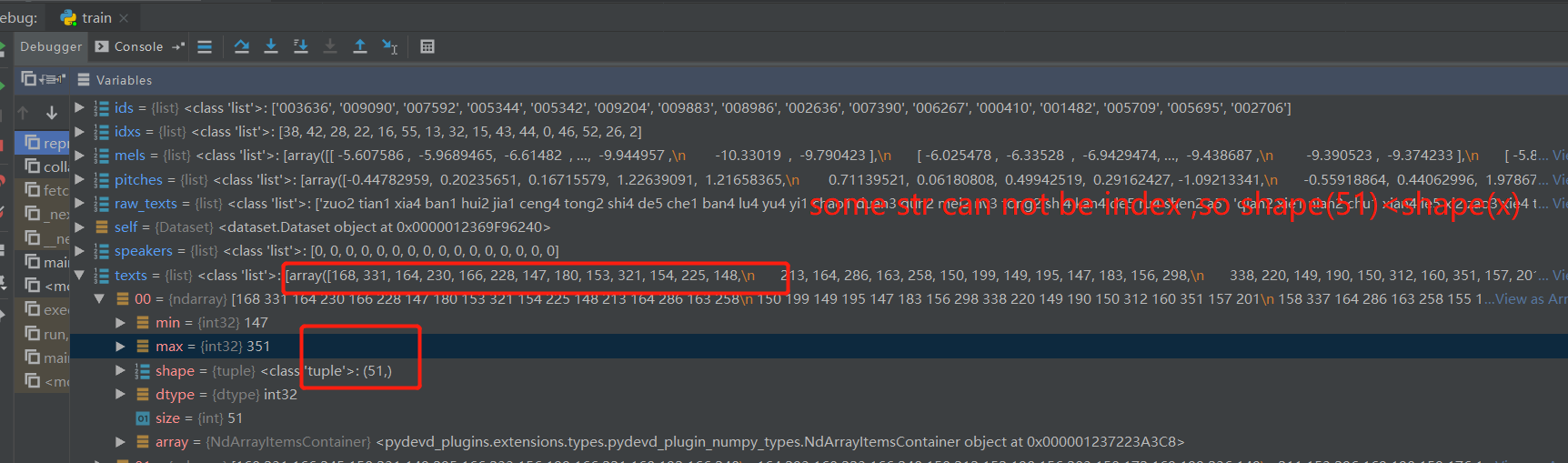 I think that text_to_sequence function like the picture cause the problem
some text like 'er' can not be index so pitch(51)>text(49)
I think that text_to_sequence function like the picture cause the problem
some text like 'er' can not be index so pitch(51)>text(49)
make sure your symbols list in symbols.py contains all the symbols in your dataset. if you want to train on a new language, you need to add new set of symbols, similar to text/pinyin.py