Swin-Transformer

Swin-Transformer copied to clipboard
Accelerate Training/Fine-tuning for SwinTransformer
Accelerate Training for SwinTransformer
Utilize Nvidia/apex fused ops and our fused ops, based on commit id cbaa0d8.
Acceleration strategies
- apex O2
- fused_adam (
apexfused ops, to replace AdamW) - fused_layernorm (
apexfused ops, to replace nn.LayerNorm) - fused_mlp (
apexfused ops, to replace MLP module as the dropout rate is 0) - fused_dense (
apexfused ops, to replace nn.Linear) - fused_window_process (fuse window shift & partition)
- unfused_mha (fuse qk_result + relative_pos_bias + mask + softmax)
Performance
Experimental environment: single A100-80G
Throughput
Use
--throughputin the launch bash
| Code ver. | precision | batchsize | throughput |
|---|---|---|---|
Official 78cec9a |
torch.cuda.amp | 128 | 540.4141554238416 |
| This repo (O0 baseline) | O0 | 128 | 540.8349981747887 |
| This repo (+) | O0 | 128 | 567.3833912349154 |
| This repo (O2 baseline) | O2 | 128 | 1035.148253639781 |
| This repo (+) | O2 | 128 | 1164.6363324181038 |
[Note] For O0 mode, we find the fastest arguments should exclude --fused_mlp and --fused_dense in our case.
Training speed
Use time cost in the plotted logs. Average first several iterations.
| Code ver. | precision | batchsize | Time/iter | Image/second | speed-up |
|---|---|---|---|---|---|
Official 78cec9a |
torch.cuda.amp | 128 | 0.4852 | 263.82 | 1x |
| This repo (O0 baseline) | O0 | 128 | 0.8010 | 159.81 | 0.61x |
| This repo (+) | O2 | 128 | 0.3837 | 333.61 | 1.27x |
Official 78cec9a |
torch.cuda.amp | 256 | 0.9093 | 281.55 | 1x |
| This repo (+) | O2 | 256 | 0.7273 | 351.97 | 1.25x |
Accuracy check
Train from scratch
| Tag | Max acc@1 | Last acc@1 | Last acc@5 |
|---|---|---|---|
| Swin-T (official*) | 81.29 | 81.286 | 95.544 |
| Swin-T (faster) | 81.27 | 81.222 (-0.064) | 95.546 (+0.002) |
| Swin-B (official*) | 83.48 | 83.476 | 96.468 |
| Swin-B (faster) | 83.52 | 83.480 (+0.004) | 96.414 (-0.054) |
* Numbers are from official logs: Swin-T, Swin-B
Training curves
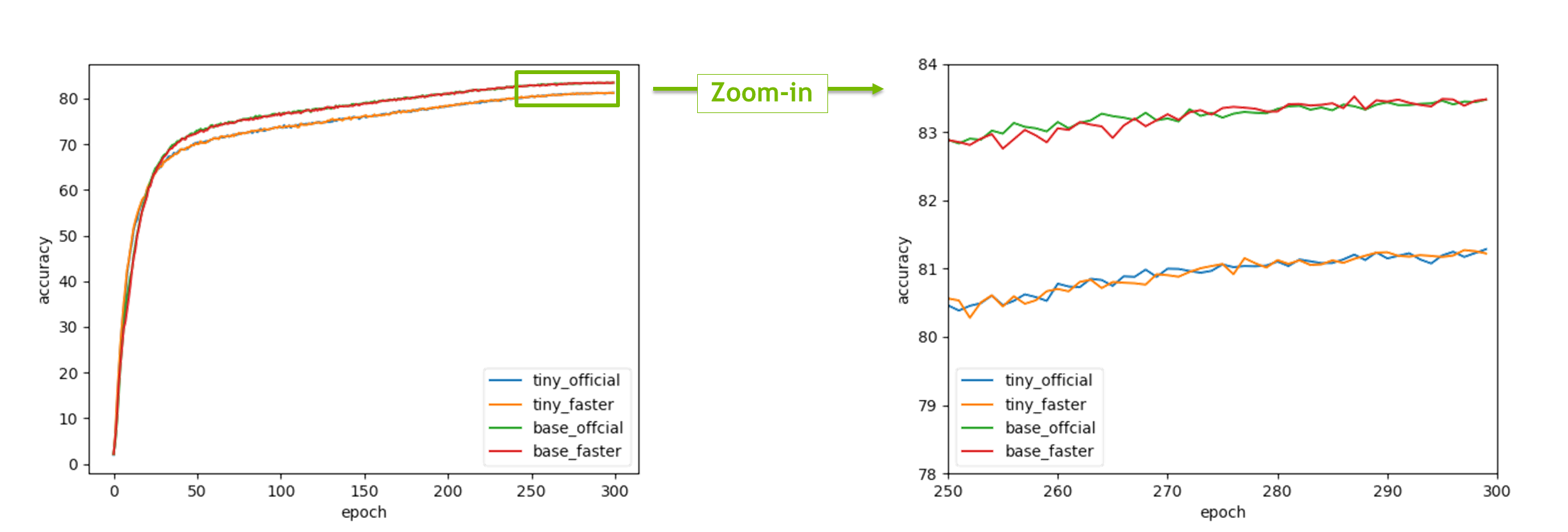
Fine-tuning
| Tag | Max acc@1 | Last acc@1 | Last acc@5 |
|---|---|---|---|
| Swin-L (official) | - | 86.3 | 97.9 |
| Swin-L (faster) | 86.16 | 86.146 | 97.856 |
Close this PR as the main branch make use of torch.cuda.amp for mixed-precision training, while this PR is based on apex O2.