训练中途loss变nan
您好!我制作了自己的数据集,一半sup,一半unsup,使用bash/tool/dist_train.sh {config} {gps_num}进行训练,config用的1080k。我在iterations=60000的时候中断过一次训练;后来为了继续训练,修改了dist_train.sh脚本,在执行train.py命令行加入了”--resum-from iter_60000.pth“。我查看了日志,从iterations60000到iterations444500训练都正常,但是从这之后,就出现了loss=nan的情况,而且在评估阶段出现“mmdet.ssod - ERROR - The testing results of the whole dataset is empty”错误,我检查了我的test数据集,也不是空的,请问这是什么原因呢?loss为nan以及datasets为empty的log截图如下:
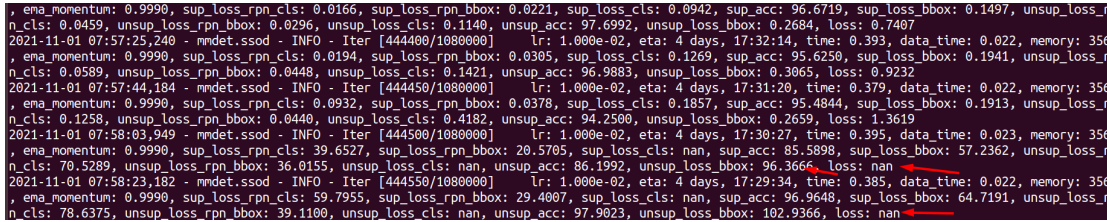 ?
?

loss变成NaN的时候网络已经崩了,所以后面才会出现测试结果为空的情况。 你可以先看看整体的loss curve是不是正常的,如果前期一直正常那么可以看看fp16的问题,你可以切换到fp32看有没有问题。 (如果用的torch<=1.6,最好切换到更高版本,因为torch<=1.6的时候fp16用的是mmdetection自己实现的版本,我之前也遇到过nan;如果没办法切换的话我可以给你一个apex版本的) 其次,你可以看看debug一下,从崩的节点附近resume,看看能不能在要崩的时候保存一下一些关键信息,看下哪些比较异常。
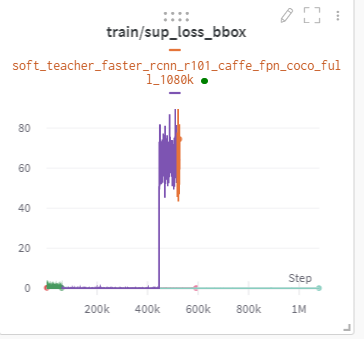 看了一下wandb的可视化结果,loss curve是不正常的。并且我用的torch1.10.0。
然后崩之前那个模型已经完美错过了,pth只保存到iter_448000.pth,好气。。。感觉要从头开始训练了,,,我之前有完成过同样配置的训练,唯一不同的是训练集增大了一倍。数据集增大感觉不太会让网络崩了。我试试看手动调整一下fp到32,从头开始训练,看看有没有问题。感谢大神的回复!
看了一下wandb的可视化结果,loss curve是不正常的。并且我用的torch1.10.0。
然后崩之前那个模型已经完美错过了,pth只保存到iter_448000.pth,好气。。。感觉要从头开始训练了,,,我之前有完成过同样配置的训练,唯一不同的是训练集增大了一倍。数据集增大感觉不太会让网络崩了。我试试看手动调整一下fp到32,从头开始训练,看看有没有问题。感谢大神的回复!
I had similar problem with loss. I received nan and the same mensage of dataset empty too. The solution for me was using bigger batch size changing workers_per_gpu like this issue: #9
I faced the same problem , I changed the batch size from 2 to 8 in this line: samples_per_gpu=8, workers_per_gpu=2,
and delete/comment the fp16 line as bellow #fp16 = dict(loss_scale="dynamic")
but unfortunately I got this error:
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 725186) of binary: /opt/conda/bin/python
can any one help me. I really don't know what is exactly the problem.
when changing the worker info to
samples_per_gpu=5, workers_per_gpu=2,
and i kept using fp16
I got another type of error which is
ERROR:torch.distributed.elastic.agent.server.local_elastic_agent:[default] Worker group failed
and i am still confused what is exactly the problem.
I used this training with 2 gpu's
bash tools/dist_train_partially_faster_rcnn50_att_90_4classes.sh semi 1 10 2
将工作人员信息更改为
samples_per_gpu=5, workers_per_gpu=2,
我一直在使用 fp16
我遇到了另一种类型的错误,
ERROR:torch.distributed.elastic.agent.server.local_elastic_agent:[default] Worker group failed我仍然很困惑到底是什么问题。我将此培训与 2 个 gpu 一起使用
bash tools/dist_train_partially_faster_rcnn50_att_90_4classes.sh semi 1 10 2
have you solved it?