the pretrained-layer's param has been re-init
hi, I use the 'from_pretrain ' func to load the pretrain model ,but I found the linear param will be re-init when I simply replace the nn.Linear with lora.Linear
Hi!
Do you mean the "from_pretrain" function in HuggingFace? If so, I encourage you to check out the HF implementation of LoRA (https://github.com/huggingface/peft).
@edwardjhu hello, I am facing a similar problem to understand how to use it and what is described on the abstract.
We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
I have a model with several layers, I loaded the weights and then I updated with the lora layers provided by the repo:
self.model.conv1 = lora.Conv2d(3, 64, kernel_size=7, stride=(2, 2), padding=(3, 3), bias=False)
but doing this, I am not freezing these weight, but injecting new ones, so I lost my previous weight (knowledge).
Do I need to change the way that I am using it? Because I would like to use the conv2d as the following image from the paper, without change the prior knowledge:
@edwardjhu hello, I am facing a similar problem to understand how to use it and what is described on the abstract.
We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
I have a model with several layers, I loaded the weights and then I updated with the lora layers provided by the repo:
self.model.conv1 = lora.Conv2d(3, 64, kernel_size=7, stride=(2, 2), padding=(3, 3), bias=False)but doing this, I am not freezing these weight, but injecting new ones, so I lost my previous weight (knowledge).
Do I need to change the way that I am using it? Because I would like to use the conv2d as the following image from the paper, without change the prior knowledge:
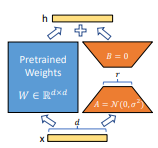
I am not sure if there is an easy way, but basically, I wrapped the loraConv2d class and initialized the weights with what I have previously, in which conv2d_weights is passed for the wrapper. Something like the following code snippet:
nn.Conv2d.__init__(self, in_channels, out_channels, kernel_size, stride=stride, padding=padding, bias=bias)
self.weight = conv2d_weights.weight
self.bias = conv2d_weights.bias
How did you do it? As Conv2d looks like this:
class Conv2d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv2d, self).__init__(nn.Conv2d, *args, **kwargs)
How did you do it? As Conv2d looks like this:
class Conv2d(ConvLoRA): def __init__(self, *args, **kwargs): super(Conv2d, self).__init__(nn.Conv2d, *args, **kwargs)
I need to check it again because it was a long time ago that I tried, when I have time I will check again an update here, Thanks for asking.