[BUG]embedding is not splited while inference using gpt2
Describe the bug
deepspeed --num_gpus 2 inference-test.py --name gpt2
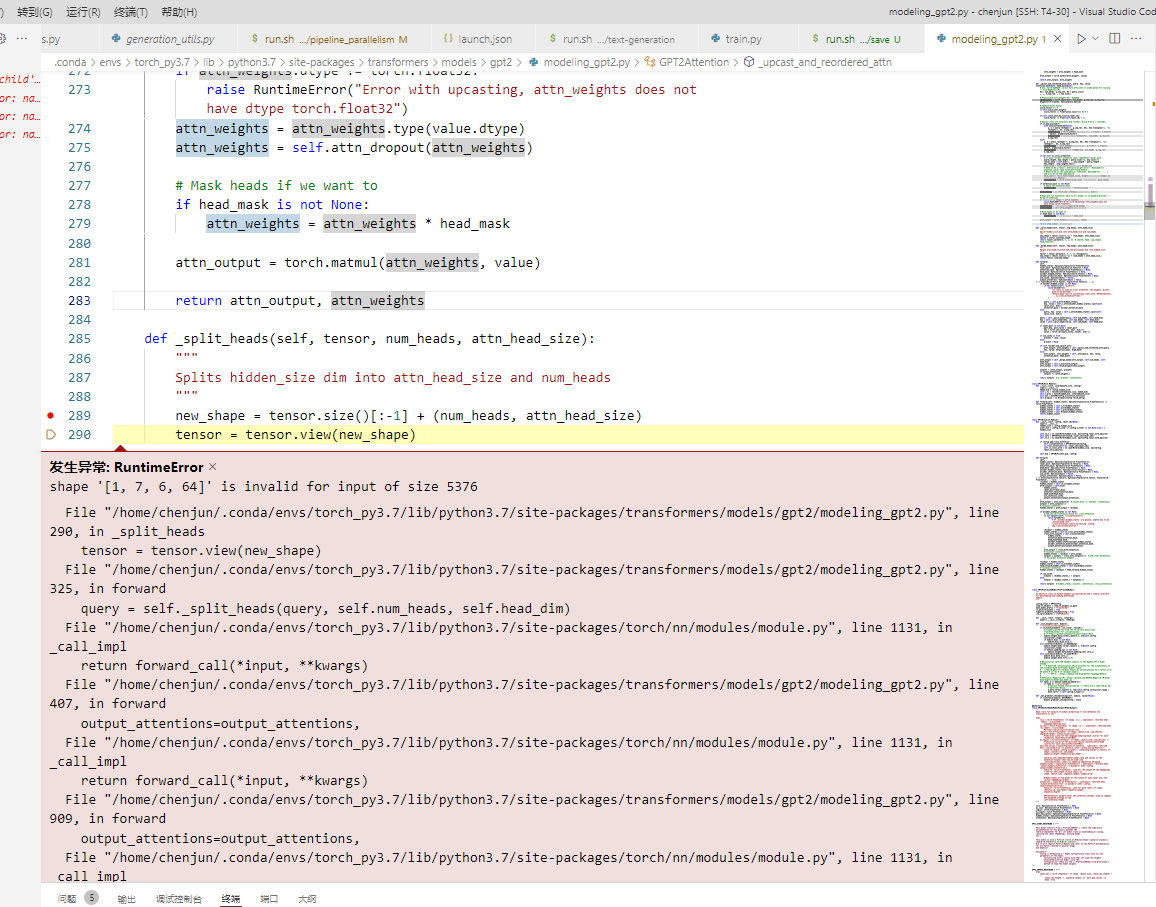
I modify the inference-test.py cause i do not want to use the .cu files. It seems that GPT2 embedding is not splited into two gpus cause i got an error "RuntimeError: shape '[1, 7, 6, 64]' is invalid for input of size 5376". How to set the right injection_policy to split wte and wpe for GPT2?

if args.ds_inference: pipe.model = deepspeed.init_inference(pipe.model, dtype=data_type, mp_size=world_size, # replace_with_kernel_inject=True, replace_with_kernel_inject=False, injection_policy={GPT2Block:('attention.out_proj','mlp.c_proj')}, max_out_tokens=args.max_tokens, **ds_kwargs )
To Reproduce
Steps to reproduce the behavior:
modify inference-test.py:
if args.ds_inference: pipe.model = deepspeed.init_inference(pipe.model, dtype=data_type, mp_size=world_size, # replace_with_kernel_inject=True, replace_with_kernel_inject=False, injection_policy={GPT2Block:('attention.out_proj','mlp.c_proj')}, max_out_tokens=args.max_tokens, **ds_kwargs )
run : deepspeed --num_gpus 2 inference-test.py --name gpt2 Expected behavior gpt2 2 tp can run
ds_report output
Please run ds_report to give us details about your setup.
Screenshots

System info (please complete the following information):
transformers 4.21.2
deepspeed 0.7.7
What is the right way to set injection_policy to split wte and wpe for GPT2? I found no relevant examples for this question
Hi @katitizhou, GPT2 is not supported for tensor parallelism without kernel injection. You can split gpt2 across multiple GPUs by setting kernel injection to True and removing injection policy.