SuperNet training log file?
Hi~ 谢谢你们完美的工作 你能给我提供你们训练超网的LOG文件吗 我发现在训练超网时prec1特别低 如下
 我在训练spos的时候前6个epoch精度已经到30左右了
我在训练spos的时候前6个epoch精度已经到30左右了
Hi, thanks for your interest in our work. Can you share the settings for the experiment? Then, I could give more detailed helps.
你好,谢谢你的回答,我在这里用中文来表达我的一些疑问!
第一点,在论文里面的消融实验,你用的sta_num是481M的,即[4,4,5,4,4]的配置,你在消融实验里说你用single path one shot的方法超网精度能到63.5,但是我照着你的配置跑了一下single path one shot版本,精度只有58,如图,
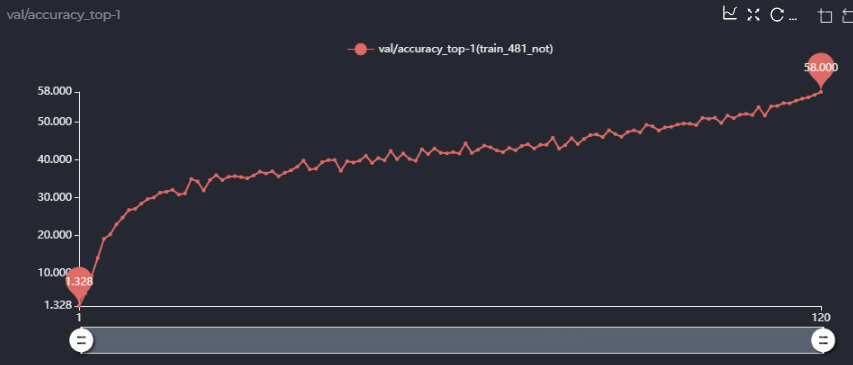 而且,58的精度是在你设定prob为(0.05, 0.2, 0.05, 0.5, 0.05, 0.15)情况下,我也跑了均匀采样的方法,不用你设定的概率,现在没跑完,跑出来的精度如下,可以确定的是精度应该不能到58,
而且,58的精度是在你设定prob为(0.05, 0.2, 0.05, 0.5, 0.05, 0.15)情况下,我也跑了均匀采样的方法,不用你设定的概率,现在没跑完,跑出来的精度如下,可以确定的是精度应该不能到58,
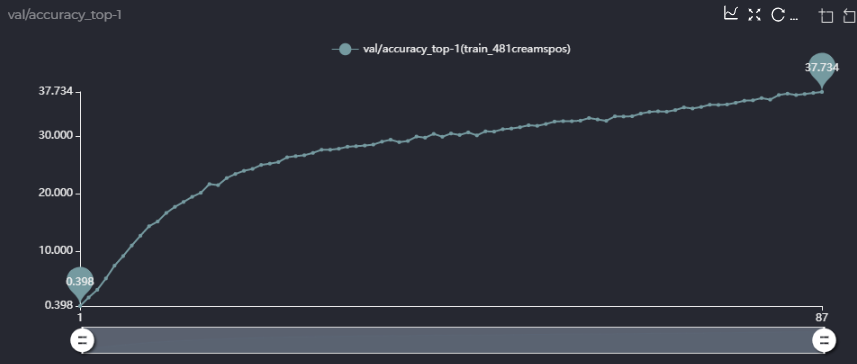 我很想知道你的63.5是怎么跑出来的,是在跑出来的超网上进行了进化搜索算法得到的精度吗?或者直接超网训练得到的精度就能到63.5,如果是这样,你能给我提供你超网训练的LOG文件吗?
我很想知道你的63.5是怎么跑出来的,是在跑出来的超网上进行了进化搜索算法得到的精度吗?或者直接超网训练得到的精度就能到63.5,如果是这样,你能给我提供你超网训练的LOG文件吗?
第二点,关于meta_value,你的代码里实现如下(PrioritizedBoard.py):
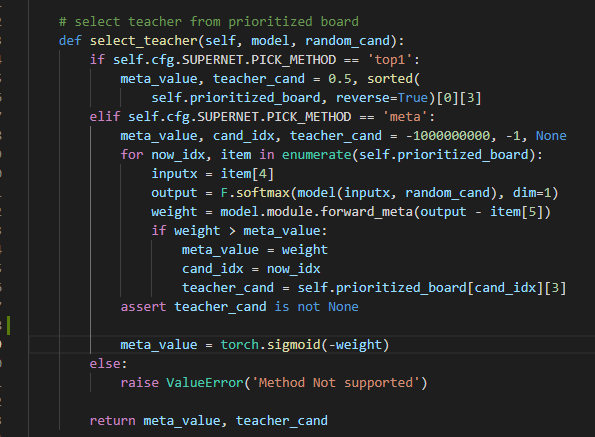 这里是torch.sigmoid(meta_value)还是代码里的torch.sigmoid(-weight)呢,如果是torch.sigmoid(-weight),似乎说不通?
同时,我认为你们将meta_value用来加权valid loss和teacher loss是合理的,但是在子网的梯度反传的时候,由于meta_value的值是由output - item[5]作为输入得到的,那么在loss.backward()里面meta_value是不是也有关于当前子网的gradfn?我认为是不太合理的,是不是代码该这样写呢如下:
这里是torch.sigmoid(meta_value)还是代码里的torch.sigmoid(-weight)呢,如果是torch.sigmoid(-weight),似乎说不通?
同时,我认为你们将meta_value用来加权valid loss和teacher loss是合理的,但是在子网的梯度反传的时候,由于meta_value的值是由output - item[5]作为输入得到的,那么在loss.backward()里面meta_value是不是也有关于当前子网的gradfn?我认为是不太合理的,是不是代码该这样写呢如下:
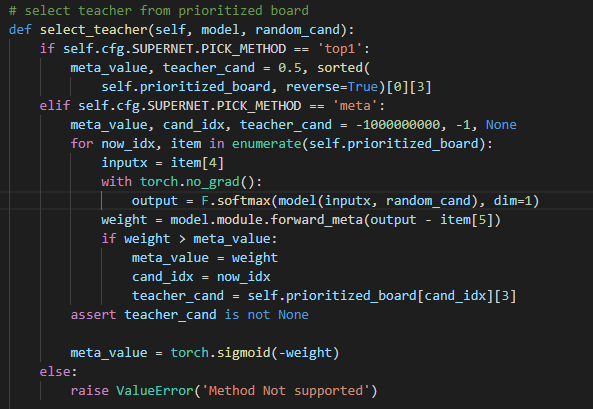 这样loss.backward()时就不会通过meta_value传递梯度到子网了吧,我不确定我理解的是否准确,但是当我这样做的时候跑出来的精度曲线和不这样做精度曲线如下:
这样loss.backward()时就不会通过meta_value传递梯度到子网了吧,我不确定我理解的是否准确,但是当我这样做的时候跑出来的精度曲线和不这样做精度曲线如下:
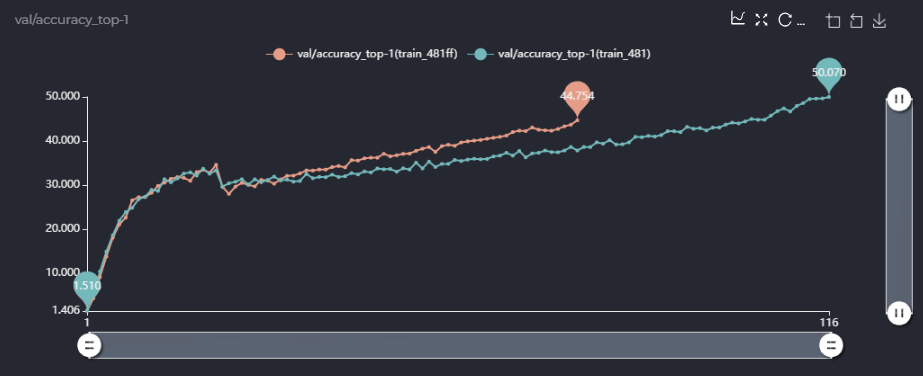 上面是我设置了with torch.no_grad()情况下
上面是我设置了with torch.no_grad()情况下
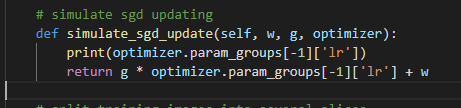
第三点关于simulate_sgd_update,你们官方给的代码如下,我不理解为什么你们手动模拟当前子网梯度下降时,用的学习率是meta网络的学习率0.0001,而不用超网学习率?
如果你们允许,我希望加你们的微信深入沟通一下这些问题,因为我们最近在复现经典的nas论文,我的微信号是:Peach-Bacon
你好,
请问可以分享下实验的环境配置吗?不同的版本会带来结果上的差异
1)请问你是怎么evaluate supernet的呢?想确认下是否是不同的evaluate方式带来了差异
2)感谢指出代码里的问题!我们在重组代码时,并未发现这里的问题,实际上应为meta_value,即最合适的teacher。
3)这里只是恰巧选到了meta网络的lr。
我已经加了您的微信,如果有任何问题,很欢迎继续指出~