Feature Request: Threading for faster account processing
Title: Allow Multithreading for faster AWS account processing
Description: Currently I have a lot of AWS accounts to correlate. Dozens and dozens. New ones come online every day, and we need to see how permissions are shared between them all. Our last Cartography run clocked in at about 3.5 hours. It's survivable, but it got me wondering if there was any way of scaling wide with account population without running afoul of any relevant AWS api request limits (which I believe are per-region-per-account, but I could be wrong, see link below).
The other obstacle to this would be some of cartography's ingest mechanisms - you'd need to wait until all info has been pulled to start building relationships, and I'm not familiar enough to know if this would require a large behavioral change. Is this at all possible?
[optional Relevant Links:] https://docs.aws.amazon.com/AWSEC2/latest/APIReference/query-api-troubleshooting.html#api-request-rate
Hi there, thanks for filing this issue. Sync speed is absolutely a pain point we feel as well. I'm going to write broadly on perf problems.
Parallelism within the AWS sync
Multithreading amongst AWS accounts is something we've considered but have held off on for this reason: If one thread runs into a problem and fails, even if the other threads succeed you still end up with partial data. You will having missing assets, and relationships connecting one account to another account will be incorrect.
As you pointed out, a sync of multiple hours is a crappy situation because you can't rely on the data being 100% accurate if you query the graph in the middle of a sync while it's being updated. One way to get around this is to have Neo4j replicas that can be used when data is being synced on the DB instance being written to.
DAGs for parts that don't have data dependencies
One idea we have planned within the next 3 months (see our meeting minutes and roadmap doc) is to implement DAGs for parts of the sync that don't have data dependencies; if the AWS sync fails then there is no reason for the GCP sync to fail as well. These DAGs could run in parallel and improve perf, but this doesn't solve your problem of having dozens of AWS accounts and keeping those in sync.
All that said, there are some key bottlenecks within any given sync (credit to Evan Davis for the list).
- Time spent pulling data from various APIs.
- Time spent transferring data to neo4j (NOT query execution, the actual transfer of data from the Python process to the Neo4j process via the kernel’s networking stack)
- Misconfigured queries (e.g. merges with no indexes)
We need to emit metrics on each phase of the sync to better prioritize the bottlenecks. Addressing these items could help with syncing dozens of AWS accounts in a timely manner. There are probably lots of low hanging fruit.
you'd need to wait until all info has been pulled to start building relationships, and I'm not familiar enough to know if this would require a large behavioral change. Is this at all possible?
Correct, although I am not 100% sure if the API is the biggest bottleneck and we need to measure that to know for sure.
Yet another approach
Another way that would be a very big change would be to consume event streams from something like AWS Cloudtrail. This way, you could seed a Cartography deployment with one big sync, and then set up subscribers to Cloudtrail events that would update the graph whenever a create, delete, or relationship change event happens.
Anyway, clearly there is lots of work to do :) I don't have a straightforward answer for you at the moment but we are open for suggestions and please definitely feel free to get involved as much as you want (perhaps joining in on Slack or talking more on this at our monthly meeting :)). Definitely want to hear more about how you are using the tool, and hope we can help.
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs.
@achantavy I've been looking into this recently, and I think in terms of incorrectness of data, this is an issue whether or not the accounts are multi-threaded. If any one account fails, it may fail after other successful account syncs and you'll end up with data that's partially filled in. For correctness here, rather than exiting immediately on a failure, error handling should be wrapped at the thread pool level, and when an exception is caught in one account sync, it should stop that thread, wait for all other threads to finish, then exit. In that situation, it would be similar to a single account failing in a synchronous sync.
There's the possibility of more cross-account data being incorrect when that fails, but in the current situation if a sync fails, it may be a day or two before the sync is successful, and during that time, the data can't really be trusted anyway. Being able to bring the graph into a trustworthy state faster may be more desirable than having less data in an untrustworthy state.
In terms of speed, I think a considerable amount of time is spend waiting on IO from calls to AWS. I did a quick test of adding async to per-account syncs and it shaved over 5 minutes off my sync for just a couple small accounts (and I didn't put any effort into adding yields to sub-resources). If we were to add async per-account, and yields to sub-resources, we could likely shave hours off most syncs without any ratelimiting issues.
Has there been any further discussion of this feature? I'm currently trying to map an organization with about 2 dozen accounts and the processing time is incredibly painful. I agree with @ryan-lane regarding the issue of data inconsistency, and that it will be more important to update state quickly.
@ryan-lane do you still have your POC asynch code? I'd like to try it for my use case and see if it helps. Otherwise I think I can guess where the asynch processing would need to go (inside of the job runner)
We were actually talking about this very recently in lyft OSS slack. I believe paypay may be working on a proof of concept for the aws module.
On Wed, Jul 20, 2022, 8:09 PM Andrew Kesterson @.***> wrote:
Has there been any further discussion of this feature? I'm currently trying to map an organization with about 2 dozen accounts and the processing time is incredibly painful. I agree with @ryan-lane https://github.com/ryan-lane regarding the issue of data inconsistency, and that it will be more important to update state quickly.
@ryan-lane https://github.com/ryan-lane do you still have your POC asynch code? I'd like to try it for my use case and see if it helps. Otherwise I think I can guess where the asynch processing would need to go (inside of the job runner)
— Reply to this email directly, view it on GitHub https://github.com/lyft/cartography/issues/257#issuecomment-1190141718, or unsubscribe https://github.com/notifications/unsubscribe-auth/AALXSMXCTEXSVR7Z7OEXAQ3VU7NADANCNFSM4LFFPB2Q . You are receiving this because you were mentioned.Message ID: @.***>
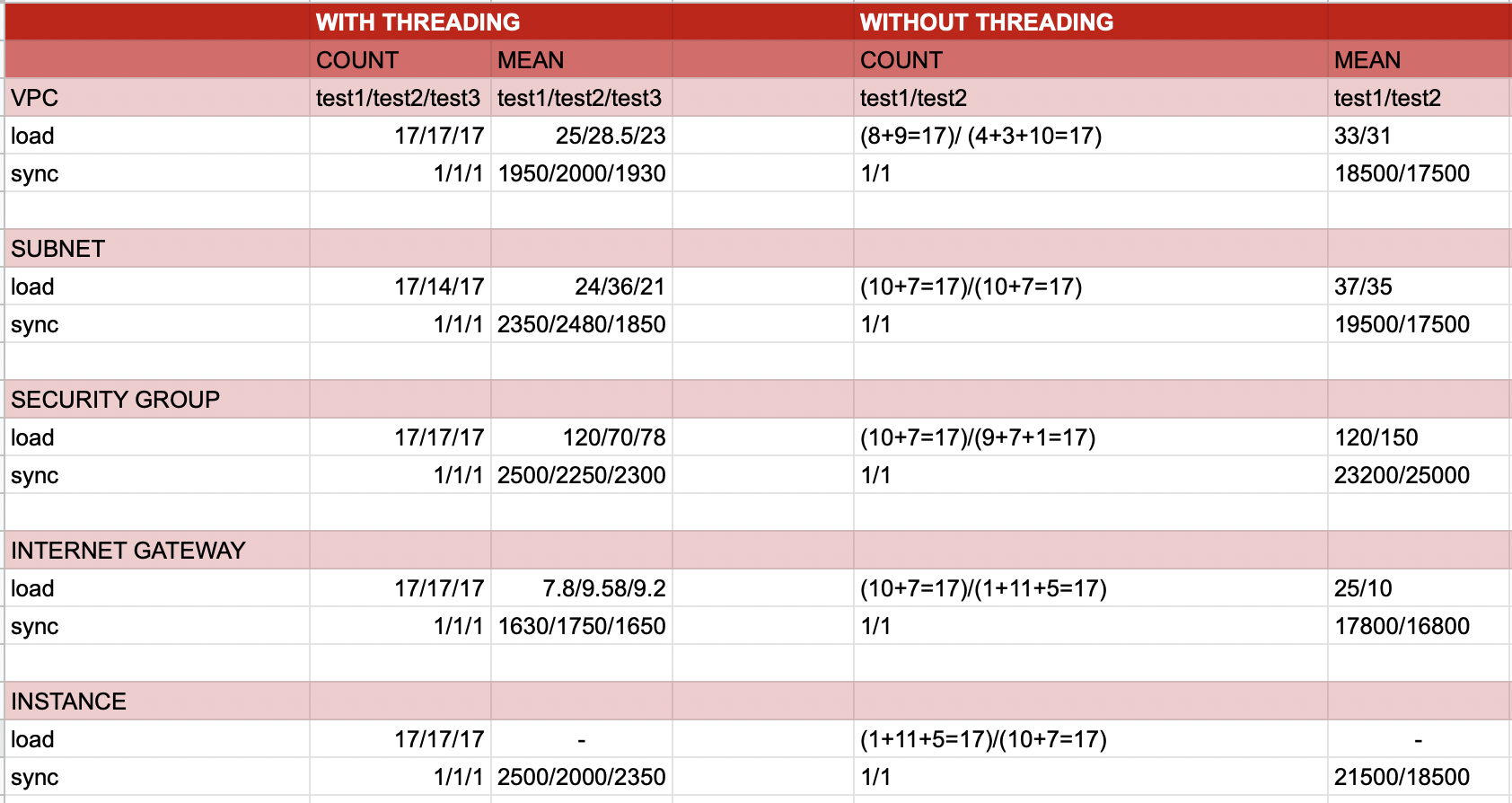
Was there any actual work done on this? For the same account, are there issues with doing parallel resource discovery across regions? I have done a little bit of experimentation. Besides needing separate neo4j sessions per thread, it appears to be working fine and shaving wall clock time meaningfully. Happy to put it up as a PR if it helps for discussion.
For the same account, are there issues with doing parallel resource discovery across regions?
Syncing resources in the same account in parallel can be problematic because some jobs assume that some other resources are already present in the graph, so they do a MATCH and then MERGE. If the resource being matched on does not exist yet, then no graph update will happen.
For this reason, we decided on that Slack thread that @ryan-lane mentioned (blah Slack only persists previous 90 days) that it would make more sense to do accounts in parallel.
I have done a little bit of experimentation. Besides needing separate neo4j sessions per thread, it appears to be working fine and shaving wall clock time meaningfully. Happy to put it up as a PR if it helps for discussion.
We haven't had time to work on it and haven't received a PR yet and absolutely would welcome help. How much time savings are you seeing?
I have made a PR https://github.com/lyft/cartography/pull/1053. It is not ready to be merged yet. I want to know how you want to handle exceptions when they occur in worker threads (the threads which are running for each region).
How much time savings are you seeing?
For each resource, the mean time to run the sync takes approximately 10 times less if we parallelly update the data across regions.