How do I disable I$ parallel memory request whenever there is a branch and it's a tag hit?
My Environment
EDA tool and version:
Operating system:
Version of the Ibex source code:
EDA tool and version: Verdi
Operating system: Linux
Version of the Ibex source code:[c9e3fde]
Hi there. I'm not entirely sure what you're asking for here.
The design intentionally does a read of the tag ram and data ram at the same time, so that if there's a hit then it can respond with the relevant data on the same cycle. It doesn't send out a request on the bus until after seeing a tag miss.
What are you seeing and why isn't it what you expect?
I think I may be having a related issue. Namely, instr_req_o is set when there is a branch, even if the branch target is cached, resulting in extraneous instruction memory fetches. Perhaps this is what OP means by "parallel memory request".
Ahah! Now I've looked again (and also talked to @gregac) I've worked out what's going on. This is actually intentional behaviour. The idea is that we shave a cycle of latency off by doing this. If the branch is to a location that turns out to be cached, we'll ignore the bus response. This performance comes at the cost of some unnecessary bus traffic, but we expect systems using Ibex will prefer this trade-off.
To see an example of this happening, I added the following (silly) assertion to the code and ran the icache smoke test:
Bogus_A:
assert property (@(posedge clk_i) disable iff (!rst_ni)
(branch_i && lookup_actual_ic0 |=> tag_hit_ic1 |=> 1'b0))
else begin
repeat (100) @(clk_i);
`ASSERT_ERROR(Bogus_A)
end
Here's an example of it working as intended. The marker on the left is when the initial branch request appears. The marker on the right is when the response from the bus comes back.
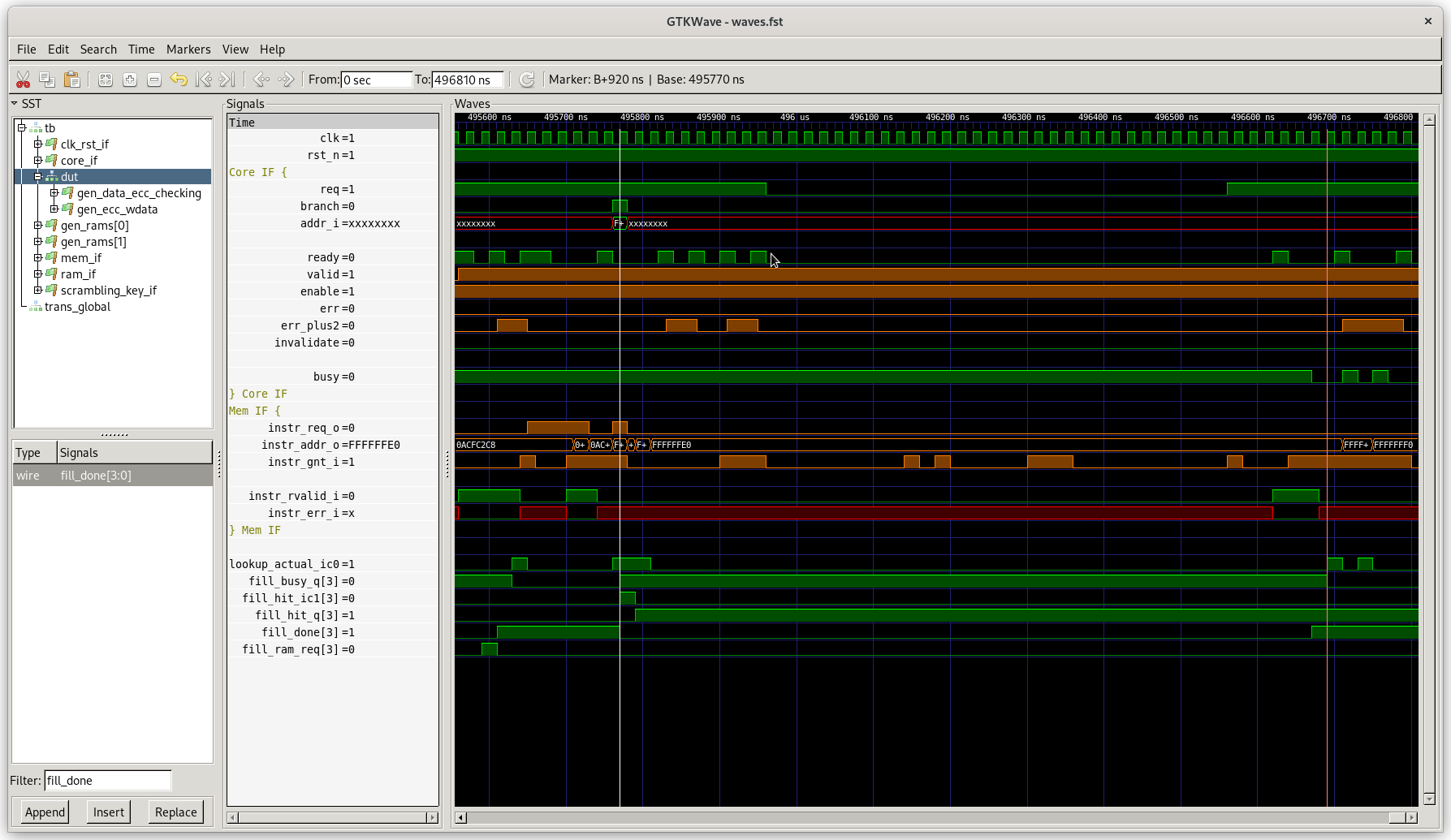
The lookup_actual_ic0 signal shows us checking the cache for something at 0xffffffc8 (the branch address, not that you can actually see it in the screenshot). This allocates fill buffer 3 (which is why fill_busy_q[3] goes high). Then fill_hit_ic1[3] going high on the next cycle shows that this was actually a cache hit. Note that this sets fill_hit_q[3].
This flag has two effects. Firstly, it short-circuits the fill buffer's refill: we don't make bus requests for anything but the first word in the fill buffer and it is considered done (fill_done[3]) as soon as the first memory response comes back. Secondly, it squashes the relevant bit in fill_ram_req, which ensures we won't actually store the result to the tag and data rams.
OK. I think why I'm seeing an (unnecessary) delay is because I do not have the instruction memory respond with instr_gnt_i until the access has been nearly completed (a cycle before instr_rvalid_i is signaled), rather then granting at the beginning of the access. This, in turn, leads to a stall on the unneeded instruction memory request. I'll try changing the memory controller to gnt when the request arrives, rather then when the a cycle before request is completed and instr_rvalid_i is signaled. Seems like an implementation bug on my end, and good design choice in Ibex, although a case could be made that for low performance systems, which are often pin-limited, limiting off-chip bandwidth should be prioritized. For example, suppose I want to fetch program data from off-chip via a serial port.
Ah, I think you're not quite using the signals properly. The "grant" signal is supposed to mean "I have taken your request". If you have a pipelined bus, you can grant many requests before the first rvalid.
I believe that from @rswarbrick latest comment that this issue may be a misunderstanding. As such tagging ready for close, unless there is a comment raised from the original poster.