Non UTF-8 with BOM can't be read
A a non utf-8 file with BOM cannot be read by Logstash file input. Results in garbled characters:
"message" => "\u0000 \u0000 \u0000 \u0000 \u0000\"\u0000T\u0000i\u0000m\u0000e\u0000z\u0000o\u0000n\u0000e\u0000\"\u0000:\u0000 \u0000 \u0000\"\u0000A\u0000m\u0000e\u0000r\u0000i\u0000c\u0000a\u0000/\u0000N\u0000e\u0000w\u0000_\u0000Y\u0000o\u0000r\u0000k\u0000\"\u0000,\u0000",
Whereas the same file, after converting using unix2dos,
dos2unix: converting UTF-16LE file UNIX.txt to UTF-8 Unix format...
The file can be opened with no problem.
Not sure if it's the BOM or the charset that's causing the issue.
Similar/Related Issues:
- What charset to use?
- "Incompatible encoding" when using Logstash to ship JSON files to Elasticsearch
Hi,
So, did you manage to solve the issue? I am having a similar problem reading json messages from RabbitMq.
It looks like is adding an extra character at the beginning of the message that breaks my json parser.
When I look at the message in kibana (after adding it to elasticsearch), I can see that there is an unexpected character:
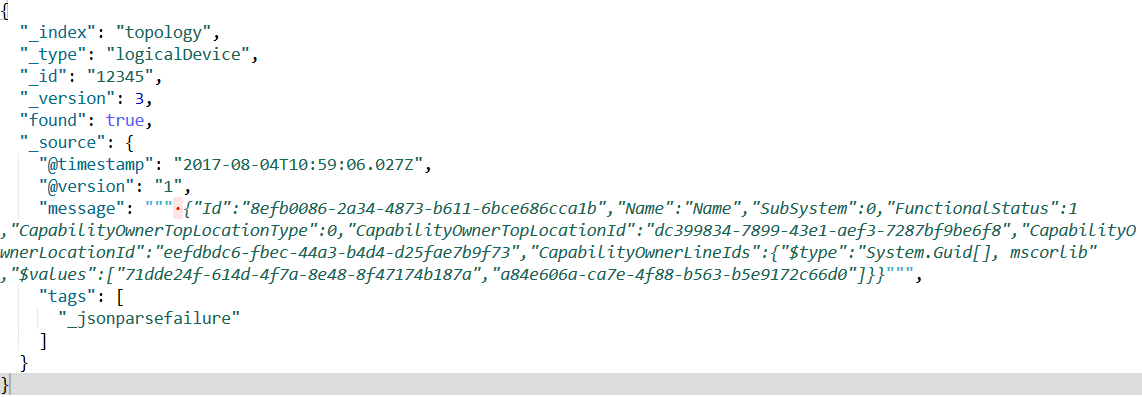
Hi again,
I found from where I was getting the _jsonparserfailure. It was not because of the message but because of the rabbit plugin. It is using by defaul json codec but it is documented.
After changing the codec to plain in the rabbit plugin and adding a filter json plugin to only parser the "message" property, it worked.
I still do not understand why rabbitmq imput plugin is failing to parser the rabbitmq message.