checkpoint cann't load
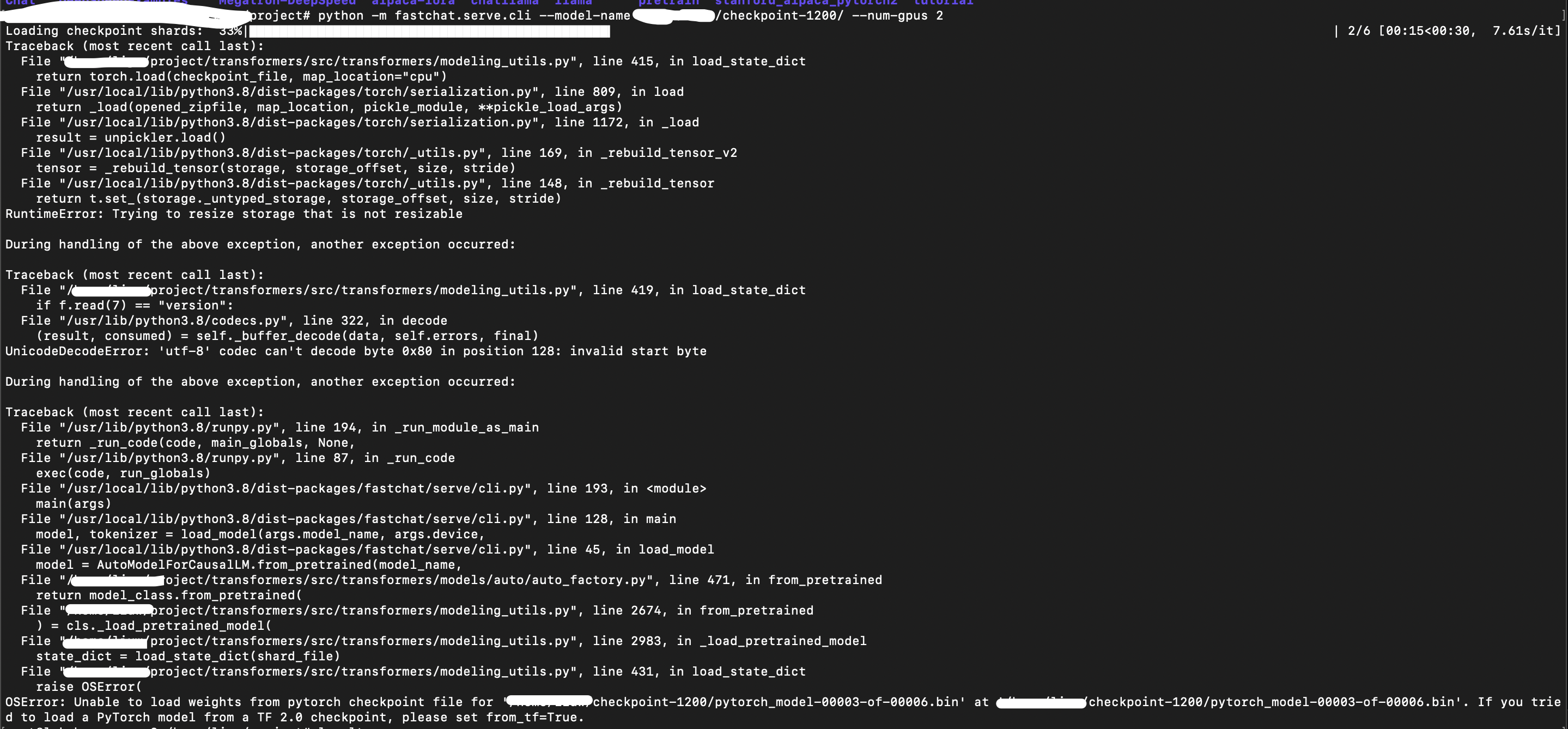 The model I trained cannot be loaded,The training code
The model I trained cannot be loaded,The training code
torchrun --nnodes=1 --nproc_per_node=4 \ fastchat/train/train_mem.py \ --model_name_or_path <path-to-llama-model-weight> \ --data_path <path-to-data> \ --bf16 True \ --output_dir ./checkpoints \ --num_train_epochs 3 \ --per_device_train_batch_size 4 \ --per_device_eval_batch_size 4 \ --gradient_accumulation_steps 1 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 1200 \ --save_total_limit 100 \ --learning_rate 2e-5 \ --weight_decay 0. \ --warmup_ratio 0.03 \ --lr_scheduler_type "cosine" \ --logging_steps 1 \ --fsdp "full_shard auto_wrap" \ --fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \ --tf32 True \ --model_max_length 2048 \ --gradient_checkpointing True \ --lazy_preprocess True
same error. environment: torch 1.13.1+cu116 transformers 4.28.0.dev0 Python 3.8.15
This issue is caused by corruption of model weights while saving due to OOM. Refer #256 Unable to save the mode weights - GPU OOM
Make sure there are no warnings while you train the model.
UserWarning: Failed to clone() tensor ...
Once you fine-tune the model without OOM you can load and infer the model. Look for solutions in #256