Knative Serving fallbacks to previous ready revision automatically despite the latest revision was already rolled out
In what area(s)?
/area API
What version of Knative?
0.17.x Output of
git describe --dirtyThe version is old but likely the issue exist in latest version as well.
Expected Behavior
Once the latest revision was rolled out and got into the "ready" state, knative should never fallback to previous revision automatically.
Actual Behavior
Revision 2 is rolled out and has been running for almost a month, then there is a sudden unexpected event which scales the latest revision down, the minReplia is set to 4 for the knative service.
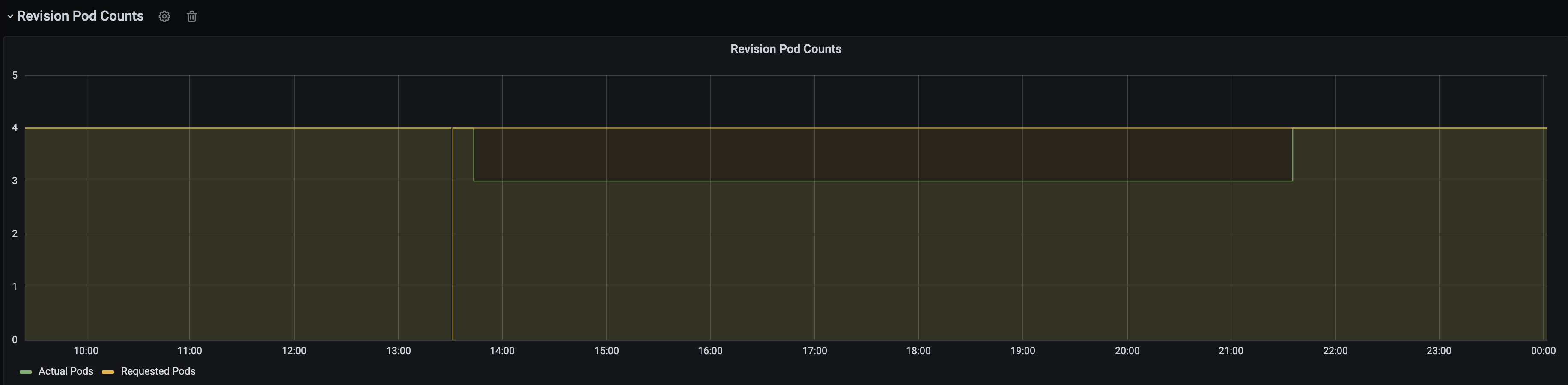
Knative then falls back and scale back the previous ready revision 1 automatically which should not happen
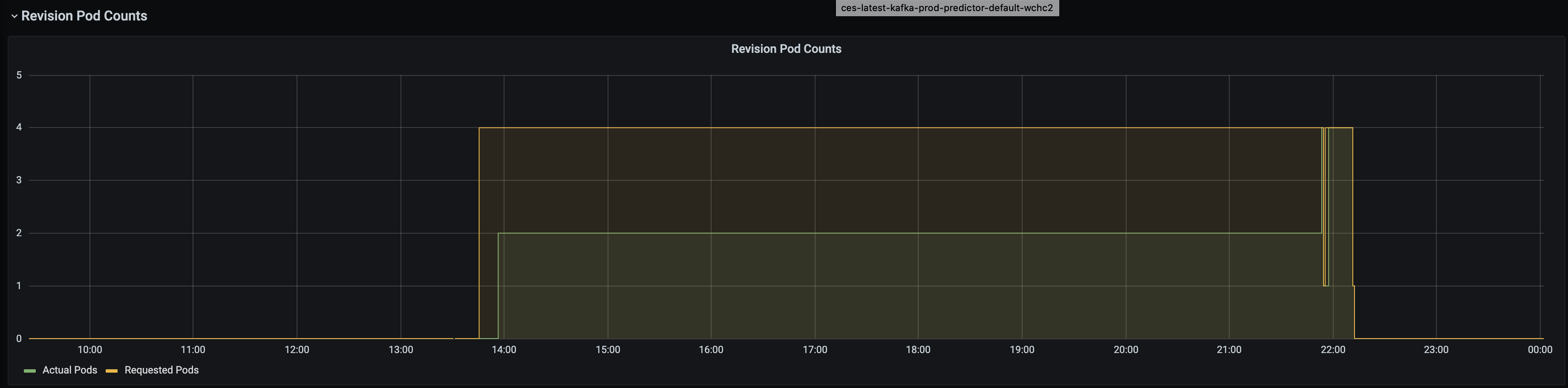
A more compounded problem is that both revisions are not able to fulfill the minReplica 4 requirement as they both hit the resource quota error and you can see from the graph that both are running but only 3 replicas. We fixed the issue by manually released some resources then the knative service went back to the latest revision 2.
Steps to Reproduce the Problem
This is a very rare event which can be hard to reproduce, but we are wondering once the latest revision gets into ready state if there is any chance that can still flip back to unknown/false condition which can result in reviving old revision according to revision controller code as we can see the LatestRevisionUpdate events.
I'm a bit stumped because the selection of the next latest ready revision only looks at revisions newer than the current latest ready revision see findAndSetLatestReadyRevision. There's one an exception when the config has an explicit revision name in it's template.metadata here Given that I don't see how older revisions are eligible to become the latest ready revision.
Context about Revision Readiness
Generally the Revision itself has the following conditions that affect it's readiness (source)
- ResourcesAvailable
- ContainerHealthy
ResourcesAvailable
This is set to Unknown when:
- this is the default value
- the child deployment can't be found (source)
- image digest is being resolved from tag (source)
- deployment progressing is unknown (source)
- deployment replica failure is unknown (source)
This is set to False when:
- there's already a PodAutoscaler we don't control (source)
- there's already a Deployment we don't control (source)
- if the pod can't be scheduled (source)
- the deployment has zero available replicas and a single container is in 'Waiting' state (source)
- deployment Progressing is False (source)
- deployment ReplicaFailure is True (source)
- pod autoscaler readiness is false and the initial scale was never reached (source)
ContainerHealthy
This is set to Unknown when
- The deployment doesn't exist
This is set to False when
- Digest Resolution failed (source)
- Deployment has zero replicas and the containers are terminated (source)
Actually this looks a bit off - this is looking the revision's generation and not the configuration generation label that's part of the revision
https://github.com/knative/serving/blob/7c6d4bc5f2947c9c488d125685f2243785689e8b/pkg/reconciler/configuration/configuration.go#L172
Can you post the yaml for your problematic revisions? I'm curious what the metadata.generation is
It's also unclear how the generation would change given the spec can't be changed
https://github.com/knative/serving/blob/7c6d4bc5f2947c9c488d125685f2243785689e8b/pkg/apis/serving/v1/revision_validation.go#L39-L54
working theory
If we assume the second revision's deployment failed to progress because of some event. ie. a pod was rolled/node drained - we would need logs/k8s events to confirm. Then the incorrect revision generation lookup using start := lrr.Generation could include older revision. Then the older revision could be marked as the latest ready revision.