Improving Get-Started Projects and Tutorials
Status
- We have 5 repositories: example-get-started, dvc-checkpoints-mnist, get-started-experiments, get-started-checkpoints, and get-started-pipelines.
- We have a project that generates most of these.
The docs use example-get-started for:
- Data and Model Versioning
- Data and Model Access
- Data Pipelines
- Metrics, Parameters, Plots
- Experiments
Checkpoints guide uses dvc-checkpoints-mnist
Goals
-
We want to improve the content with minimum changes to the existing documents. Adding more content to the already available material is desired.
-
We want to have a common/similar project for the tutorials. A single showcase project to contain all DVC features seems a bit artificial. A set of similar projects may be a better tradeoff for maintenance and usability.
-
DVC has different use cases for different people and we want to emphasize these: ** Data Versioning ** Data Access ** Sharing Models ** Presenting Models with Metrics and Plots ** Experiment Management and Sharing ** Checkpoints (which may be under "experiment management".)
-
There should be more than one entry points for the tutorials, e.g., experiment management should be a first-class citizen.
Discussion and Research Points
-
Current documentation is mostly pipelines-based. Almost all features revolve around
dvc.yamland the pipelines. How can we present DVC as an experiment management system without first telling about the pipelines? -
How high-level the GS docs should be? We also have UC and UG documents and most of the material in GS is also relevant to these sections. Who is our audience for GS? (ML Engineers? DevOps Engineers? DS Researchers? Students? Software Engineers?) What can we assume about them? What do we want to tell them without much low-level stuff and also staying relevant? What are their daily usage patterns?
-
How to evolve the example projects for each of the use cases?
-
How can we (or should we) present other relevant projects like Studio/CML/VSCode extension to people reading the GS pages?
Decisions and Tickets
- Section name to be kept as Get Started for a more tutorial feeling than Quick Start.
- The commands in the documents should be applicable, copy-pastable.
Personas that make up the audience
- Primary persona: - tech-savvy ML engineer, hands-on ML manager, industry (not students, not DevOps - or only their team asked them to check for other tools). Comment @shcheklein
Thanks for the summary, very informative.
Pre-Q
[Checkpoints tutorial] uses dvc-checkpoints-mnist
Meaning https://dvc.org/doc/user-guide/experiment-management/checkpoints? Seems to use https://github.com/iterative/checkpoints-tutorial . Is that one basically https://github.com/iterative/dvc-checkpoints-mnist (live branch) without DVC files BTW? Cc @flippedcoder
On the motivation for this
improve the content with minimum changes to the existing documents... Adding more content
Probably the most important thing and first step here would be to decide on the content. What new content are we looking to add? Which one needs changes? That should drive the sample repos (@dberenbaum has mentioned this too I think).
should be a first-class citizen
Looks like all the existing repos are already stand-alone right? Just trying to understand whether we have a working setup or if there's some urge to keep iterating on sample repos before content. Great work so far BTW!
On the discussion points
How high-level the GS docs should be?
As high-level as possible while supporting hands-on steps.
Who is our audience for GS?
People from all backgrounds who need to learn (certain parts of) DVC fast — get a good grasp of basic concepts, problems/solutions, while trying the major commands (UX).
can we (or should we) present other relevant projects like Studio/CML/VSCode
I'd focus on DVC for now 🙂
Long answer
Depends on the product:- CML isn't closely connected to GS topics as of now and has it's own GS.
- Studio we can just briefly mention and link from the Experiments docs (in GS and elsewhere).
- VSC is trickier, we can figure it out in the future (e.g. a switch between code blocks and VSC screenshots).
Thanks @iesahin . I agree with @jorgeorpinel on the audience/level (I would keep it as is)/other projects (let's not do this for now- I would think about dvclive though).
Some thoughts on the content (acknowledging that this is the most important one anyway).
First, to remind a bit on why the existing example get started is considered suboptimal:
- last sections depend on the previous ones to try to run something or even to understand them
- project doesn't fit naturally into some scenarios - e.g. checkpoint - the most obvious one
- the way it is structured it feels that data is more important than experiments, we don't trigger the feeling that DVC is not (only) about data management - it's about experiments tracking, it's about model lifecycle management, etc.
Bottom line: we want to make experiments (and potentially pipelines?) first class citizen in the get started.
How to evolve the example projects for each of the use cases?
I would not do this. I would start with two entry points - Data & Models Versioning (?), Experiments Management - something like that?
Who is our audience for GS?
- they know basics of Git (no need to explain what
git initis) - they know basics of ML (no need to spend time explaining ML itself)
- Industry folks come first, students second (but in case of GS I would try to keep comprehensible for students if they understand at least some problems we are trying to solve, know git, etc)
What do we want to tell them without much low-level stuff and also staying relevant?
ideally, they should understand from the GS + Use Cases where does DVC fit, how it works - high level
A comment on the HN recent submission, that should drive changes to the experiments section at least:
I have been in search of a very lightweight way to track experiments, so I went to the dvc page and was completely overwhelmed by all of the options. I tried to find the answer to a simple question — how do I log metrics and artifacts from a train/test run? I saw ‘dvc exp run’ (or something like that), but how does it know what my training script is? And what should I add to my code to checkpoint metrics or other stuff at various points in a script? I was looking for a simple, self contained “getting started” sequence of pip installs and example code, but I found the docs linking all over the place.
I was previously looking at keepsake, an extremely lightweight experiment tracker/logger. But it had some issues working with PyTorch lightning, so I was back searching for something else.
Is there a way to get user feedback on GS pages somehow within the pages? PHP had comments in documentation maybe 10+ years ago. Could we have, for example, links to discussions, comments, or some sort of feedback facility in the pages themselves?
@iesahin it's a very good point, I would love to see some nice way to collect feedback, discussions, etc. We can create a separate ticket for this and prioritize.
Meaning https://dvc.org/doc/user-guide/experiment-management/checkpoints? Seems to use https://github.com/iterative/checkpoints-tutorial . Is that one basically https://github.com/iterative/dvc-checkpoints-mnist (
livebranch) without DVC files BTW?
Yes, checkpoints-tutorial is a single branch copy of dvc-checkpoints-mnist, tailored for the UG checkpoints guide.
This checkpoints guide has several drawbacks, IMO:
- It starts with setting up the pipelines and that's a distraction I think
- It uses only
dvclivefor checkpoints. There are other ways to use checkpoints with DVC API. - It adds the experiments/plots/metrics to the mix. These are also repeated in several other places in the docs.
All checkpoints guides (either for the GS or UG), should assume experiments as a starting point. Checkpoints rely on dvc exp and without experiments, checkpoints are not useful. We need to tell checkpoints as an extension to the experiments.
The reason I proposed #2518 is this. There should be GS level guide after experiments that introduce the checkpoints.
What new content are we looking to add? Which one needs changes? That should drive the sample repos
I'd rather have an evolutionary approach in these. What's the most obvious, glaring points that we miss from the Get Started section?
- We don't have a full and independent experiments tutorial, that doesn't rely on pipelines.
- We don't have any practical hands on information on checkpoints.
- Metrics and plots should be told as a product of experimentation.
I propose three starting points for the GS docs:
- Data and Model Versioning and Access
- Pipelines
- Experimentation
These 3 documents should be independent from each other. They can have subsections that we use to link from each other. Each should take at most ~1 hour to read and understand the subject matter.
Also we can employ Studio in several places, especially in experiments, if you don't mind hijacking open source software documentation for SaaS promotion.
Looks like all the existing repos are already stand-alone right? Just trying to understand whether we have a working setup or if there's some urge to keep iterating on sample repos before content.
Example repos are actually shaped by the tutorial and showcase requirements. The reason I'm trying to bring forward a GS Experiments document in #2497 is to shape the repository in iterative/example-repos-dev#44 according to the reviews. I've updated, e.g., almost all the parameters, the pipeline, etc. in get-started-experiments after review in #2497. We can create, destroy, split, merge the repositories as much as we like.
These get-started-X repositories will be shaped as we progress in the docs. They are more fluid and disposable than the current one.
How high-level the GS docs should be?
As high-level as possible while supporting hands-on steps.
What do you mean by high level exactly? @jorgeorpinel
I have some ideas but would like to learn yours first.
Who is our audience for GS?
People from all backgrounds who need to learn (certain parts of) DVC fast — get a good grasp of basic concepts, problems/solutions, while trying the major commands (UX).
IMHO all backgrounds is a set, a bit too large. We need to profile the users and decide on their goals to use DVC.
We need to make assumptions on the following criteria (and more)
- Do they know to write software? (in any language)
- Do they know Python?
- Do they know Git?
- Do they know to use text editors?
- How comfortable are they using the command line?
- What is their OS?
- Are they working locally or remotely?
- Do they use cloud services?
- How large are their organization? Are they working solo or within a 10000 people corporation?
The most important: What they ask from DVC?
- Dataset tracking
- Experiment management
- Model tracking
- Sharing experiments within their organization
- Building demos
- Automated pipelines
I'd like to have 3-5 distinct persona, for whom we write our content. We can review the documents in their eyes. Without a set of concrete persona, I think content production becomes a moving target. I can write for myself and you can review for yourself but our goal is not to document the software for ourselves.
can we (or should we) present other relevant projects like Studio/CML/VSCode
I'd focus on DVC for now
I think presenting visual aspects using Studio is much easier at first. For example using plots and showing how those plots are generated in ~~DVC~~ Studio seems easier to follow than showing a bunch of commands and telling the end result.
How to evolve the example projects for each of the use cases?
I would not do this. I would start with two entry points - Data & Models Versioning (?), Experiments Management - something like that?
Then, it looks like we can use example-get-started for Versioning, and use the current documentation as a chapter for Versioning docs. It will contain (1) Data and Model versioning (2) Data and model access (3) Sharing and Remotes.
Write another document for Experiments, that contain (1) Experiment Management (2) Plots and Metrics, (3) Sharing Experiments, and (4) Checkpoints.
Readers may start from Versioning and proceed to Experiments, or start from Experiments and hop to Versioning.
I think we need another one for the Pipelines, or write the pipelines as an addendum to each of these. Pipelines are a bit orthogonal to the other aspects.
I would like to read/tell one thing at a time, in each section. So adding pipelines to the mix may reduce the overall focus for the documents. We can have a shorter Pipelines document that we link from each of these.
they know basics of Git (no need to explain what
git initis)they know basics of ML (no need to spend time explaining ML itself)
Industry folks come first, students second (but in case of GS I would try to keep comprehensible for students if they understand at least some problems we are trying to solve, know git, etc)
I think I can create 3 distinct profiles from these: (1) an industry person with Git knowledge looking for ML production tools, (2) a graduate student with ML experiments looking for experiment tracking, (3) a DevOps guy working in an ML environment with lots of data. If we can keep these profiles as distinct as possible while making their union cover our user base, we can check the docs in these profiles' eyes and see the omissions easily.
I need to have some direction here about the typical users, Alice, Bob and Charlie.
BTW, I'm using some ideas from Martin Lindstrom's Small Data about this profiling idea. I read the book a few years back and I remember how he produces marketing material using profiling. I remember the book saying there are a finite number of profiles that we should be thinking about and people belong to these categories, instead of each having a unique character.
The most important: What they ask from DVC?
What they are looking to do with our tools depends on the doc. For example, I would assume that a get started doc for experiments would target someone doing ML experiments and needing to organize, compare, and track them to decide which experiment is best. Rather than define global profiles, maybe we should define a profile for each get started doc?
would love to see some nice way to collect feedback
Annoying "randomly selected" popups!
@iesahin
We don't have a full and independent experiments tutorial, that doesn't rely on pipelines.
Get Started pages are not tutorials. (See "Master Dict" in https://www.notion.so/iterative/wip-Lost-in-Translation-17a263187e2b40e88072ce041a5be4e1)
We don't have any practical hands on information on checkpoints.
https://dvc.org/doc/user-guide/experiment-management/checkpoints and https://github.com/iterative/dvc-checkpoints-mnist (linked from a few places)
Metrics and plots should be told as a product of experimentation.
This is a good point. But it's hard for me to envision combining both topics since there's so much material in https://dvc.org/doc/start/metrics-parameters-plots
Data and Model Versioning and Access
I think it makes sense to keep Access separate though.
Each should take at most ~1 hour to read and understand the subject matter
This is a good Q. I don't think we've measured the read/try time before. I'm hoping it's much less than 1h — not sure that qualifies as "quick" (assuming Get Started = Quick Start).
we can employ Studio in several places presenting visual aspects using Studio is much easier at first
Studio is a separate product and has it's own docs. I can see adding a layer to switch from terminal to studio in many examples but again, I wouldn't further complicate this discussion with that for now.
As high-level as possible while supporting hands-on steps.
What do you mean by high level exactly? @jorgeorpinel
Great Q actually. By high-level I understand that the GS will cover all of DVC features but only enough to establish what main problem/solution they represent. In this sense it's a relatively shallow kind of doc.
Again, it's goal is to cover lots of ground quickly, provide an overall impression, basic UX experience, and awaken curiosity (link to guides, refs, etc. for more deets).
IMHO all backgrounds is a set, a bit too large.
I don't think it's too broad. People will filter themselves out. If you intentionally ended in the GS, you probably have a good reason, and fit our target audience.
I'd like to have 3-5 distinct persona, for whom we write our content.
Sounds good but I think the GS is the one place where we may not need to worry about that too much. Let's make a separate issue or discuss separately? (I have a metadoc about this here)
A lot of information there :)
I think Emre you are right about 3 entry points. Since we have 2 (mixed now into get-started), I would focus first on the 3rd one - experiments management.
Primary persona for that one - tech savvy ML engineer, hands-on ML manager, industry (not students, not DevOps - or only their team asked them to check for other tools). It doesn't mean that we should disregard simplicity. But we should not be educating people on how to use git.
Level: the purpose of get started is to have a document that people can get idea really quick from. It's more like a quick start. Thus - simple commands, hiding long explanations, etc.
Get Started pages are not tutorials.
Here there is also a Tutorial tag and I think, Quick Start and Get Started are two different kinds. "Get Started" reads like you're about to start something big and these are the first steps. "Quick Start" is saying you're starting with these quickly and can possibly walk the rest by yourself. Get Started feels like let's start and we'll walk together, it doesn't say anything that we'll finish that walking or not. There is no "Get Finished" section. :)
I'd rather rename the sections like (1) Quick Start to Data Management (2) Quick Start to Experiment Management (3) Quick Start to Pipelines and have at most 3000 words for each. (~10 minutes reading.) Another 20 minutes for trying commands and in around 30 minutes, the user should get a gist of the subject.
This is a good Q. I don't think we've measured the read/try time before. I'm hoping it's much less than 1h — not sure that qualifies as "quick"
I think, yes, ~1 hour is too much. Aiming for a soft limit of 10 minutes / 3000 words is better, probably.
What do you mean by high level exactly? @jorgeorpinel
Great Q actually. By high-level I understand that the GS will cover all of DVC features but only enough to establish what main problem/solution they represent. In this sense it's a relatively shallow kind of doc.
This is more or less what I understand too, but I think we should aim for 80% of the features that our user may need in their day to day activities. Instead of presenting DVC features, we should be thinking about which commands they use most and in what order. Once they started, they can come back and read the UG for details or other features.
I don't think it's too broad. People will filter themselves out. If you intentionally ended in the GS, you probably have a good reason, and fit our target audience.
I think we need to control who filters themselves out. If we don't want some kind of audience, e.g., managers who never saw a command line before, filtering out is fine. But, if someone who might be within our users filter themselves out, IMO that's not OK. Let's throw all features to the wall and see which users stick themselves to it may not be a good strategy here.
Again, it's goal is to cover lots of ground quickly, provide an overall impression, basic UX experience, and awaken curiosity (link to guides, refs, etc. for more deets).
This goal and presenting all DVC features might contradict time to time, and in that case I'd prefer this ⬆️ goal for GS and presenting DVC features in UG.
I'd like to have 3-5 distinct persona, for whom we write our content.
Sounds good but I think the GS is the one place where we may not need to worry about that too much. Let's make a separate issue or discuss separately?
Notion document seems fine for discussion, but I don't believe that's not important. GS docs are the most restrictive place we have to think about the audience I think. It's like a glass shop window where you present your most interesting items. We have a limited space and we need to think about who might stop and take a look to these items.
the purpose of get started is to have a document that people can get idea really quick from. It's more like a quick start. Thus - simple commands, hiding long explanations, etc.
I think we should rename the section to Quick Start if it's more like a quick start. "Get Started" has a "tutorial" feeling and that changes the focus to more in-depth explanations and detailed commands I think.
we should aim for 80% of the features that our user may need in their day to day
Agree. I meant major features, e.g. we don't even mention the run-cache (I think). Your criteria ☝️ is much better described.
GS docs are the most restrictive place we have to think about the audience
TBH Idk, it's not something we've been able to structure much so far. And we seem to be doing OK. But yes ideally we should get there and there's a corresponding direction in the roadmap.
Looks like everything else we discussed in-meeting so I assume no need to further discuss the other points.
Yesterday, in the meeting @shcheklein said the initial name for this section was Quick Start and was listing a bunch commands. Users wanted more hands-on, applicable, copy-pastable commands and the section evolved to its current form.
We decided to keep Get Started structure as is.
We decided to write a new Experiments section instead of the ongoing #2497.
I began to work with mind maps/concept maps/tree diagrams for this spike.
I don't know if you can open this link but we can discuss these in the meeting.
@jorgeorpinel @shcheklein @dberenbaum
A proposal for a new structure for the GS documents is like:
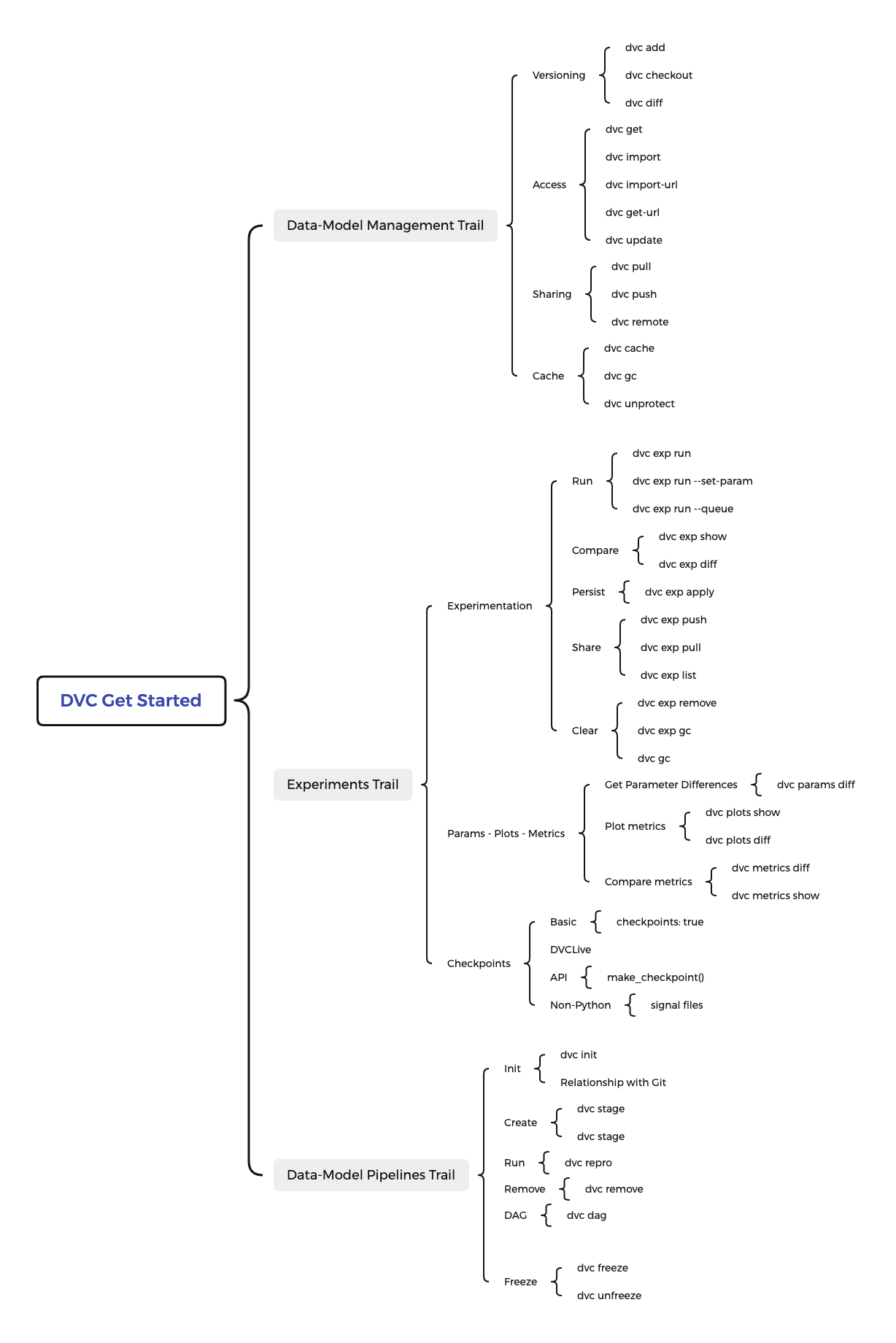
I like the term "Trail"!
Some parts look a bit too complicated (e.g. trying to cover all possible ways of doing checkpoints).