Feature Cycling Schedules
I am reading through the GAMI-Net paper referenced on the main page. This model trains on the "main effects" or 1st order terms first. Then in a 2nd iteration, trains the model on the residuals of the 1st order terms with the 2nd order terms.
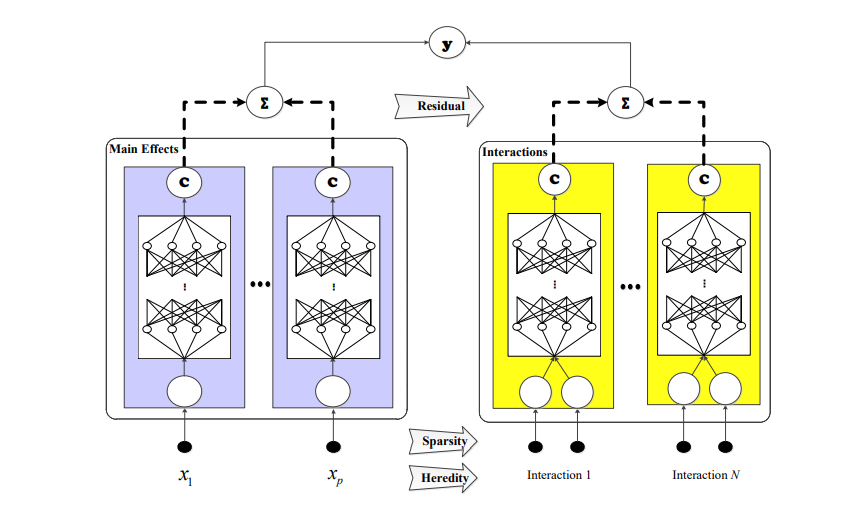
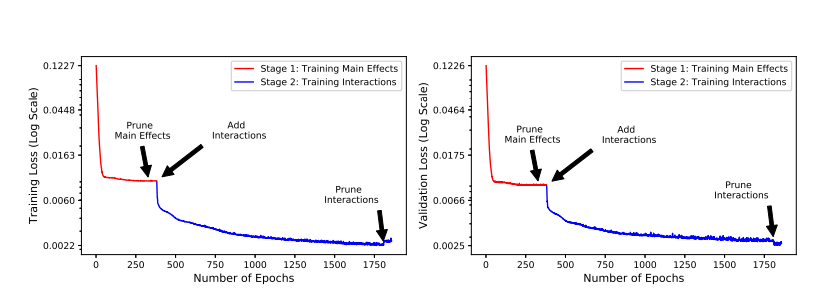
They believe that giving the first order terms allows the trained model to be more explainable - more of the information is contained in 1st order terms. Have you looked into this? Would you consider this as an option?
Additionally, I could see the use of a "smooth entry" for the 2nd order terms. For example: in iterations 2000 to 3000, you allow 1 in 4 trees to be 2nd order in iterations 3000 - 4000 you allow 1 in 3 in iterations 4000 - 5000 you allow 1/2
This would allow both the favouring of 1st order terms, but also the ability for 1st and 2nd order residuals to "learn together", IMO, giving a better chance to improving the final models accuracy.
Finally, as an added bonus, it would allow for a more direct comparison between EBM and GAMI-Net.
Hi @JoshuaC3,
Thanks for bringing up this detailed and interesting discussion! EBMs actually already do a stagewise training procedure of fitting main effects (or 1st order terms) first, and then secondarily detecting and fitting the pairwise interaction (or 2nd order) terms on the residuals. The full details for how the interaction detection and stagewise training processes work can be found in this KDD 2013 paper:
Training the low-order terms first is important for building an identifiable model -- any learned effect in a 1st order term can be represented inside a 2nd order term, which makes the interpretation of each term more difficult.
@blengerich and his co-authors have deeply studied this effect in this paper:
where the authors present a procedure for creating an identifiable model even when some of the main effects are "hidden" inside of pairwise interaction terms.
In addition, @blengerich has graciously contributed a nice utility for purifying interaction terms here: https://github.com/interpretml/interpret/pull/53 which outlines how to take any model with both main effects and pairwise interactions, and reduce it to a pure/identifiable form. You can run this code on EBMs from the interpret.glassbox.ebm.research namespace.
On the code side, Interpret currently only allows for stagewise training of interaction terms, and doesn't currently support training pairs "alongside" mains from the top level interface. It would be great to support a more flexible interface in the future that allows users to explore interesting ideas (like the "smooth entry" you describe), but we still have a fair amount of design work ahead of us to make that possible.
Hope you find some of the above links interesting, and thanks again for bringing up this interesting topic! -InterpretML Team
Hi, thank you so much for taking the time to write such a detailed reply. I either completely missed or totally forgot about this part: 4.2 Two-stage Construction when reading the paper. When reading the GAMI-Net paper I wrongly interpreted it as saying EBMs were trained in a single stage with both first and second order terms together. Thank you for clarifying!
While I think it would be an interesting feature, I can see the there are MANY other important features the EBM could benefit from first.
Here is the extra for future readers:
