Size of saved model checkpoints after trainer.train() is much larger when using trainer with deepspeed stage2
System Info
-
transformersversion: 4.28.0.dev0 - Platform: Linux-4.18.0-372.32.1.el8_6.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.16
- Huggingface_hub version: 0.13.3
- Safetensors version: not installed
- PyTorch version (GPU?): 1.12.1+cu116 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
Who can help?
@stas00 @sgugger
Information
- [X] The official example scripts
- [X] My own modified scripts
Tasks
- [x] An officially supported task in the
examplesfolder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below)
Reproduction
I'm using Trainer with deepspeed integration to fine-tune a Llama model.
This is the stage2 config im using:
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto"
}
So I'm using zero2 with optimizer offload. I found the size of the model checkpoints after trainer.train() become much larger than what they should be.
Using official run_clm.py script as an example :
deepspeed --num_gpus=1 run_clm.py \
--num_train_epochs 0.01 \
--model_name_or_path decapoda-research/llama-7b-hf \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size 2 \
--do_train \
--output_dir /tmp/test-plm \
--deepspeed ds_config.json
I add these two save_model lines around trainer.train() for testing:
trainer.save_model("test1")
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model("test2")
Now check the size:
du -sh test1
26G test1
du -sh test2
76G test2
Note, I have deleted global_step* folder in test2 before calculating the size.
I believe 26G is the correct size for an fp32 llama 7b. So, after training with trainer, the model size is wrong? Interestingly, seems the wrong size model still works with .from_pretrain.
I have located the issue raised after this line, which changed the model assignment in trainer _inner_training_loop here afterward. After this the model saved by trainer._save() will have the wrong size.
Does deepspeed engine add some extra things to pytorch_model.bin? is this expected?
My current solution to this is always using self.deepspeed.save_16bit_model() in trainer.save_model() for zerostage2:
elif self.deepspeed:
# this takes care of everything as long as we aren't under zero3
if self.args.should_save:
self._save(output_dir)
if is_deepspeed_zero3_enabled():
# It's too complicated to try to override different places where the weights dump gets
# saved, so since under zero3 the file is bogus, simply delete it. The user should
# either user deepspeed checkpoint to resume or to recover full weights use
# zero_to_fp32.py stored in the checkpoint.
if self.args.should_save:
file = os.path.join(output_dir, WEIGHTS_NAME)
if os.path.isfile(file):
# logger.info(f"deepspeed zero3: removing {file}, see zero_to_fp32.py to recover weights")
os.remove(file)
# now save the real model if stage3_gather_16bit_weights_on_model_save=True
# if false it will not be saved.
# This must be called on all ranks
if not self.deepspeed.save_16bit_model(output_dir, WEIGHTS_NAME):
logger.warning(
"deepspeed.save_16bit_model didn't save the model, since"
" stage3_gather_16bit_weights_on_model_save=false. Saving the full checkpoint instead, use"
" zero_to_fp32.py to recover weights"
)
self.deepspeed.save_checkpoint(output_dir)
else:
if self.args.should_save:
for filename in os.listdir(output_dir):
full_filename = os.path.join(output_dir, filename)
# If we have a shard file that is not going to be replaced, we delete it, but only from the main process
# in distributed settings to avoid race conditions.
weights_no_suffix = WEIGHTS_NAME.replace(".bin", "").replace(".safetensors", "")
# delete everything start with weights_no_suffix, usually are "pytorch_model".
if (
filename.startswith(weights_no_suffix)
and os.path.isfile(full_filename)
):
os.remove(full_filename)
self.deepspeed.save_16bit_model(output_dir, WEIGHTS_NAME)
Expected behavior
Model checkpoint size should be unchanged after trainer.train()
deepspeed saves the optimizer states as well as fp32 master weights, so of course the checkpoint folder is larger. look at the contents of the saved checkpoint folder.
I'm not quite sure what the problem is.
@stas00 thanks for the reply. are these states are saved in the pytorch_model.bin file?
no, they are saved in their own files under global_step*. You might want to inspect the contents of the folder.
Please feel free report the full listing and their sizes here if you'd like to continue this discussion more specifically.
Hi, here are the file sizes in each folder:
du -a -h --max-depth=1 test1
496K test1/tokenizer.model
512 test1/config.json
32K test1/pytorch_model.bin.index.json
16K test1/training_args.bin
512 test1/tokenizer_config.json
512 test1/special_tokens_map.json
9.2G test1/pytorch_model-00001-of-00003.bin
9.3G test1/pytorch_model-00002-of-00003.bin
6.7G test1/pytorch_model-00003-of-00003.bin
512 test1/generation_config.json
26G test1
du -a -h --max-depth=1 test2
496K test2/tokenizer.model
512 test2/config.json
32K test2/pytorch_model.bin.index.json
16K test2/training_args.bin
512 test2/tokenizer_config.json
512 test2/special_tokens_map.json
26G test2/pytorch_model-00001-of-00003.bin
26G test2/pytorch_model-00002-of-00003.bin
26G test2/pytorch_model-00003-of-00003.bin
512 test2/generation_config.json
76G test2
So, the pytorch_model.bin files are much larger. Although there is a max file size of 10g that has been set for the second save, it still exceeds the file size. I guess something is wrong there?
no, they are saved in their own files under
global_step*. You might want to inspect the contents of the folder.Please feel free report the full listing and their sizes here if you'd like to continue this discussion more specifically.
I call trainer.save_model() manually and Im using stage2, so global_step* is not created. but indeed these folders will be created in checkpoints saving during training. Btw, is there any way to skip saving global_step* for stage2? this folder is extremely large and I think may not necessarily be needed for fine-tune cases.
oh, thank you! now that you're showing the actual file sizes, it's much easier to see what you're talking about. Indeed this looks wrong.
I have seen this happening in one situation where saving not updating the tensor's data structure. I wrote a script to fix that. Can you run this script and see if the shrink to a normal size? https://github.com/stas00/toolbox/blob/master/pytorch/torch-checkpoint-shrink.py
Then we can look at the cause.
Hi @stas00 seems your tool can only support .pt files? can you give me more instructions on how to use it for transformer checkpoints folder? thanks!
Hi @stas00 seems your tool can only support
.ptfiles? can you give me more instructions on how to use it for transformer checkpoints folder? thanks!
Never mind, I modified your script and it works now. Indeed it gets back to the correct size after shrinking:
python3 torch-checkpoint-shrink.py --checkpoint_dir test2/ --patterns "pytorch_model*.bin"
Processing zero checkpoint 'test2/'
-> test2/pytorch_model-00001-of-00003.bin
-> test2/pytorch_model-00002-of-00003.bin
-> test2/pytorch_model-00003-of-00003.bin
Done. Before 77115.10MB, after 25705.12MB, saved 51409.98MB
du -a -h --max-depth=1 test2
496K test2/tokenizer.model
512 test2/config.json
32K test2/pytorch_model.bin.index.json
16K test2/training_args.bin
512 test2/tokenizer_config.json
512 test2/special_tokens_map.json
9.2G test2/pytorch_model-00001-of-00003.bin
9.3G test2/pytorch_model-00002-of-00003.bin
6.7G test2/pytorch_model-00003-of-00003.bin
512 test2/generation_config.json
26G test2
So I bet the problem is this...
Wonderful. It was fixed in PP saving code in Deepspeed at https://github.com/microsoft/DeepSpeed/pull/1324 when I first seen this problem in Megatron-Deepspeed a year ago.
So probably need to do the same for ZeRO. Would you like to try replicating the above fix for ZeRO? Basically the need is to reclone the tensors, so they are recreated with the final actual size of the storage.
It should be pretty simple to do, by applying the same change of the PR above to this line:
https://github.com/microsoft/DeepSpeed/blob/036c5d6d7b6028853a4e15ef3f5df466ba335f33/deepspeed/runtime/checkpoint_engine/torch_checkpoint_engine.py#L20
and then test that your issue goes away, file a PR with Deepspeed and become a Deepspeed committer ;)
actually, it will require a bit of efficiency changes to it. PP was already having small state_dict so it wasn't a problem to clone tensors in small groups. But here it'd be very expensive as it'd end up having 2 copies of the model, which can be huge. So I won't use dict comprehension and instead loop normally over the state_dict and clone and immediately overwrite the tensor - one tensor at a time. So the overhead will be one largest tensor and not 2x state_dict
hmm, but deepspeed doesn't do checkpoint sharding, those shards come from transformers:
32K test2/pytorch_model.bin.index.json
9.2G test2/pytorch_model-00001-of-00003.bin
9.3G test2/pytorch_model-00002-of-00003.bin
6.7G test2/pytorch_model-00003-of-00003.bin
So I am actually not sure that the suggestions I gave you is the right one. I looked at the code you shared, but that's not the code that HF Trainer runs. So we need to do that cloning there instead I think.
Yeah, the code I shared is my temporary fix for this issue, using self.deepspeed.save_16bit_model(output_dir, WEIGHTS_NAME) gives the correct size pytorch_model.bin file, but indeed will save in a single file, not sharded.
I think state_dict should be re-cloned right after this line:
https://github.com/huggingface/transformers/blob/84a6570e7bce91ba7d18c0782186241c5f1fde75/src/transformers/trainer.py#L2872
Please check if I got to the right code branch, I'm doing it by reading the code - so possibly I got it wrong.
I think
state_dictshould be re-cloned here:https://github.com/huggingface/transformers/blob/84a6570e7bce91ba7d18c0782186241c5f1fde75/src/transformers/trainer.py#L2873
Please check if I got to the right code branch, I'm doing it by reading the code - so possibly I got it wrong.
but I think here cannot solve for the PreTrainedModel classes? Im afraid need to change save_pretrained here https://github.com/huggingface/transformers/blob/84a6570e7bce91ba7d18c0782186241c5f1fde75/src/transformers/modeling_utils.py#L1761 in PreTrainedModel if we want to fix for transformers models
so I tried this in save_pretrained and it works
# Save the model
if state_dict is None:
# state_dict = model_to_save.state_dict()
orig_state_dict = model_to_save.state_dict()
state_dict = type(orig_state_dict)(
{k: v.clone()
for k,
v in orig_state_dict.items()})
Excellent, but we can't do that in save_pretrained since we don't want everybody paying a penalty because of a special case.
So let's go up the call stack and find where it needs to be called for the deepspeed case only. I think my suggestion should be around the right place. just need to add if deepspeed.
Actually, let's ping @tjruwase - Tunji any idea why we get the tensors bloated in the model during zero-2 w/ optim offload when they are saved? Remember we had that issue in PP in Megatron-Deepspeed and we had to re-clone the model's state dict? https://github.com/microsoft/DeepSpeed/pull/1324 So it seems @ArvinZhuang is hitting this same issue with ZeRO-2. Since the model is not sharded and the saving happens outside of Deepspeed, this is just torch.save(module.model.state_dict()), I am not sure how this can be fixed on the deepspeed side.
The bloating is about 2.5x times of the real size, you can see the good and the bad cases here: https://github.com/huggingface/transformers/issues/22822#issuecomment-1513853704 and my checkpoint shrinking post-processing workaround restores the normal size.
Does this perhaps have anything to do with offloading? But only the optimizer is offloaded here - so I don't see a connection.
@ArvinZhuang, could you try with a smaller model and test whether the bloating goes away if you don't use offload? And perhaps w/o deepspeed at all just to validate if the issue is indeed coming from deepspeed. But most likely it is.
Good point @stas00, I have tried several things already. Using gpt-2 (a small model) with deepspeed does not have this problem. LLaMa Without using deepspeed does not have this problem (was using fsdp). Unfortunately, I don't have enough GPU memory to run without offloading, so I cannot test
I can confirm that for llama case the issue comes from here https://github.com/huggingface/transformers/blob/84a6570e7bce91ba7d18c0782186241c5f1fde75/src/transformers/deepspeed.py#L378
After giving the model to deepspeed initial then the model.save_pretrained() will have the wrong size. Model savings before this line are correct.
@stas00 Probably we can change this line https://github.com/huggingface/transformers/blob/84a6570e7bce91ba7d18c0782186241c5f1fde75/src/transformers/trainer.py#L2804
to
if self.args.should_save:
state_dict = self.model.state_dict()
state_dict = type(state_dict)(
{k: v.clone()
for k,
v in state_dict.items()})
self._save(output_dir, state_dict=state_dict)
This will only affect saving behavior of deepspeed. and I tested it also works.
Excellent. That is the right place, @ArvinZhuang
But since the issue comes from Deepspeed, let's see if perhaps the cause can be removed there in the first place, since if we fix it directly in HF Trainer it'll still have this problem in any other training loop. Like Accelerate and any custom user training loop. Let's first wait for Tunji to respond.
The other option is to file your repro with saving before and after directly at https://github.com/microsoft/DeepSpeed/issues since clearly the issue is coming from there.
The shortest repro to send there is probably something like this (untested):
ds_config = {
"zero_optimization": {
"stage": 2,
},
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"train_batch_size": "1",
"train_micro_batch_size_per_gpu": "1"
}
model = ...from_pretrained("decapoda-research/llama-7b-hf")
model.save_pretrained("before")
deepspeed_engine, _* = deepspeed.initialize(model=model, config_params=ds_config)
deepspeed_engine.module.save_pretrained("after")
please fill in the missing bits, but I think that's all that is needed. I am not sure if optimizer/schedulers are even needed, but it'll assign the defaults.
I hope the above indeed reproduces the issue.
oh, thank you! now that you're showing the actual file sizes, it's much easier to see what you're talking about. Indeed this looks wrong.
I have seen this happening in one situation where saving not updating the tensor's data structure. I wrote a script to fix that. Can you run this script and see if the shrink to a normal size? https://github.com/stas00/toolbox/blob/master/pytorch/torch-checkpoint-shrink.py
Then we can look at the cause.
I use the script, but the pt file not change
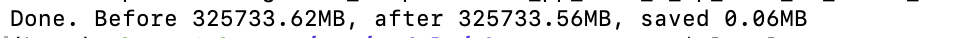
Hi @lw3259111 , what is your setting? like which model, deepspeed config, etc.
@ArvinZhuang I use llama 33B model and the deepspeed config is :
{
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": false
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 5,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
Please note the discussion continues here: https://github.com/microsoft/DeepSpeed/issues/3303#issuecomment-1516798523
We understand well the cause of the problem - explained at https://github.com/microsoft/DeepSpeed/issues/3303#issuecomment-1516801635
This impacts only z1/z2 models that are sharded.
Apparently, FSDP has the same issue.
So the 2 workarounds for now are:
- edit
save_pretrainedcall to dosave_pretrained(..., max_shard_size=100GB)- this will create a single shard which won't have any bloat - just choose anymax_shard_sizebigger than the model size. - Use the full clone solution here https://github.com/huggingface/transformers/issues/22822#issuecomment-1514096667 you might want to move the cloned tensors to cpu - i.e.
v.clone().cpu()as you are likely not to have enough memory of gpu
@stas00 I remember I was using FSDP and it saves the correct size model shards. I feel the issue only happens with deepspeed.
I was just relaying a report from someone else reporting the same problem with FSDP. Perhaps it depends on circumstances.
But it doesn't matter who else has this problem. This one will get fixed as soon as the Deepspeed side provides a utility for shrinking the state_dict and makes a new release.
Please note the discussion continues here: microsoft/DeepSpeed#3303 (comment)
We understand well the cause of the problem - explained at microsoft/DeepSpeed#3303 (comment)
This impacts only z1/z2 models that are sharded.
Apparently, FSDP has the same issue.
So the 2 workarounds for now are:
- edit
save_pretrainedcall to dosave_pretrained(..., max_shard_size=100GB)- this will create a single shard which won't have any bloat - just choose anymax_shard_sizebigger than the model size.- Use the full clone solution here Size of saved model checkpoints after trainer.train() is much larger when using trainer with deepspeed stage2 #22822 (comment) you might want to move the cloned tensors to cpu - i.e.
v.clone().cpu()as you are likely not to have enough memory of gpu
@stas00 when I cloned tensors to CPU, The saved model is only 400M, my code:
def safe_save_model_for_hf_trainer(trainer: transformers.Trainer,
output_dir: str):
"""Collects the state dict and dump to disk."""
state_dict = trainer.model.state_dict()
if trainer.args.should_save:
cpu_state_dict = {
key: value.cpu()
for key, value in state_dict.items()
}
del state_dict
trainer._save(output_dir, state_dict=cpu_state_dict) # noqa
please reread the comment you quoted - it says clone and then optionally move to cpu. Your code is missing the key operation.
please reread the comment you quoted - it says
cloneand then optionally move to cpu. Your code is missing the key operation.
I am using the following code, but I still cannot save the model properly,code:
def safe_save_model_for_hf_trainer_clone(trainer: transformers.Trainer,
output_dir: str):
"""Collects the state dict and dump to disk."""
state_dict = trainer.model.state_dict()
if trainer.args.should_save:
cpu_state_dict = type(state_dict)(
{k: v.cpu().clone()
for k,
v in state_dict.items()})
del state_dict
trainer._save(output_dir, state_dict=cpu_state_dict) # noqa
or
def safe_save_model_for_hf_trainer_clone(trainer: transformers.Trainer,
output_dir: str):
"""Collects the state dict and dump to disk."""
state_dict = trainer.model.state_dict()
if trainer.args.should_save:
cpu_state_dict = type(state_dict)(
{k: v.clone().cpu()
for k,
v in state_dict.items()})
del state_dict
trainer._save(output_dir, state_dict=cpu_state_dict) # noqa
the result:


@lw3259111 this problem seems only occurs with deepspeed Zero1/2, and a large model saved with shared checkpoints. Your setting and model may not have this issue.