Add a ControlNet model & pipeline
ControlNet by @lllyasviel is a neural network structure to control diffusion models by adding extra conditions. Discussed in #2331.

Done at PoC level, but there's still work to be done at the product level, so I'll continue as WIP.
Usage Example:
from diffusers import StableDiffusionControlNetPipeline
from diffusers.utils import load_image
# Canny edged image for control
canny_edged_image = load_image(
"https://huggingface.co/takuma104/controlnet_dev/resolve/main/vermeer_canny_edged.png"
)
pipe = StableDiffusionControlNetPipeline.from_pretrained("takuma104/control_sd15_canny").to("cuda")
image = pipe(prompt="best quality, extremely detailed", controlnet_hint=canny_edged_image).images[0]
image.save("generated.png")
TODO:
- [x] Conflict fixes
- [x] Add utility function to generate control embedding: controlnet_hinter
- [x] Docstring fixes
- [ ] Unit test fixes and additions to acceptable
- [ ] Test with other ControlNet models (probably subjective comparative evaluation with references)
- [ ] (time permitting) Investigate why pixel matches are not perfect
Discussion:
- How to provide users with functions to create control embedding? The reference implementation is highly dependent on other libraries, and porting it without thought will increase the number of dependent libraries for Diffusers. From my observations, the most common use case is not Canny Edge conversion, but rather inputting a similar line drawing image (for example), or generating an OpenPose compatible image (for example) and then inputting that image. In such use cases, it may be acceptable to prepare only a minimal conversion from the image. -- one idea: controlnet_hinter
- There is little difference between
StableDiffusionPipelineand the (newly added)StableDiffusionControlNetPipeline. I think it would be preferable to change the behavior ofStableDiffusionPipelineinstead of creating a newStableDiffusionControlNetPipeline. - How much test code is required? Diffusers does a lot of coverage testing, which is great, but I'm having a hard time physically doing this amount of coding. I would appreciate it if someone could help me.
- I currently have the converted models on my Huggingface hub, which I think is more appropriate for the @lllyasviel account. I would appreciate it if Huggingface team could support on release.
@williamberman @apolinario @xvjiarui
The documentation is not available anymore as the PR was closed or merged.
Solution found: I didn't force-reinstall diffusers with pip so I was working off old code. It's loading in Unreal now.
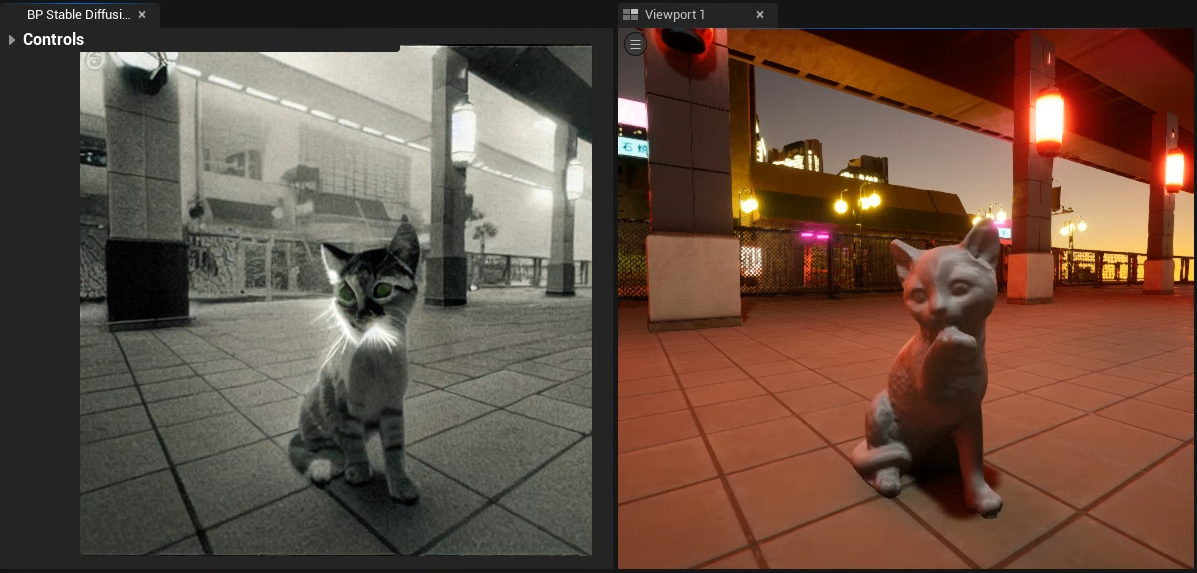
Super appreciate the work you've put into implementing this so far. I'm looking forward to feeding the normal and depth map models with maps captured straight out of Unreal!
Would it be possible to use other base models as what's being done in SD WebUI a1111?
Can confirm that the PR works with the normal map model as well but channels need to be reversed from RGB to BGR for the control_hint image (bottom right normal map is what works).
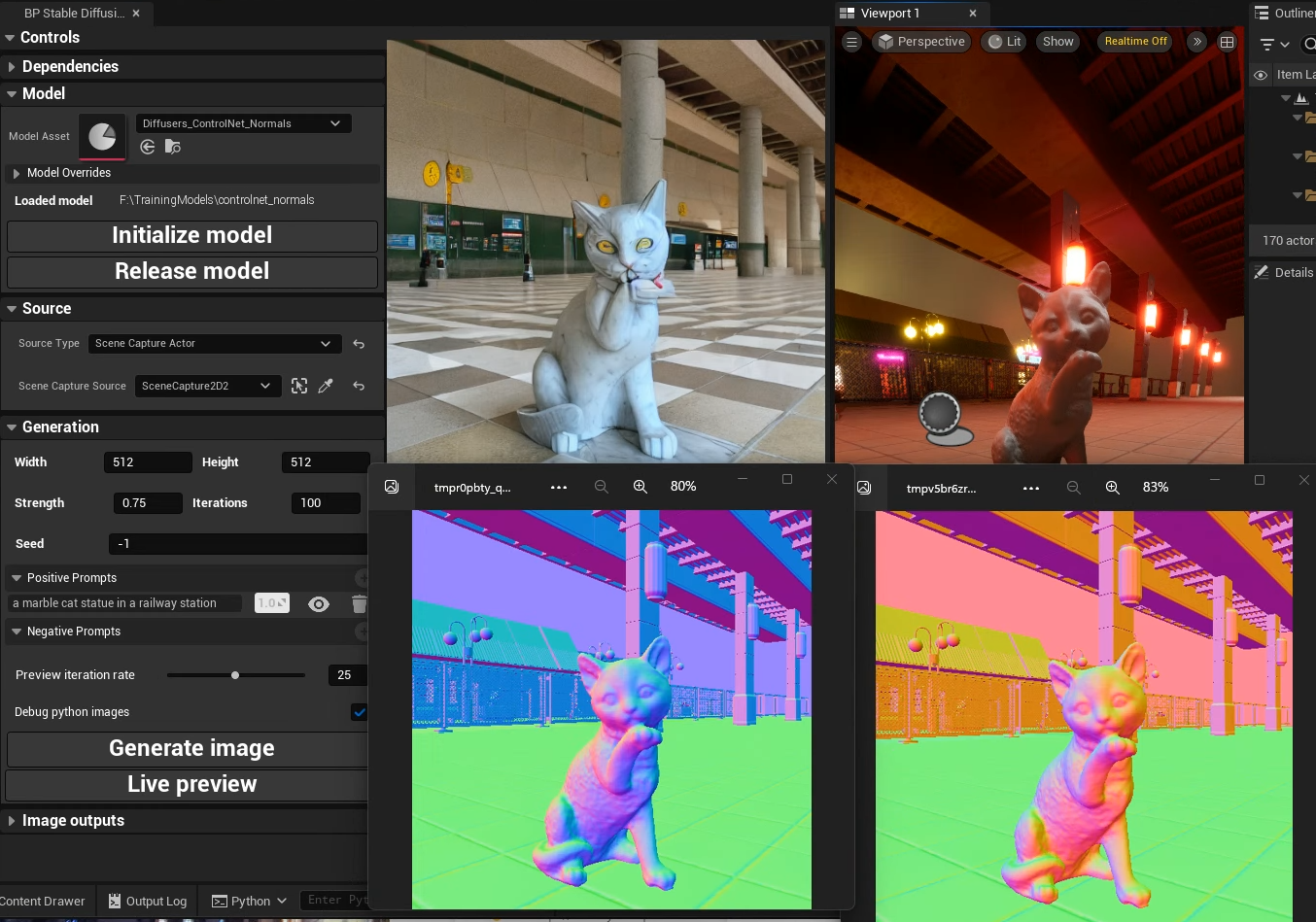
Hi! I find minary mistake in convert_controlnet_to_diffusers.py. It have to change date from 2022 to 2023. scripts/convert_controlnet_to_diffusers.py
Hey @takuma104 this seems wonderful. I am new to this and wanted to understand how can I include a model of my choice in this pipeline along with controlnet. The idea is to create something similar to the webui but which runs in a notebook directly without the UI.
@takuma104 I love this awesome code and think that it can be improved. Therefore, I added the automatic prompt(BLIP) to the code(automatic prompt is implemented in the paper!). It is not perfect because the code is not neat. However, it works well. I add the code automatic prompt in Colab. You can see the code in Colab.
Make it more convenient for users
In the paper :
(3) Automatic prompt: In order to test the state-of-the-art maximized quality of a fully automatic pipeline, we also try to use automatic image captioning methods (e.g., BLIP [34]) to generate prompts using the results obtained by “default prompt” mode. We use the generated prompt to diffusion again.

I tested the difference using the default Colab prompt and the automatic prompt. test
Update a useful resource based on this PR for those who want to replace basemodel of ControlNet and infer it in diffusers.
@cjfghk5697 Thank you for the verification! Integrating with BLIP seems promising, but it may be difficult to add a function to Diffusers. As a dependency library, BLIP itself is not distributed as a pip package. It would be great if timm or transformers had an implementation of BLIP...
As a solution to this library dependency issue, I'm personally creating an image preprocessing library separate from Diffusers. I thought I should add a feature to it. After the PR is done, I'll refer to the code and write it.
@haofanwang Thanks for the tutorial! For the transfer, the method you explained is nice. I'm also trying to transfer models using this method.
Swapping only UNet more quickly may not be the right method, but I think it will work. There's also a proposal to significantly change the API, so depending on the situation, this may become a more understandable method. (For example, loading an existing Anything model with pipe as usual and controlling it with any ControlNet loaded separately. It's the opposite of the current method.)
@takuma104
Thank you for the reply. Absolutely understand why difficult to add a function in Diffusers. If you create an image preprocessing library, wish to help your project.
I try now for combining BLIP and ControlNet in the other repository. Probably, it could help your preprocessing library. If the opportunity arises, I will try to contribute to the next project.
Thank you again
repo_id="huggingfaceuser/zwx-person"
huggingface_token="hf_accesstoken"
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse", torch_dtype=torch.float16).to("cuda")
unet = UNet2DConditionModel.from_pretrained(repo_id, use_auth_token=huggingface_token, subfolder="unet", torch_dtype=torch.float16).to("cuda")
text_encoder = CLIPTextModel.from_pretrained(repo_id, use_auth_token=huggingface_token, subfolder="text_encoder", torch_dtype=torch.float16)
pipe_canny = StableDiffusionControlNetPipeline.from_pretrained( "takuma104/control_sd15_canny", text_encoder=text_encoder, vae=vae,safety_checker=None,unet=unet, torch_dtype=torch.float16).to("cuda")
pipe_canny.scheduler = euler_scheduler
pipe_canny.enable_xformers_memory_efficient_attention()
This code is working great for custom Dreambooth diffusers models on Huggingface, it also works well with the pose model.
@atomassoni Nice! Your code is an elegant solution. Using this method is more efficient because it avoids downloading unnecessary files, unlike simply assigning
pipe = StableDiffusionControlNetPipeline.from_pretrained("takuma104/control_sd15_canny")
and then retrofitting to pipe.unet, etc.
Intuitively, I wanted to use the pipeline like this FWIW:
pipe = StableDiffusionControlNetPipeline.from_pretrained("huggingfaceuser/zwx",controlnet="takuma104/control_sd15_canny")
or even be able to add the controlnet && controlnet_hint to other stable diffusion pipelines
The current implementation cannot support any-size control hint image. But it's supported in the original ControlNet. Can you solve this issue? @takuma104
@atomassoni
even be able to add the controlnet && controlnet_hint to other stable diffusion pipelines
We have been discussing a proposal to allow passing ControlNet to StableDiffusionPipeline in #2331.
@federerjiang
Currently, an error is raised if the image specified in controlnet_hint does not match the width and height arguments of pipe(). To be able to handle any image size, it may be a good idea to add one line of Image.resize() code. Currently, you can generate an image by setting the width and height to the same size as the input image.
it seems like using num_images_per_prompt>1 will cause error "The size of tensor a (4) must match the size of tensor b (2) at non-singleton dimension 0"
Hey @takuma104 sorry for the delay, started taking a look and making some changes here: https://github.com/huggingface/diffusers/pull/2475
I think the main changes are turning controlnet into its own model independent of the unet
@XavierXiao Thanks for the report! There is indeed a bug here. I will fix it.
@williamberman Oh, that's a neat solution. By separating ControlNet from Unet, it minimizes the changes to UNet2DConditionModel, right? Please let me know when your work settles down. I'll work on fixing bugs in the pipeline.
@williamberman Oh, that's a neat solution. By separating ControlNet from Unet, it minimizes the changes to UNet2DConditionModel, right? Please let me know when your work settles down. I'll work on fixing bugs in the pipeline.
Yep, it's a cleaner integration imo
ideally, would it be possible for you to force push back to the commit that I forked from (I think I also have permission to force push the branch but don't want to surprise anyone)? Then we could merge my branch in here to get reviews and get it merged prob within a few days :) The only remaining work is integration tests
@williamberman Sure, I was able to merge your repository updates on my local. There were some conflicts around the area I was working on today, so once I've fixed them, I'll push the changes here.
- Inference API changed.
controlnet_hintargument on pipe() is nowimage.
Previous:
pipe = StableDiffusionControlNetPipeline.from_pretrained("takuma104/control_sd15_canny").to("cuda")
image = pipe(prompt="best quality, extremely detailed", controlnet_hint=canny_edged_image).images[0]
Now:
pipe = StableDiffusionControlNetPipeline.from_pretrained("takuma104/control_sd15_canny").to("cuda")
image = pipe(prompt="best quality, extremely detailed", image=canny_edged_image).images[0]
- New conversion script: (integrated to
convert_original_stable_diffusion_to_diffusers.py)--controlnetoption added.
Usage Example:
python ../diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py \
--original_config_file ../ControlNet/models/cldm_v15.yaml \
--checkpoint_path $1 --to_safetensors --controlnet --dump_path $2
Getting the following error when testing on a Mac, and since it passes on Ubuntu, I have a feeling that I'm stepping on a difficult bug...
FAILED StableDiffusionControlNetPipelineFastTests::test_stable_diffusion_controlnet_ddim_two_images_per_prompt -
AssertionError: assert 0.09017732169609072 < 0.01
FAILED StableDiffusionControlNetPipelineFastTests::test_stable_diffusion_controlnet_ddim_two_prompts -
AssertionError: assert 0.08504155400733948 < 0.01
could you add guess mode into this PR? https://github.com/lllyasviel/ControlNet/commit/005008b44d9a29725310a19bd173a509fabcdd30