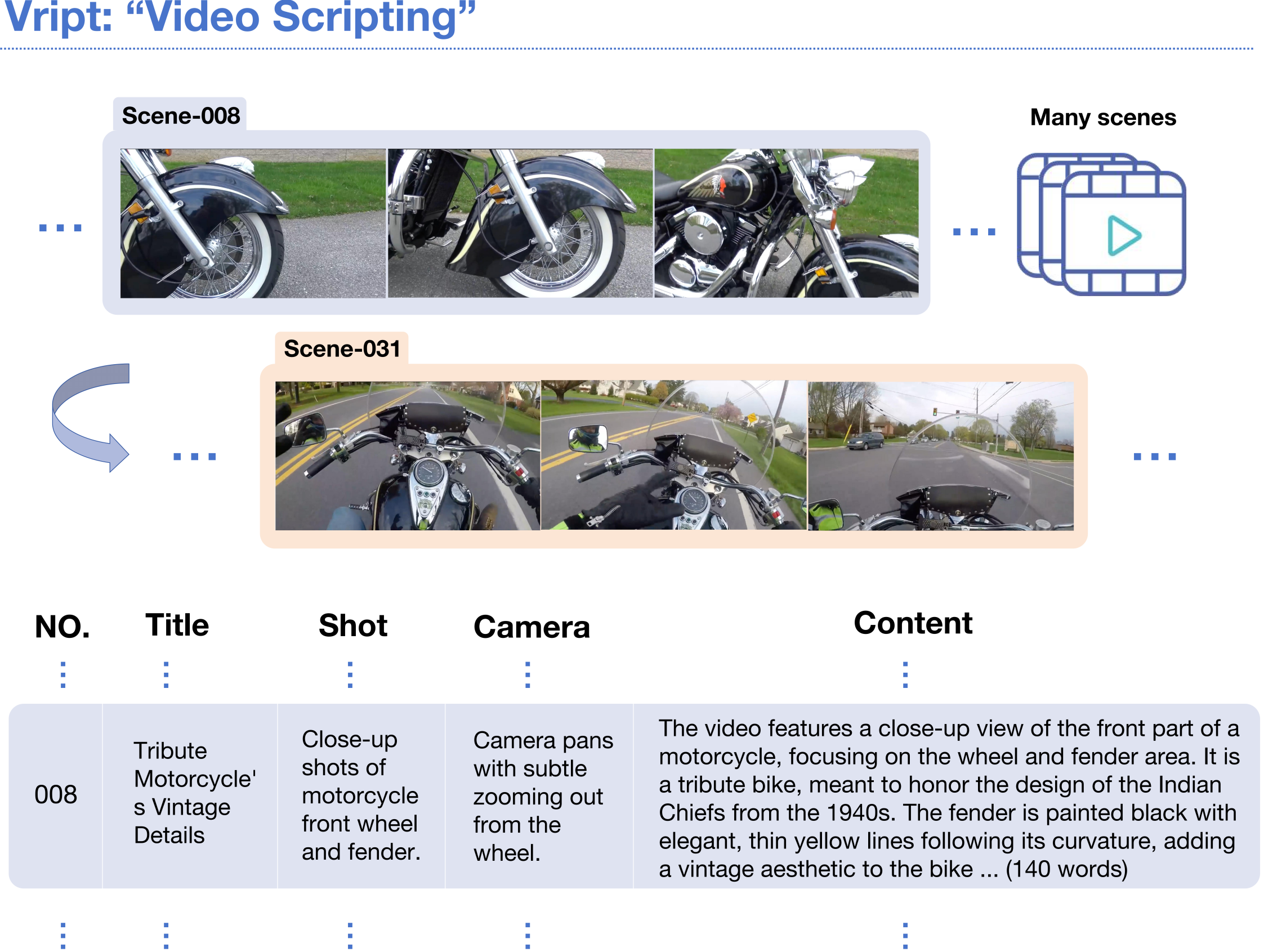
A new high-quality video-text dataset 新的高质量视频文本数据集
Open
mutonix
opened this issue 1 year ago
•
0 comments
We recently open-sourced a new fine-grained video-text dataset with 12K annotated high-resolution videos (~400k clips), called Vript, which may contribute to improving the open-sora models.