About Training Settings
Can you provide init training and finetune training settings?
model config, data config, not just table1 in the paper.
e.g. whether use struct model? whether enable template? whether use extra msa?
thx.
Thank you for your interest. FastFold currently provides a high-performance distributed Evoformer implementation, which can be used with OpenFold if a complete training process is required. You can refer to OpenFold for specific training configurations.
@Shenggan thx for your reply.
I want to know what configs to run in init training and finetune so that the paper can get init training 2.487s/step, 4.153s/step, and finally training alphafold2 in 67 hours.
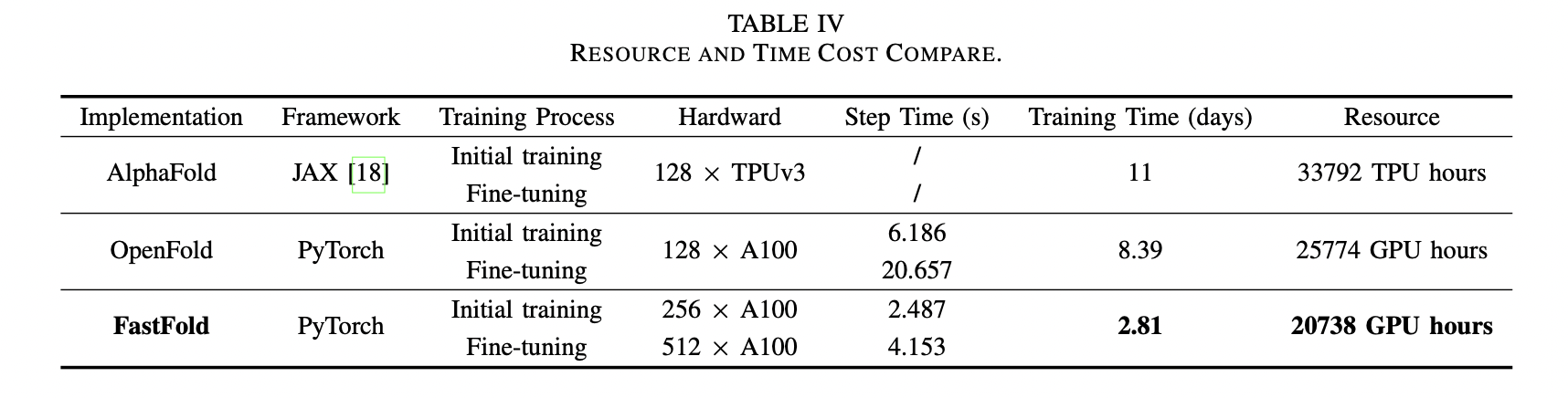
Hi, @Shenggan. I want to know the settings below:
- MSA representation and pair representation shape in initial training and finetune training
- whether you enable template in initial training and finetune training?
- whether you enable extra MSA stack in initial training and finetune training?
- whether you enable structure model in initial training and finetune training?
- whether you use recycling in initial training and finetune training? and num_recycle=?
- whether you remove checkpoint(recompute) when you use dap=2 or dap=4 in initial training and finetune training?
thx!
For the first to fifth points, we use the same settings as AlphaFold/OpenFold, template, extra MSA stack, structure model, and recycling are all turned on, and the number of recycling is uniformly distributed from 1 to 4 times. For the sixth point, we can only turn off recomputing in the case of initial training with dap=4.