[BUG]: LoRA still does not support the training of reward models
🐛 Describe the bug
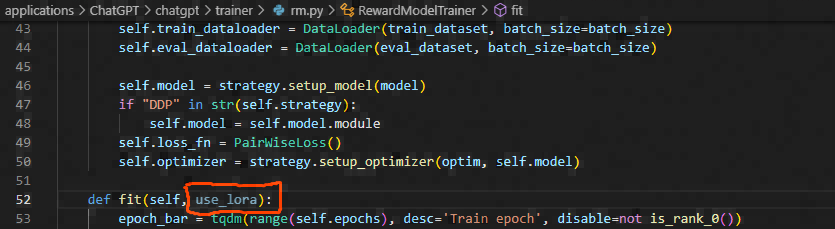
Although ht-zhou said that the LoRA problem has been fixed, according to the latest code and experimental tests of ColossalAI, LoRA still does not support the training of the reward model.
I read his modifications, I don't think those modifications can fix the problem, and I noticed that the latest main version of ColossalAI removed the use of LoRA during rm model training, and now I think ColossalAI does not support LoRA at all, right?
Environment
env
OS:ubuntu 20.04 GPU:4 x A10 python==3.9.0 torch==1.13.1-cu116 colossalai==0.2.5
command
python train_reward_model.py --pretrain "bigscience/bloom-560m" --lora_rank 16
Bot detected the issue body's language is not English, translate it automatically. 👯👭🏻🧑🤝🧑👫🧑🏿🤝🧑🏻👩🏾🤝👨🏿👬🏿
@ht-zhou
Thank you for your feed back, it is fixed and we use lora_rank when initialize model.
