ColossalAI

ColossalAI copied to clipboard
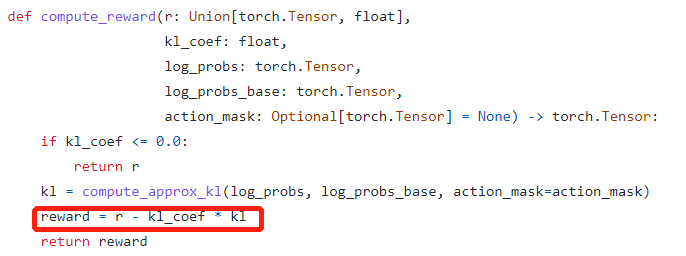
[BUG]: ChatGPT: why total reward is reward = r - kl_coef * kl, not total_reward=r + gamma * critic(next_states)?
🐛 Describe the bug
ChatGPT: why total reward is reward = r - kl_coef * kl, not total_reward=r + gamma * critic(next_states)?
Environment
No response
Because as we think, the rl training process here is a one-step process, which means there isn't a next_state.
I'll close this issue now, please reopen the issue if you have further questions.