[BUG]: an instance of 'c10::CUDAErrorc10::CUDAError' initialization error
🐛 Describe the bug
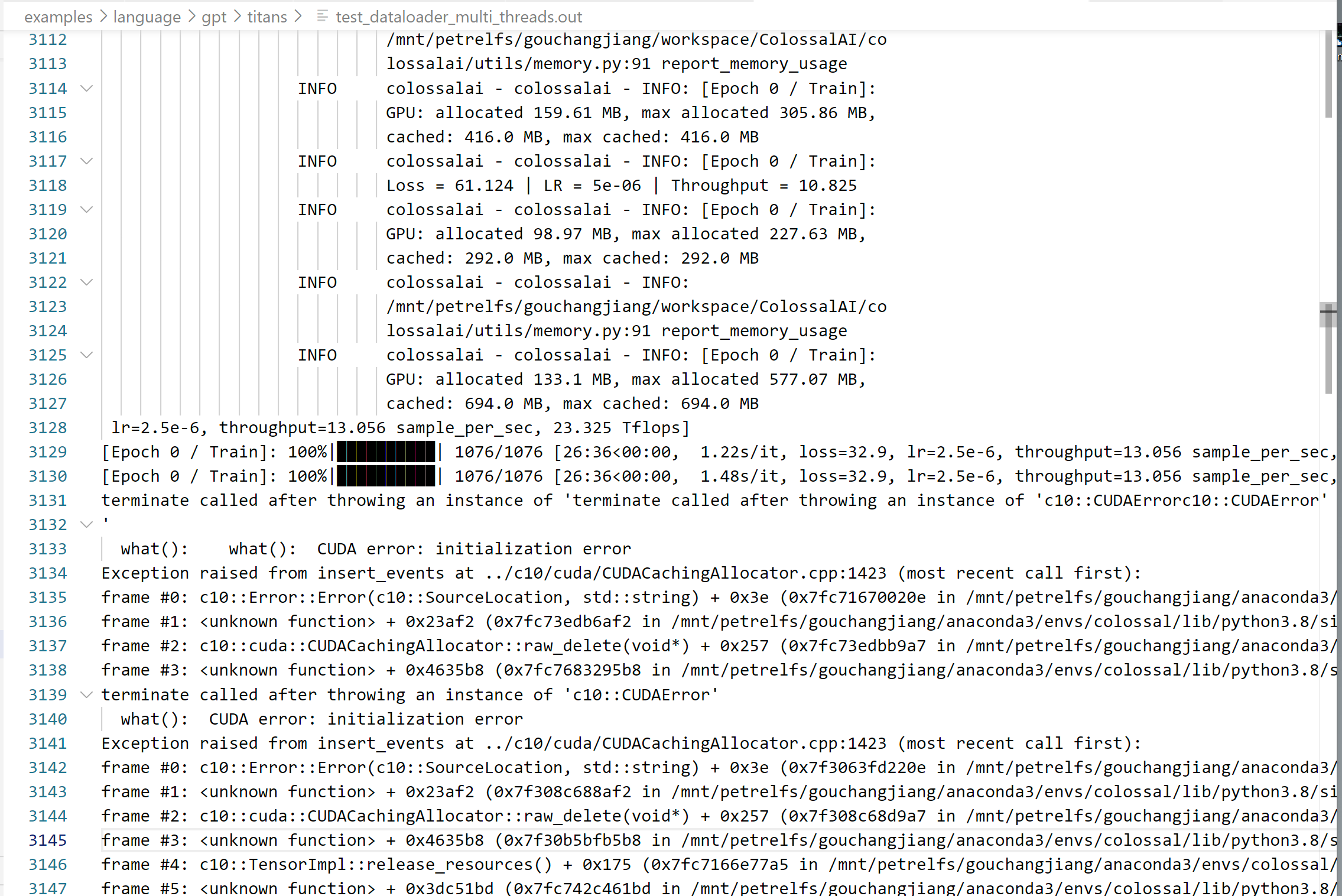
I encountered this problem when running the examples/language/gpt/titans/train_gpt.py using real data provided by the example. This probelm only occurs when we set the argument 'num_workers' of function 'get_dataloader' strictly larger than 0, say 4 in my case. It appears as soon as the end of the first epoch. I did the search on the internet. Someone says that it's because we load the data into GPU device before the dataloader. But that's not the case in the train_gpt.py. Below is the log:
Environment
CUDA 11.3 + 1.12.1+cu113 + Colossal-AI 2.0.0 installed from github.

Hello, the actual reason was when using dummy dataset, data is generated randomly and it does not make sense to use multiple workers to load data from anywhere.
Multiple workers (hence multiple dataloaders) will support data to CUDA. And one of the subprocesses may submit data earlier than the main process, causing CUDA initialization error.
To avoid this issue, kindly download real dataset via link and remove the --use_dummy_dataset flag.
Thanks for the kind reply. Instead of using dummy data, I am using the real data provided by the link given. To double check it, the 'else' clause block in class 'WebtextDataset' is replaced by an assert that will cause a problem if it does not read real data.
I will continue to dig it from the direction you pointed: a process of dataloader has been killed.
Hi @gouchangjiang Did you solve it? This issue was closed due to inactivity. Thanks.
Multiple workers (hence multiple dataloaders) will support data to CUDA. And one of the subprocesses may submit data earlier than the main process, causing CUDA initialization error.
@gouchangjiang @binmakeswell Hello, this error can be avoided by num_workers=0. However, this will slow down the data reading speed. So is there a better solution?