[FEATURE]: Clear Instruction for Checkpoint
Describe the feature
For users, tutorial and code of checkpointing are not clear enough how to use checkpoint. The code comments are misleading.
Our checkpointing mainly focus on handing model. But users also needs optimizer and lr scheduler states, which is required load_state_dict.
Yes, users hope to have a demo to show how to save (and load) the states of the model, optimizer, and lr scheduler in hybrid parallel scenarios, so as to continue training from the last checkpoint after a downtime.
I suggest add an example in examples/language/gpt.
用户反馈:目前ColossalAI在如何保存(和加载)混合并行模式下(zero3+tensor+流水线)的优化器和lr调度器参数还没有一个完整的example,这个特性对宕机后从最后一个checkpoint重启训练很重要,可不可以麻烦工作人员补充一下demo。
Bot detected the issue body's language is not English, translate it automatically. 👯👭🏻🧑🤝🧑👫🧑🏿🤝🧑🏻👩🏾🤝👨🏿👬🏿
User Feedback: At present, ColossalAI does not have a complete example of how to save (and load) the optimizer and lr scheduler parameters in the hybrid parallel mode (zero3+tensor+pipeline). This feature is very useful for restarting training from the last checkpoint after a downtime. Important, can I trouble the staff to add the demo.
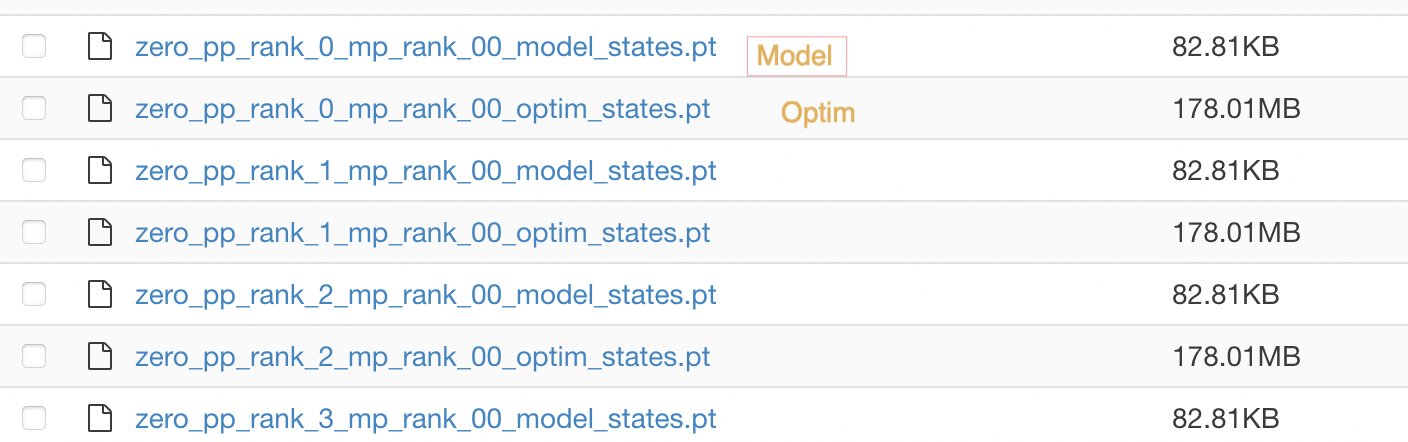
I suggest creating two unified functions to save and load the above parameters. The storage format can follow the example of deepspeed: each worker only stores and loads its corresponding model parameters (zero3) and optimizer status (Figure 1), and provides a conversion script to facilitate users to aggregate model parameters after training (Figure 2).
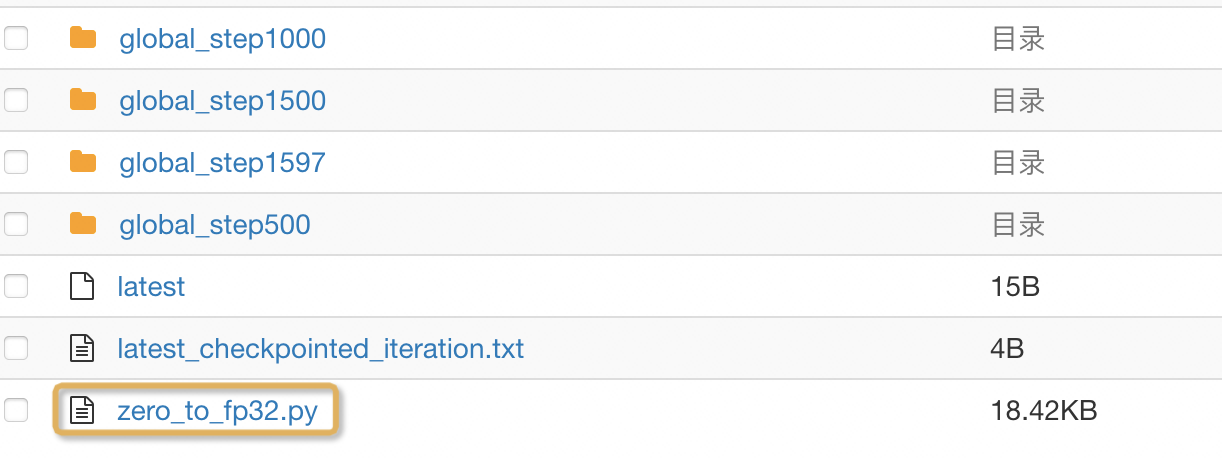
Could you share this zero_to_fp32 script ?
I suggest creating two unified functions to save and load the above parameters. The storage format can follow the example of deepspeed: each worker only stores and loads its corresponding model parameters (zero3) and optimizer status (Figure 1), and provides a conversion script to facilitate users to aggregate model parameters after training (Figure 2).
we are designing the new checkpoint io module to support checkpoint saving/loading from various formats, such as single model weights, huggingface style sharded weights and megatron-style sharded tensor weights, etc. Stay tuned.
Is there an ETA here?
we are designing the new checkpoint io module to support checkpoint saving/loading from various formats, such as single model weights, huggingface style sharded weights and megatron-style sharded tensor weights, etc. Stay tuned.
We have completed most of the related Checkpoint development and are doing the final polishing and refinement. Thanks.