[BUG] [DIFFUSION]: Sampling Fails to produce output
🐛 Describe the bug
After getting Training working in #2204 The loss value even went down during training but my output after using the sampling script and the default parameters the output was only random noise.
 The only minute error that I have that even comes up is that I don't have a validation set so using the default metrics throws a warning about the metrics not being passed. I did though train a new model with new metrics that threw no error and got the same result. If there are things you want me to test I can do that.
I don't know if you'd prefer I open another issue or just tack it on here but is using Triton fully supported? I got a proper Triton install to stop a warning from being thrown but I was wondering if I should've ignored it. As well I couldn't get any models to properly work when trying to do training with the -r call. Is there a specific model that is compatible with this new version? The error it throws is
RuntimeError: Error(s) in loading state_dict for GeminiDDP:
Missing keys in state dict: _forward_modulelvlb_weight, _forward_module.cond_state_model.attn_mask
Unexpected Keys in state dict: _forward_module.model_ema.decay _foward_model.model_ema.num_updates
The only minute error that I have that even comes up is that I don't have a validation set so using the default metrics throws a warning about the metrics not being passed. I did though train a new model with new metrics that threw no error and got the same result. If there are things you want me to test I can do that.
I don't know if you'd prefer I open another issue or just tack it on here but is using Triton fully supported? I got a proper Triton install to stop a warning from being thrown but I was wondering if I should've ignored it. As well I couldn't get any models to properly work when trying to do training with the -r call. Is there a specific model that is compatible with this new version? The error it throws is
RuntimeError: Error(s) in loading state_dict for GeminiDDP:
Missing keys in state dict: _forward_modulelvlb_weight, _forward_module.cond_state_model.attn_mask
Unexpected Keys in state dict: _forward_module.model_ema.decay _foward_model.model_ema.num_updates
Environment
Using the Conda Environment as given in the repository. Cuda supported up to 11.8 using Ubuntu 20.04. Nvidia Driver 525 Proprietary.
PIP freeze: absl-py==1.3.0 accelerate==0.15.0 aiohttp==3.8.3 aiosignal==1.3.1 albumentations==1.3.0 altair==4.2.0 antlr4-python3-runtime==4.8 async-timeout==4.0.2 attrs==22.2.0 bcrypt==4.0.1 blinker==1.5 braceexpand==0.1.7 brotlipy==0.7.0 cachetools==5.2.0 certifi @ file:///croot/certifi_1671487769961/work/certifi cffi @ file:///tmp/abs_98z5h56wf8/croots/recipe/cffi_1659598650955/work cfgv==3.3.1 charset-normalizer @ file:///tmp/build/80754af9/charset-normalizer_1630003229654/work click==8.1.3 coloredlogs==15.0.1 colossalai==0.1.12+torch1.12cu11.3 commonmark==0.9.1 contexttimer==0.3.3 cryptography @ file:///croot/cryptography_1665612644927/work datasets==2.8.0 decorator==5.1.1 diffusers==0.11.1 dill==0.3.6 distlib==0.3.6 einops==0.3.0 entrypoints==0.4 fabric==2.7.1 filelock==3.8.2 flatbuffers==22.12.6 flit-core @ file:///opt/conda/conda-bld/flit-core_1644941570762/work/source/flit_core frozenlist==1.3.3 fsspec==2022.11.0 ftfy==6.1.1 future==0.18.2 gitdb==4.0.10 GitPython==3.1.29 google-auth==2.15.0 google-auth-oauthlib==0.4.6 grpcio==1.51.1 huggingface-hub==0.11.1 humanfriendly==10.0 identify==2.5.11 idna @ file:///croot/idna_1666125576474/work imageio==2.9.0 imageio-ffmpeg==0.4.2 importlib-metadata==5.2.0 invisible-watermark==0.1.5 invoke==1.7.3 Jinja2==3.1.2 joblib==1.2.0 jsonschema==4.17.3 kornia==0.6.0 latent-diffusion @ file:///media/thomas/108E73348E731208/Users/Thoma/Desktop/dndiffusion/ColossalAI/examples/images/diffusion lightning-utilities==0.5.0 Markdown==3.4.1 MarkupSafe==2.1.1 mkl-fft==1.3.1 mkl-random @ file:///tmp/build/80754af9/mkl_random_1626186066731/work mkl-service==2.4.0 modelcards==0.1.6 mpmath==1.2.1 multidict==6.0.4 multiprocess==0.70.14 networkx==2.8.8 nodeenv==1.7.0 numpy @ file:///tmp/abs_653_j00fmm/croots/recipe/numpy_and_numpy_base_1659432701727/work oauthlib==3.2.2 omegaconf==2.1.1 onnx==1.13.0 onnxruntime==1.13.1 open-clip-torch==2.0.2 opencv-python==4.6.0.66 opencv-python-headless==4.6.0.66 packaging==22.0 pandas==1.5.2 paramiko==2.12.0 pathlib2==2.3.7.post1 Pillow==9.3.0 platformdirs==2.6.0 pre-commit==2.21.0 prefetch-generator==1.0.3 protobuf==3.20.1 psutil==5.9.4 pyarrow==10.0.1 pyasn1==0.4.8 pyasn1-modules==0.2.8 pycparser @ file:///tmp/build/80754af9/pycparser_1636541352034/work pydeck==0.8.0 pyDeprecate==0.3.2 Pygments==2.13.0 Pympler==1.0.1 PyNaCl==1.5.0 pyOpenSSL @ file:///opt/conda/conda-bld/pyopenssl_1643788558760/work pyrsistent==0.19.2 PySocks @ file:///tmp/build/80754af9/pysocks_1605305812635/work python-dateutil==2.8.2 pytorch-lightning @ file:///media/thomas/108E73348E731208/Users/Thoma/Desktop/dndiffusion/ColossalAI/examples/images/diffusion/lightning pytz==2022.7 pytz-deprecation-shim==0.1.0.post0 PyWavelets==1.4.1 PyYAML==6.0 qudida==0.0.4 regex==2022.10.31 requests @ file:///opt/conda/conda-bld/requests_1657734628632/work requests-oauthlib==1.3.1 responses==0.18.0 rich==12.6.0 rsa==4.9 scikit-image==0.19.3 scikit-learn==1.2.0 scipy==1.9.3 semver==2.13.0 six @ file:///tmp/build/80754af9/six_1644875935023/work smmap==5.0.0 streamlit==1.12.1 streamlit-drawable-canvas==0.8.0 sympy==1.11.1 tensorboard==2.11.0 tensorboard-data-server==0.6.1 tensorboard-plugin-wit==1.8.1 tensorboardX==2.5.1 test-tube==0.7.5 threadpoolctl==3.1.0 tifffile==2022.10.10 tokenizers==0.12.1 toml==0.10.2 toolz==0.12.0 torch==1.12.1 torchmetrics==0.7.0 torchvision==0.13.1 tornado==6.2 tqdm==4.64.1 transformers==4.25.1 triton==1.1.1 typing-extensions @ file:///croot/typing_extensions_1669924550328/work tzdata==2022.7 tzlocal==4.2 urllib3 @ file:///croot/urllib3_1670526988650/work validators==0.20.0 virtualenv==20.17.1 watchdog==2.2.0 wcwidth==0.2.5 webdataset==0.2.5 Werkzeug==2.2.2 xformers==0.0.15.dev395+git.7e05e2c xxhash==3.1.0 yarl==1.8.2 zipp==3.11.0
Thanks for your issue, I find this problem also because the open source model ckpt from stableAI have some miss key. I am fixing with this problem. what version of ckpt do you use, 2.0 or 2.1?
Hello, @Fazziekey thanks for your reply. Specifically for testing purposes the models I tried to use were: Stable Diffusion 1.5: v1-5-pruned.ckpt SOURCE: https://huggingface.co/runwayml/stable-diffusion-v1-5
Stable Diffusion 2.0: 512-base-ema.ckpt and 768-v-ema.ckpt SOURCE: https://huggingface.co/stabilityai/stable-diffusion-2
Stable Diffusion 2.1: v2-1_512-ema-pruned-cpkt and v2-1_768-ema-pruned.ckpt SOURCE: https://huggingface.co/stabilityai/stable-diffusion-2-1-base
All failed to work. I don't know if this information helps at all but using the SD 2.0 512-base-ema and the SD 2.1 2.1-512-ema-pruned I was actually able to sample from it while using a project.yaml file from a training run which used DDP and a project.yaml file from a colossalai strategy training and not just give random noise but instead give something noisy and vaguely resembling a dog. While I wasn't able to get the 1.5 model to work.
Hello, @Fazziekey thanks for your reply. Specifically for testing purposes the models I tried to use were: Stable Diffusion 1.5: v1-5-pruned.ckpt SOURCE: https://huggingface.co/runwayml/stable-diffusion-v1-5
Stable Diffusion 2.0: 512-base-ema.ckpt and 768-v-ema.ckpt SOURCE: https://huggingface.co/stabilityai/stable-diffusion-2
Stable Diffusion 2.1: v2-1_512-ema-pruned-cpkt and v2-1_768-ema-pruned.ckpt SOURCE: https://huggingface.co/stabilityai/stable-diffusion-2-1-base
All failed to work. I don't know if this information helps at all but using the SD 2.0 512-base-ema and the SD 2.1 2.1-512-ema-pruned I was actually able to sample from it while using a project.yaml file from a training run which used DDP and a project.yaml file from a colossalai strategy training and not just give random noise but instead give something noisy and vaguely resembling a dog. While I wasn't able to get the 1.5 model to work.
hello, can you try to change your placement_policy to cuda? like that
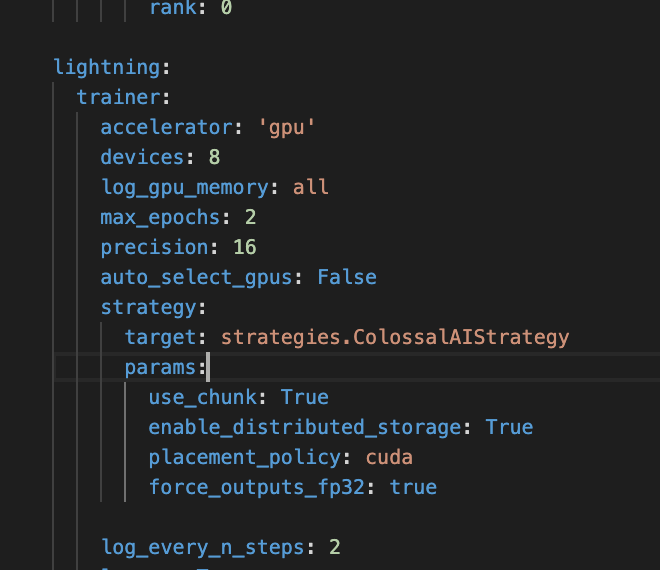
@Fazziekey I actually did already do this. My gpu is significantly better than my cpu so using auto is a large bottleneck for me so I already changed it to cuda.
I want to include this just in case it of any interest here is my train_colossalai.yaml I changed the monitor metric because the val metric was throwing an error at the end of the training. I am also now using the docker image provided as my environment. This probably doesn't help but I did 2 separate training runs for 3 epochs on 300,000 images with one using force_outputs_fp32 false and one with it true.
model: base_learning_rate: 1.0e-4 target: ldm.models.diffusion.ddpm.LatentDiffusion params: parameterization: "v" linear_start: 0.00085 linear_end: 0.0120 num_timesteps_cond: 1 log_every_t: 200 timesteps: 1000 first_stage_key: image cond_stage_key: txt image_size: 64 channels: 4 cond_stage_trainable: false conditioning_key: crossattn monitor: train/loss_simple scale_factor: 0.18215 use_ema: false # we set this to false because this is an inference only config
scheduler_config: # 10000 warmup steps
target: ldm.lr_scheduler.LambdaLinearScheduler
params:
warm_up_steps: [ 1 ] # NOTE for resuming. use 10000 if starting from scratch
cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
f_start: [ 1.e-6 ]
f_max: [ 1.e-4 ]
f_min: [ 1.e-10 ]
unet_config:
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
params:
use_checkpoint: True
use_fp16: True
image_size: 32 # unused
in_channels: 4
out_channels: 4
model_channels: 320
attention_resolutions: [ 4, 2, 1 ]
num_res_blocks: 2
channel_mult: [ 1, 2, 4, 4 ]
num_head_channels: 64 # need to fix for flash-attn
use_spatial_transformer: True
use_linear_in_transformer: True
transformer_depth: 1
context_dim: 1024
legacy: False
first_stage_config:
target: ldm.models.autoencoder.AutoencoderKL
params:
embed_dim: 4
ddconfig:
#attn_type: "vanilla-xformers"
double_z: true
z_channels: 4
resolution: 256
in_channels: 3
out_ch: 3
ch: 128
ch_mult:
- 1
- 2
- 4
- 4
num_res_blocks: 2
attn_resolutions: []
dropout: 0.0
lossconfig:
target: torch.nn.Identity
cond_stage_config:
target: ldm.modules.encoders.modules.FrozenOpenCLIPEmbedder
params:
freeze: True
layer: "penultimate"
data: target: main.DataModuleFromConfig params: batch_size: 50 wrap: False num_workers: 0 train: target: ldm.data.base.Txt2ImgIterableBaseDataset params: file_path: "/workspace/new/" world_size: 1 rank: 0
lightning: trainer: accelerator: 'gpu' devices: 1 log_gpu_memory: all max_epochs: 3 precision: 16 auto_select_gpus: False strategy: target: strategies.ColossalAIStrategy params: use_chunk: True enable_distributed_storage: True placement_policy: cuda force_outputs_fp32: True
log_every_n_steps: 2
logger: True
default_root_dir: "/tmp/diff_log/"
# profiler: pytorch
logger_config: wandb: target: loggers.WandbLogger params: name: nowname save_dir: "/tmp/diff_log/" offline: opt.debug id: nowname


 The first image is output i got using v2-inference-yaml and 512-base-ema.ckpt while the second output is from using a model trained for 3 epochs on 30,000 images using the train_colossalai.yaml. The third image is using the 512-base-ema.ckpt on 50 steps plms while the first image is using 500 steps plms sampling.
The first image is output i got using v2-inference-yaml and 512-base-ema.ckpt while the second output is from using a model trained for 3 epochs on 30,000 images using the train_colossalai.yaml. The third image is using the 512-base-ema.ckpt on 50 steps plms while the first image is using 500 steps plms sampling.
@Fazziekey Using the Docker Image and a fresh git clone of the repository the only error that gets thrown when trying to -r from 512-base-ema.ckpt and v2-1_512-ema-pruned.ckpt is
Traceback (most recent call last):
File "main.py", line 652 in
During Handling of the above exception, another exception occurred:
traceback (most recent call last):
File ''main.py", line 825, in
I have just finished training a model for 2 epochs on 40000 images and have still got a noisy image as output while utilizing the docker image and a fresh git clone of this repository.
Interesting results from training using the tutorial stable diffusion area, using the pretrained v1-5 model and training off of that and then sampling the images that were produced were green but had vague humanoid shapes in them far superior to what i saw from training sd 2.0 but much worse than the loss would have led me to expect.

 Now while these images may seem completely random zooming out looking at them and knowing the training data I can say that these are vague shapes of the training data.
Now while these images may seem completely random zooming out looking at them and knowing the training data I can say that these are vague shapes of the training data.
@Fazziekey Well i really don't mean to be using this like its my personal blog but, I was using the docker image and I went into the old colossalai diffusion folder that i kept on my pc the SD 1.4/1.5 version. I had to change some install like downgrading to pytorch 1.11.0 and colossalai to 0.1.10+torch1.11cu11.3. I also did pip install -r requirements.txt but as far as i know that only pip install -e . the necessary repositories like taming transformers and clip. As well i installed the nightly version of pytorch-lightning the version 1.9.0rc0. This made the repository work though interestingly the models are still saving smaller than before at 10.3gb instead of 11.1gb but sampling is working here are some examples.


Here is my pip freeze: absl-py==1.3.0 aiobotocore==2.4.2 aiohttp==3.8.3 aioitertools==0.11.0 aiosignal==1.3.1 albumentations==0.4.3 altair==4.2.0 antlr4-python3-runtime==4.8 anyio==3.6.2 apex==0.1 arrow==1.2.3 async-timeout==4.0.2 attrs==22.2.0 backports.zoneinfo==0.2.1 bcrypt==4.0.1 beautifulsoup4==4.11.1 bitsandbytes==0.36.0.post2 blessed==1.19.1 blinker==1.5 botocore==1.27.59 braceexpand==0.1.7 brotlipy==0.7.0 cachetools==5.2.0 certifi @ file:///croot/certifi_1665076670883/work/certifi cffi @ file:///tmp/abs_98z5h56wf8/croots/recipe/cffi_1659598650955/work cfgv==3.3.1 charset-normalizer @ file:///tmp/build/80754af9/charset-normalizer_1630003229654/work click==8.1.3 -e git+https://github.com/openai/CLIP.git@d50d76daa670286dd6cacf3bcd80b5e4823fc8e1#egg=clip coloredlogs==15.0.1 colossalai==0.1.10+torch1.11cu11.3 commonmark==0.9.1 contexttimer==0.3.3 contourpy==1.0.6 croniter==1.3.8 cryptography @ file:///tmp/build/80754af9/cryptography_1652083738073/work cycler==0.11.0 datasets==2.8.0 decorator==5.1.1 deepdiff==6.2.3 diffusers==0.11.1 dill==0.3.6 distlib==0.3.6 dnspython==2.2.1 einops==0.3.0 email-validator==1.3.0 entrypoints==0.4 fabric==2.7.1 fastapi==0.88.0 ffmpy==0.3.0 filelock==3.9.0 fire==0.5.0 flatbuffers==22.12.6 fonttools==4.38.0 frozenlist==1.3.3 fsspec==2022.11.0 ftfy==6.1.1 future==0.18.2 gitdb==4.0.10 GitPython==3.1.30 google-auth==2.15.0 google-auth-oauthlib==0.4.6 gradio==3.11.0 grpcio==1.51.1 h11==0.12.0 httpcore==0.15.0 httptools==0.5.0 httpx==0.23.1 huggingface-hub==0.11.1 humanfriendly==10.0 identify==2.5.11 idna @ file:///tmp/build/80754af9/idna_1637925883363/work imageio==2.9.0 imageio-ffmpeg==0.4.2 imgaug==0.2.6 importlib-metadata==5.2.0 importlib-resources==5.10.2 inquirer==3.1.1 invisible-watermark==0.1.5 invoke==1.7.3 itsdangerous==2.1.2 Jinja2==3.1.2 jmespath==1.0.1 joblib==1.2.0 jsonschema==4.17.3 kiwisolver==1.4.4 kornia==0.6.0
Editable install with no version control (latent-diffusion==0.0.1)
-e /workspace/ColossalAI2/examples/images/diffusion lightning @ file:///workspace/ColossalAI2/examples/images/diffusion/lightning lightning-api-access==0.0.5 lightning-cloud==0.5.16 lightning-utilities==0.5.0 linkify-it-py==1.0.3 Markdown==3.4.1 markdown-it-py==2.1.0 MarkupSafe==2.1.1 matplotlib==3.6.2 mdit-py-plugins==0.3.3 mdurl==0.1.2 mkl-fft==1.3.1 mkl-random @ file:///tmp/build/80754af9/mkl_random_1626186064646/work mkl-service==2.4.0 mpmath==1.2.1 multidict==6.0.4 multiprocess==0.70.14 networkx==2.8.8 ninja==1.11.1 nodeenv==1.7.0 numpy @ file:///tmp/abs_653_j00fmm/croots/recipe/numpy_and_numpy_base_1659432701727/work oauthlib==3.2.2 omegaconf==2.1.1 onnx==1.13.0 onnxruntime==1.13.1 open-clip-torch==2.7.0 opencv-python==4.6.0.66 opencv-python-headless==4.7.0.68 ordered-set==4.1.0 orjson==3.8.3 packaging==21.3 pandas==1.5.2 paramiko==2.12.0 pathlib2==2.3.7.post1 Pillow==9.2.0 pkgutil_resolve_name==1.3.10 platformdirs==2.6.2 pre-commit==2.21.0 prefetch-generator==1.0.3 protobuf==3.20.1 psutil==5.9.4 pudb==2019.2 pyarrow==10.0.1 pyasn1==0.4.8 pyasn1-modules==0.2.8 pycparser @ file:///tmp/build/80754af9/pycparser_1636541352034/work pycryptodome==3.16.0 pydantic==1.10.3 pydeck==0.8.0 pyDeprecate==0.3.1 pydub==0.25.1 Pygments==2.13.0 PyJWT==2.6.0 Pympler==1.0.1 PyNaCl==1.5.0 pyOpenSSL @ file:///opt/conda/conda-bld/pyopenssl_1643788558760/work pyparsing==3.0.9 pyrsistent==0.19.3 PySocks @ file:///tmp/build/80754af9/pysocks_1605305779399/work python-dateutil==2.8.2 python-dotenv==0.21.0 python-editor==1.0.4 python-multipart==0.0.5 pytorch-lightning==1.9.0rc0 pytz==2022.7 pytz-deprecation-shim==0.1.0.post0 PyWavelets==1.4.1 PyYAML==6.0 qudida==0.0.4 readchar==4.0.3 regex==2022.10.31 requests @ file:///opt/conda/conda-bld/requests_1657734628632/work requests-oauthlib==1.3.1 responses==0.18.0 rfc3986==1.5.0 rich==12.6.0 rsa==4.9 s3fs==2022.11.0 scikit-image==0.19.3 scikit-learn==1.2.0 scipy==1.9.3 semver==2.13.0 six @ file:///tmp/build/80754af9/six_1644875935023/work smmap==5.0.0 sniffio==1.3.0 soupsieve==2.3.2.post1 starlette==0.22.0 starsessions==1.3.0 streamlit==1.16.0 sympy==1.11.1 -e git+https://github.com/CompVis/taming-transformers.git@3ba01b241669f5ade541ce990f7650a3b8f65318#egg=taming_transformers tensorboard==2.11.0 tensorboard-data-server==0.6.1 tensorboard-plugin-wit==1.8.1 tensorboardX==2.5.1 termcolor==2.2.0 test-tube==0.7.5 threadpoolctl==3.1.0 tifffile==2022.10.10 titans==0.0.7 tokenizers==0.12.1 toml==0.10.2 toolz==0.12.0 torch==1.11.0+cu113 torch-fidelity==0.3.0 torchaudio==0.11.0+cu113 torchmetrics==0.7.0 torchvision==0.12.0+cu113 tornado==6.2 tqdm==4.64.1 traitlets==5.8.0 transformers==4.19.2 typing_extensions @ file:///tmp/abs_ben9emwtky/croots/recipe/typing_extensions_1659638822008/work tzdata==2022.7 tzlocal==4.2 uc-micro-py==1.0.1 ujson==5.7.0 urllib3 @ file:///tmp/abs_5dhwnz6atv/croots/recipe/urllib3_1659110457909/work urwid==2.1.2 uvicorn==0.20.0 uvloop==0.17.0 validators==0.20.0 virtualenv==20.17.1 watchdog==2.2.0 watchfiles==0.18.1 wcwidth==0.2.5 webdataset==0.2.5 websocket-client==1.4.2 websockets==10.4 Werkzeug==2.2.2 wrapt==1.14.1 xxhash==3.2.0 yarl==1.8.2 zipp==3.11.0
I also met with this problem as you. I think this is because the official ckpt file is a pruned file, not a full file. Because after the train, I got a ckpt of 9.7G which is larger than 4.5g. So I think the official ckpt can not be used to train a new model.
@Fazziekey Have you fond the solution to solve the ckpt (stable diffusion 2.0) problem?
@Thomas2419 It seems that the samples are still not correct. I try to train diffusion with colossalai, but failed. Does any one who has the correct version of code the do this?