first and second test speed very slow
Hello, my cuda10.2 libtorch1.7.1 model yolov5 was slow in the first two tests and the second one was the slowest and then normal. What is the reason?
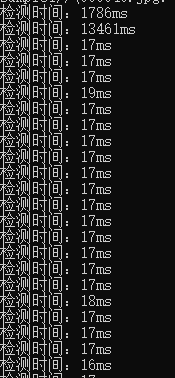
yolov5 was slow in the first two tests and the second one was the slowest and then normal.
This is true for me as well. That's why an empty image is inputted three times as warming up in Inference() function.
https://github.com/hotsuyuki/YOLOv5_PyTorch_cpp/blob/main/src/object_detector/src/object_detector.cpp#L70
void ObjectDetector::Inference(float confidence_threshold, float iou_threshold) {
std::cout << "=== Empty inferences to warm up === \n\n";
for (std::size_t i = 0; i < 3; ++i) {
cv::Mat tmp_image = cv::Mat::zeros(input_height_, input_width_, CV_32FC3);
std::vector<ObjectInfo> tmp_results;
Detect(tmp_image, 1.0, 1.0, tmp_results);
}
std::cout << "=== Warming up is done === \n\n\n";
:
:
This repository is inspired by yasenh/libtorch-yolov5, and its README.md might be helpful. https://github.com/yasenh/libtorch-yolov5#faq
- Why the first "inference takes" so long from the log?
- The first inference is slower as well due to the initial optimization that the JIT (Just-in-time compilation) is doing on your code. This is similar to "warm up" in other JIT compilers. Typically, production services will warm up a model using representative inputs before marking it as available.
- It may take longer time for the first cycle. The yolov5 python version run the inference once with an empty image before the actual detection pipeline. User can modify the code to process the same image multiple times or process a video to get the valid processing time.
yolov5 was slow in the first two tests and the second one was the slowest and then normal.
This is true for me as well. That's why an empty image is inputted three times as warming up in
Inference()function. https://github.com/hotsuyuki/YOLOv5_PyTorch_cpp/blob/main/src/object_detector/src/object_detector.cpp#L70void ObjectDetector::Inference(float confidence_threshold, float iou_threshold) { std::cout << "=== Empty inferences to warm up === \n\n"; for (std::size_t i = 0; i < 3; ++i) { cv::Mat tmp_image = cv::Mat::zeros(input_height_, input_width_, CV_32FC3); std::vector<ObjectInfo> tmp_results; Detect(tmp_image, 1.0, 1.0, tmp_results); } std::cout << "=== Warming up is done === \n\n\n"; : :This repository is inspired by yasenh/libtorch-yolov5, and its README.md might be helpful. https://github.com/yasenh/libtorch-yolov5#faq
- Why the first "inference takes" so long from the log?
- The first inference is slower as well due to the initial optimization that the JIT (Just-in-time compilation) is doing on your code. This is similar to "warm up" in other JIT compilers. Typically, production services will warm up a model using representative inputs before marking it as available.
- It may take longer time for the first cycle. The yolov5 python version run the inference once with an empty image before the actual detection pipeline. User can modify the code to process the same image multiple times or process a video to get the valid processing time.
Thank you for your reply. I read that there is no such problem in libtorch1.6 and it is unavoidable in version 1.7, right?
Actually, I've tested on libtorch v1.6.0 and I encountered the same problem.
there is no such problem in libtorch1.6 and it is unavoidable in version 1.7, right?
I haven't tested on libtorch v1.7.0 or later, so honestly, I'm not sure.
Actually, I've tested on libtorch v1.6.0 and I encountered the same problem.
there is no such problem in libtorch1.6 and it is unavoidable in version 1.7, right?
I haven't tested on libtorch v1.7.0 or later, so honestly, I'm not sure.
Actually, I've tested on libtorch v1.6.0 and I encountered the same problem.
there is no such problem in libtorch1.6 and it is unavoidable in version 1.7, right?
I haven't tested on libtorch v1.7.0 or later, so honestly, I'm not sure.
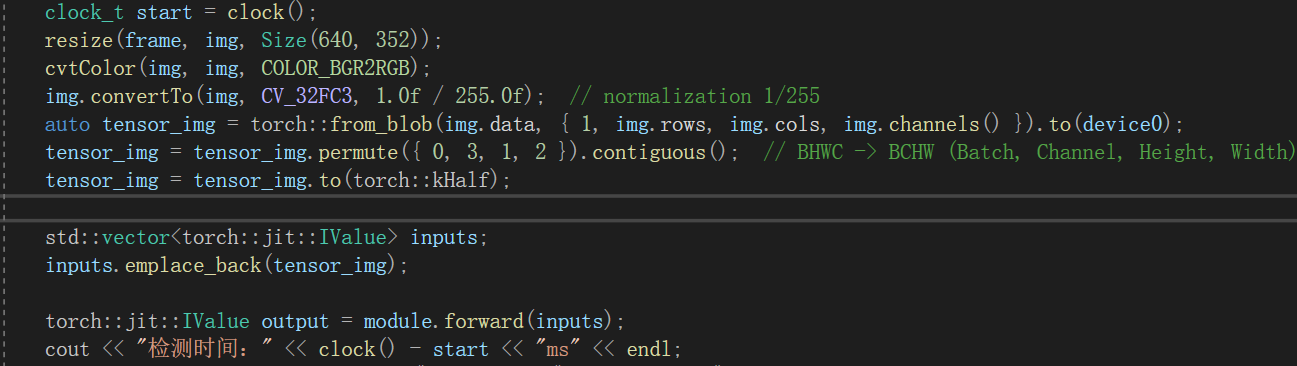
Thank you very much! You just need to add a few rounds of warm-up to the code, right? int main() { // Loading Module torch::jit::script::Module module = torch::jit::load("best.torchscript.pt");//torchscript torch::DeviceType device_type; device_type = torch::kCUDA; torch::Device device0(device_type); module.to(device0); module.to(torch::kHalf); module.eval();
Mat frame,img;
int b = 0; //定义想要保存的图片的序号
vector<files> allf = fileSearch("sample1//");//文件夹路径
ofstream outfile;
outfile.open("data.txt");//创建txt文件
for (int n = 0; n < allf.size(); n++)
{
clock_t start = clock();
frame = imread(allf[n].filepath);
//cout << clock() - start << "ms-read" << endl;
if (frame.empty())
{
std::cout << "Read frame failed!" << std::endl;
break;
}
}
just need to add a few rounds of warm-up to the code, right?
Yes, you're right.