Visualization of a 12-layer BERT for sentence encoding/embedding
One major concern of using BERT as sentence encoder (i.e. mapping a variable-length sentence to a fixed length vector) is which layer to pool and how to pool. I made a visualization on UCI-News Aggregator Dataset, where I randomly sample 20K news titles; get sentence encodes from different layers and with max-pooling and avg-pooling, finally reduce it to 2D via PCA. There are only four classes of the data, illustrated in red, blue, yellow and green. The BERT model is uncased_L-12_H-768_A-12 released by Google.
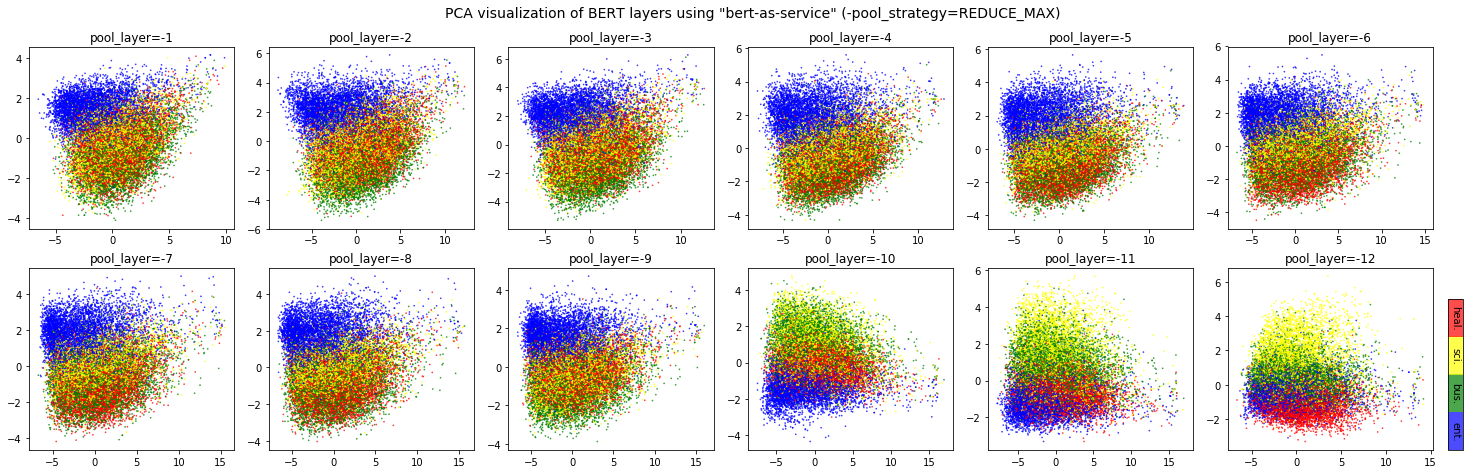

full thread can be viewed here: https://github.com/hanxiao/bert-as-service#q-so-which-layer-and-which-pooling-strategy-is-the-best
for those who are interested in using BERT model as sentence encoder, welcome to check my repo bert-as-service: https://github.com/hanxiao/bert-as-service You can get sentence/ELMo-like word embedding with 2 lines of code.

@hanxiao Is that sentence encoding by averaging the word vectors to represent the whole sentence ?
Can in simple words you explain how you got sentence embedding from word embedding ?
@hanxiao Is that sentence encoding by averaging the word vectors to represent the whole sentence ?
I dont think it is by taking average of the word-embeddings.
@hanxiao Is that sentence encoding by averaging the word vectors to represent the whole sentence ?
You can check the title of these two pictures which illustrate the pooling strategies (i.e. REDUCE_MEAN and REDUCE_MAX)