Pre-trained models fail to infer with batch>1 in a standalone code
Several Reshape nodes have hard-coded batch dimension value in the 2nd input. Could you please fix the models to preserve batch?
This is how all the pre-trained models look like:
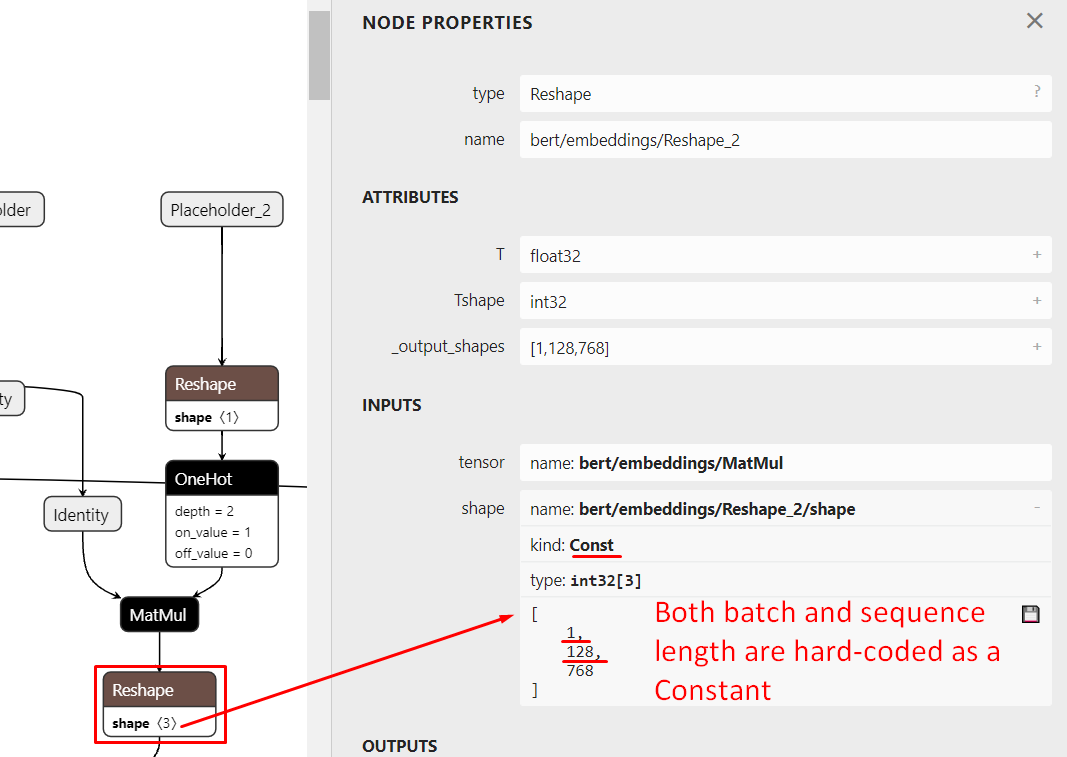
Reshape nodes with hard-coded output batch:
- bert/embeddings/Reshape_2
- bert/embeddings/Reshape
- bert/embeddings/Reshape_3
- bert/encoder/layer_0/attention/self/Reshape_1
- bert/encoder/layer_0/attention/self/Reshape
- bert/encoder/layer_0/attention/self/Reshape_2
- bert/encoder/Reshape
- bert/encoder/layer_1/attention/self/Reshape
- bert/encoder/layer_1/attention/self/Reshape_2
- bert/encoder/layer_1/attention/self/Reshape_1
- bert/encoder/layer_2/attention/self/Reshape_1
- bert/encoder/layer_2/attention/self/Reshape_2
- bert/encoder/layer_2/attention/self/Reshape
- bert/encoder/layer_3/attention/self/Reshape_2
- bert/encoder/layer_3/attention/self/Reshape_1
- bert/encoder/layer_3/attention/self/Reshape
- bert/encoder/layer_4/attention/self/Reshape_2
- bert/encoder/layer_4/attention/self/Reshape
- bert/encoder/layer_4/attention/self/Reshape_1
- bert/encoder/layer_5/attention/self/Reshape
- bert/encoder/layer_5/attention/self/Reshape_1
- bert/encoder/layer_5/attention/self/Reshape_2
- bert/encoder/layer_6/attention/self/Reshape_1
- bert/encoder/layer_6/attention/self/Reshape
- bert/encoder/layer_6/attention/self/Reshape_2
- bert/encoder/layer_7/attention/self/Reshape_1
- bert/encoder/layer_7/attention/self/Reshape_2
- bert/encoder/layer_7/attention/self/Reshape
- bert/encoder/layer_8/attention/self/Reshape
- bert/encoder/layer_8/attention/self/Reshape_1
- bert/encoder/layer_8/attention/self/Reshape_2
- bert/encoder/layer_9/attention/self/Reshape
- bert/encoder/layer_9/attention/self/Reshape_1
- bert/encoder/layer_9/attention/self/Reshape_2
- bert/encoder/layer_10/attention/self/Reshape
- bert/encoder/layer_10/attention/self/Reshape_1
- bert/encoder/layer_10/attention/self/Reshape_2
- bert/encoder/layer_11/attention/self/Reshape
- bert/encoder/layer_11/attention/self/Reshape_2
- bert/encoder/layer_11/attention/self/Reshape_1
- bert/encoder/Reshape_13
The problem is still relevant for me.
I would like to use pre-strained models using my custom scripts without a need to take this whole repository with me. And I need them infer-able with different batch sizes.
To do this I had to manually load currently available models and patch modeling.py function get_shape_list to keep Shape calculating sub-graphs and to never hard-code Reshape second inputs and to let shape inference flow from Placeholders without constraints. I deleted these lines
if not non_static_indexes:
return shape
With that I got updated models, but I'm sure I'm not the one who need them in batch-change-able way.
Could you guys be so kind to upload pre-trained models in such form? With Shape sub-graphs.
Also, for BERT model it is good to have seq_len unconstrained -- like the batch. As padding the value to fit 128/256/512 tokens takes all the performance away.