2022-09-22 - Sandbox Incident - Underlying EC2 Instance Failure
From 2022-09-22T12:00:33.412410Z to 2022-09-22T12:01:46.687840Z, there was an incident in sandbox caused by Amazon cycling out an instance we were using.
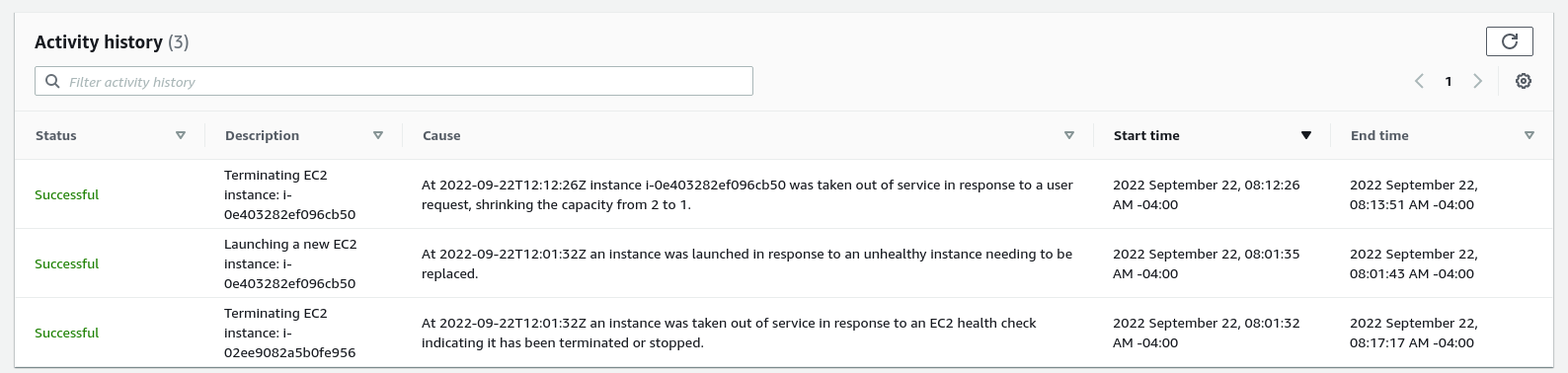 @mikermcneil Asked for the following information to be gathered:
@mikermcneil Asked for the following information to be gathered:
How many individual 500 responses or failed requests occurred per individual sandbox account, the user interactions that were attempted and the circumstance, and what is the email address for each?
I didn't do this during the intial report, but I went ahead and queried the number of errors per active sandbox instance. This returned 0 errors. Sorry for the confusion, but this did not affect any active sandbox instances.
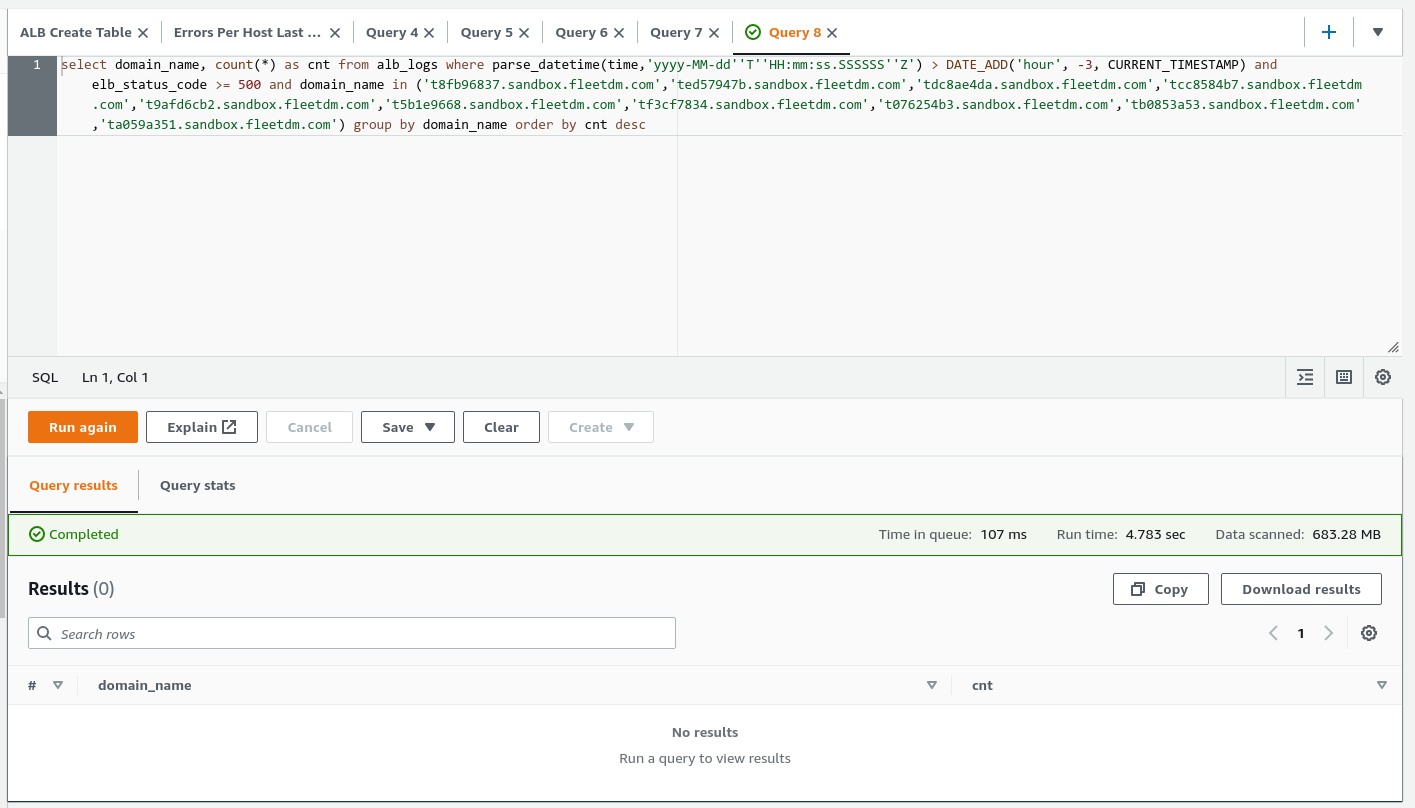
The errors that we saw were all for instances that were already fully deprovisioned.
Please include the above in the GitHub issue and draft up a response for how you think we should reply. Link that here and I'll review and deliver those emails ASAP.
I think the proper response is to not respond. No active customer instances were impacted.
Are errors still occurring now? If so, how many? We’ll consider taking sandbox down or displaying a message to stop the unexpected customer experiences ASAP.
No, the system automatically recovered in around 1m 30s.
What is the remaining effort required to identify and fix the root cause for each type of 5xx response?
No more effort required.
Just for completeness sake, this is all the errors per sandbox instance, note that these were all deprovisioned at the time.
We see these errors because previous sandbox instances setup hardware to talk to Fleet, and even after it goes away customers don't always remove their instances, so they continue calling in to a now gone instance until the customer takes action. d9ea53ac-379f-41e4-a8fc-e6bc50ce890c.csv
@zwinnerman-fleetdm Thanks for the summary. There were 500 errors, which means someone was sending the requests causing them.
If the instances were deprovisioned, why were requests still aiming for them? A 5xx response means there was an unexpected error. What was the error?
Last, what are the plans to change the product so that this doesn’t happen again for future requests?
Since this screen recording contains some IP addresses, making a separate confidential issue: https://github.com/fleetdm/confidential/issues/1712
Next steps
- TODO: Zach Winnerman: Investigate what we think is an underlying hardware in our EKS cluster that was not reported to us by Amazon and is not listed on their status page: https://health.aws.amazon.com/health/status
- TODO: Zach Winnerman: Figure out what happens in the user experience when a failed
GET /api/v1/device/:uuid/policiescall happens behind the scenes. (Tomas: Roberto can help) - TODO: Zach Winnerman: What is the behavior in a completely working system with expired instances in regards to Fleet Desktop? For the polling endpoint we give a 302-- it makes us wonder, what happens if a Fleet Desktop user tries to visit "My device" or "Transparency" after their Fleet Sandbox instance has perspective? (We think it should redirect to https://fleetdm.com/try-fleet/sandbox-expired)
- TODO: A realization from here is that Tomas tried to go to the fleetdm.com URL and we realized you have to be logged in. If you log in, we send you to the license dispenser UI, which is weird. (Winnerman to let Eric know)
@mikermcneil As a followup for the first TODO, as I suspected AWS won't answer a question like this under our current support plan.
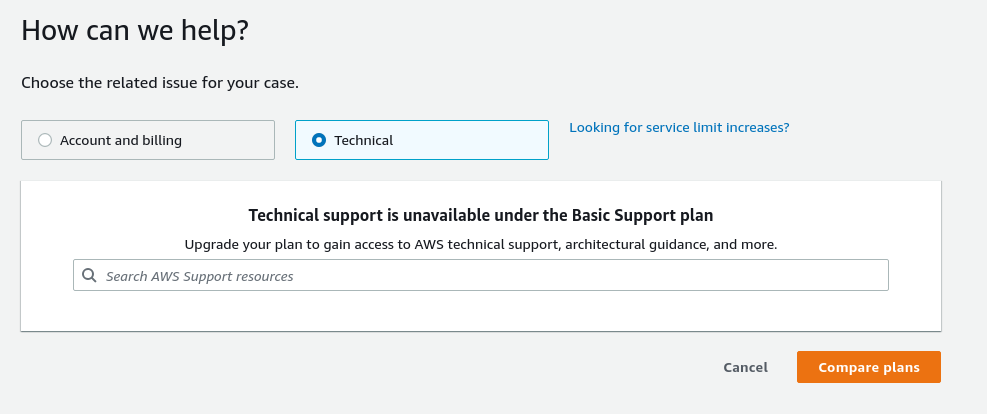
I believe that the minimum support tier we would need is the Business tier support which costs around $100/mo. We can use credits towards this, which we have a lot of. Unless you have an objection I'll go ahead and add this support tier to our account so I can ask the question.
Per roberto: for the 2nd TODO:
we ping the
/policiesendpoint every 5 minutes, if we get an error we just do nothing (no crash, no gray out) this has no consequences for Fleet Desktop
So this issue was invisible to users entirely it seems.
For the 3rd TODO:
both items are just links (think of an
<a href="">) that we open in the browser, so we just do whatever the browser does. If it was 302 to an HTML page, the browser will open and show that
So this also seems like good behavior, as long as we fix the 4th TODO.
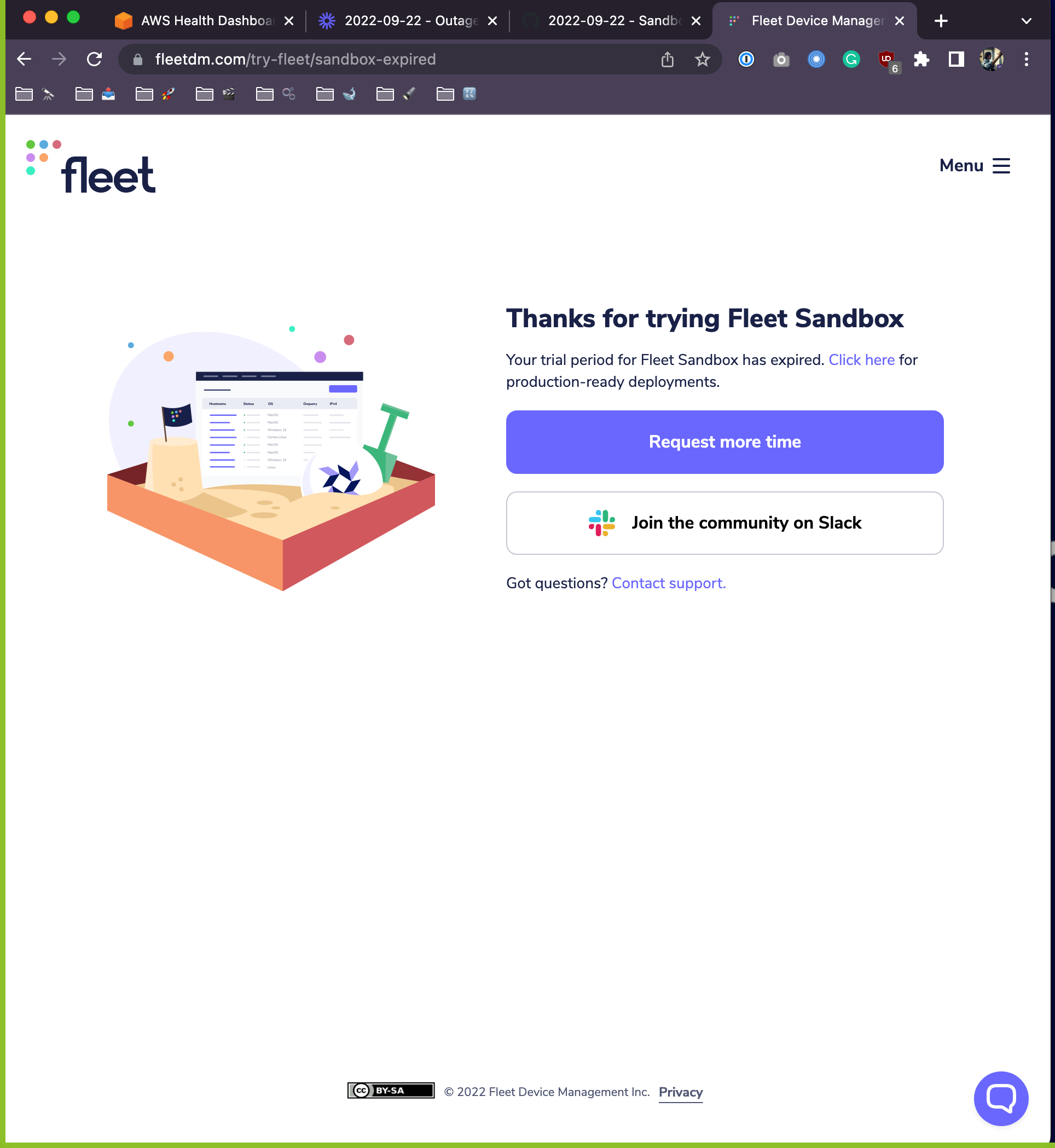
Hey @mikermcneil, I also just noticed some less than ideal behavior. Currently when the user is redirected to the sandbox-expired page, there's a button that says "Request more time". The issue is that by the time they see that page, we have already deleted all of the instance's data. It would be a bit jarring if the customer requests more time, and then we don't have their data anymore.
My suggestion would be one of two things:
- Change the wording to better reflect what the system does now
- Preserve some data for a while just in case a customer requests more time
If it was 302 to an HTML page, the browser will open and show that
@zwinnerman-fleetdm Have we verified this is what actually happens?
I also just noticed some less than ideal behavior. Currently when the user is redirected to the sandbox-expired page, there's a button that says "Request more time". The issue is that by the time they see that page, we have already deleted all of the instance's data. It would be a bit jarring if the customer requests more time, and then we don't have their data anymore.
@zwinnerman-fleetdm Thanks for the feedback! Great ideas too. I'd lean towards #2, since the goal is to extend the length of the trial when as we feel confident in the infra. Up to @zhumo.
FYI so far, no one has clicked the button, to my knowledge. The original plan was for us to scramble and figure it out the first time it happened.
Have we verified this is what actually happens?
I have in the past, but to double check this is what I did (please feel free to shout if you see any problems with my simulation)
- Completely shut down the Fleet server
- Started a local server on port
8080with this:
const https = require('https');
const fs = require('fs');
const options = {
key: fs.readFileSync('./server.key'),
cert: fs.readFileSync('./server.pem')
}
const template = fs.readFileSync('./302.html', 'utf8');
const server = https.createServer(options, (req, res) => {
res.writeHead(302, {'content-type': 'text/html'});
res.end(template);
});
server.listen(8080);
This is the recording (note that the device token is a token in my local server) :
https://user-images.githubusercontent.com/4419992/191872003-46f75097-264e-44d3-81c7-ccaf3999b256.mov
a note on this:
For the polling endpoint we give a 302-- it makes us wonder, what happens if a Fleet Desktop user tries to visit "My device" or "Transparency" after their Fleet Sandbox instance has perspective? (We think it should redirect to https://fleetdm.com/try-fleet/sandbox-expired)
@zwinnerman-fleetdm you mentioned above that:
So this also seems like good behavior, as long as we fix the 4th TODO.
is this something you can do solely on the infra side? (add a redirect for old instances) or do we need to add special behavior to Fleet Desktop? E.g.: add a build flag to let Desktop know it's running off a Sandbox instance
is this something you can do solely on the infra side? (add a redirect for old instances) or do we need to add special behavior to Fleet Desktop? E.g.: add a build flag to let Desktop know it's running off a Sandbox instance
We already redirect all traffic to non-active instances to that page. This is in reference to that target page's behavior which would be controled by @eashaw iirc.
Sorry I missed this. I would say nothing left. Closing this issue.