Int64 handling in Perspective.js
Problem Description
Perspective currently exports the integer data type, which correspond to DTYPE_INT32 in Javascript and DTYPE_INT64 in Python. This is done because of the lack of more granular numeric types in JS and Python, as well as the lack of support (until more recently through BigInt) for 64-bit integers in Javascript.
However, Apache Arrow does expose a full range of the granular numeric types (uint8/16/32/64 and int8/16/32/64) supported by Perspective's C++ engine, and we implement logic to load these columns as their arrow-specified data type - i.e. an Arrow table with columns that are uint8 will create a Perspective table with the same column as DTYPE_UINT8, and all values are stored correctly in the engine.
When values are output to Javascript, however, through the to_json() etc. methods, numeric values from C++ must be converted to Javascript values through the Embind API. For integers of various bit widths and signedness, this process equates to:
- Get the integer based on the type of the column (
DTYPE_UINT8->std::uint8_tetc.) - Implicitly convert the integer to a
std::int64_t, which counts as a numeric promotion that does not modify the value of the original integer. -
static_castthestd::int64_tinto astd::int32_tso that it can fit into a JavascriptNumber. For certain values this CAN cause values to change as this is a numeric conversion - this is the issue.
The values for which conversion can cause overflows/truncation when they are larger than the maximum int32 value:
-
uint32 -
uint64 -
int64
This only occurs in the Javascript library, as Python fully supports 64 bit integers and so there is no casting to int32 required.
Possible Solutions
For users who use arrow to pass in columns of uint32, uint64 and int64 type into Perspective.js, one should use a schema and mark those columns as float type, which will ensure that all values fit and no truncation/overflow occurs. Because there is no public API for granular numeric types, we recommend users only use int32 and double numeric types when using Perspective.js.
Compared to when the project first started, BigInt is now more widely used in major browsers, but implementing it has a major caveat - it cannot be trivially converted to and from JSON, which is the format that Perspective uses to pass data to visualization plugins, etc. BigInt can have a custom JSON serializer method that renders it as a string, but it must be manually passed back into the BigInt constructor to be treated as a BigInt (JSON.parse will parse the value as a string). This would require a major refactor that changes behaviour anywhere we interact with Perspective-generated JSON, which can be time-consuming and may have performance impacts.
As discussed with @texodus offline, one possible solution is to decide the granular numeric types we would like to expose as a public API, and rewrite the public API to allow these types to be exported and used more granularly. However, that exposes the weeds of C++ numeric conversions and promotions, and could also have undesired impacts/behavior.
This write-up is to document the issue and provide a forum for discussing this problem, which should only affect a small subset of users that follow the exact issue reproduction path.
Screenshots
The following Pandas dataframe was generated and serialized to an arrow, with dtypes that match the column names (uint8 has a dtype of numpy.uint8, etc.):
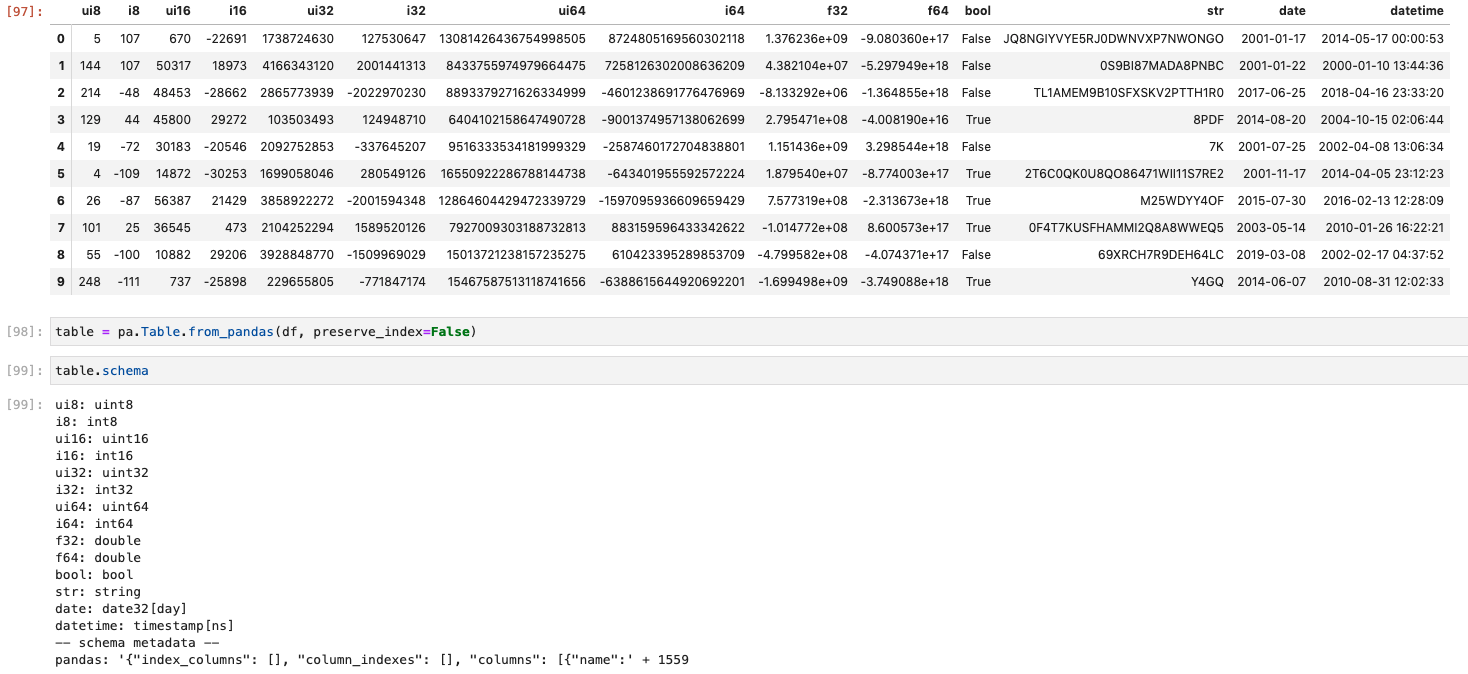
Loaded into Perspective, a printout from the C++ shows that the values are stored correctly:
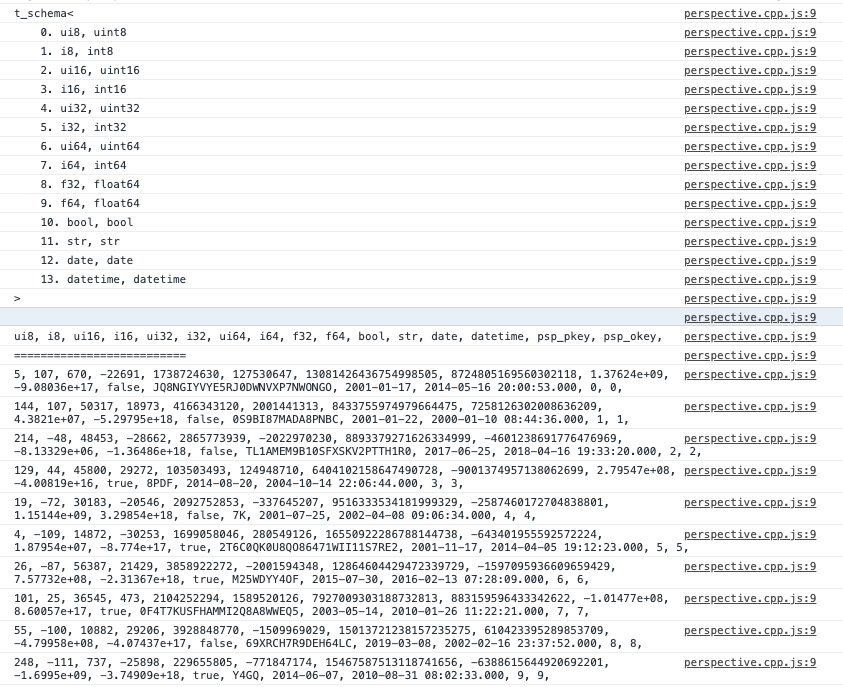
But when displayed, the values are wrong only for numbers that were above the max int32:

And an examination of the serialization process shows that the static_cast is the culprit:
uint32_t: 4166343120 // the value stored in Perspective C++
cast: -128624176 // the value above, but static_cast to int32
DTYPE_UINT32 -> int64: 4166343120 // the result of the implicit conversion to std::int64_t, which does not change the value
int64 -> cast: -128624176 // the result of the cast from int64 to int32
+1, have int32 when I need int64. Changing the columns to float rather than integer in the schema worked. Thanks
Hi @sc1f @texodus ! Can you provide a code snippet to read the schema (without reading data) of arrow file (from fetch's arrayBuffer) so I can generate the schema for creating perspective table?
Hi @sc1f @texodus the above request is to automate the workaround through casting int64 to double and set the precision to 0. I appreciate a more elegant way if exists such as after inserting data into table, I can cast all int64 columns to double, and set the precision to 0
Hello. We keep coming across this issue again and again. Although we have some workarounds for different use cases, it would be great if this was resolved on perspective side somehow.