feat: Custom threshold in SmartCorrelatedFeatures
Is your feature request related to a problem? Please describe.
Currently SmartCorrelatedFeatures takes correlation measures that have a similar range (between -1 and +1) and select features by a fixed threshold value (defaults to 0.8).
Describe the solution you'd like
Extend the threshold selection to a custom function in order to be able to apply other correlation measures that have different range as mutual information. Other measures to consider could be find here.
Describe alternatives you've considered An alternative is to create a separate class.
I had a quick look at the link, and all metrics seem to return values somewhere between -1 and 1.
Why do you think we need to expand the threshold allowance in the transformer?
Also, there is one metric, the Hoeffner D or similar, that varies between -0.5 and 1, and not sure how this metric works, but the transformer is taking the absolute value, so not sure how to make this one fit in, or even if it is a good idea to make it fit in.
For the MI calculation, I'm basing on sklearn.feature_selection.mutual_info_regression. Basically uses scipy.special.digamma which is in log scale. In theory, there would be no upper bound for this measure. For two continuous variables, here is how it is calculated.
The idea to modify this class is to return to the user the variables that are informative with MI. I think this could happen by passing a custom function to threshold that let user define how to select the features after pandas.corr() is calculated. Maybe passing custom method here, not only removing features with high correlation.
For the standard correlation functions (spearman, pearson, kendall) the value of correlation is quite intuitive, if it is >0.7 or 0.8, then the variables are probably very related.
What sort of value indicates correlation for this mutual_info_regression? Is this an accepted metric for correlation? where has it been used? (other than in sklearn, which I understand what a workaround to extend the MI to continuous targets)
The MI can detect non-linear, sinusoidal and linear relationships as well. Here is a better explanation from a Kaggle Tutorial.
In the kaggle kernel you mention it is used exactly as per sklearn docs. To determine relationship with the target and not among variables. It also does not make reference to which would be an accepted threshold to indicate that above the threshold the variables are "truly" related.
We need more info on the threshold front, and on how widely this metric is used to determine relationship among variables, instead of variables and target.
Yes, that's a good point, from what I know. Relations above 1 are periodic.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_selection import mutual_info_regression
n = 100
x = np.linspace(-4, 4, num=n)
y = np.sin(x)
plt.plot(x, y)
mutual_info_regression(x.reshape(-1, 1), y.reshape(-1, 1))
>>> 1.32
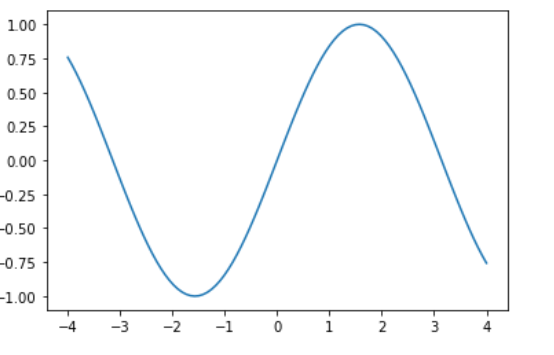
Convex or non linear relations are close to two
x = np.linspace(-1, 4, num=n)
y = np.sin(x)
mutual_info_regression(x.reshape(-1, 1), y.reshape(-1, 1))
>>> 1.8
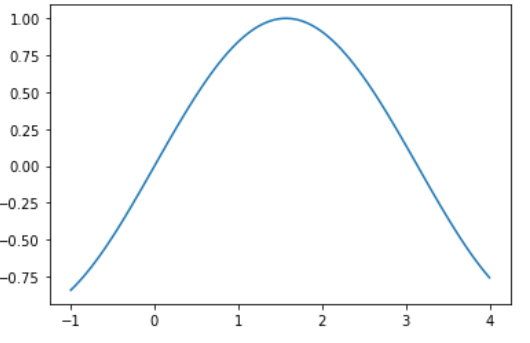
Monotonic relations above two
x = np.linspace(-4, 1, num=n)
y = np.exp(x)
plt.plot(x, y)
mutual_info_regression(x.reshape(-1, 1), y.reshape(-1, 1))
>>> 2.05
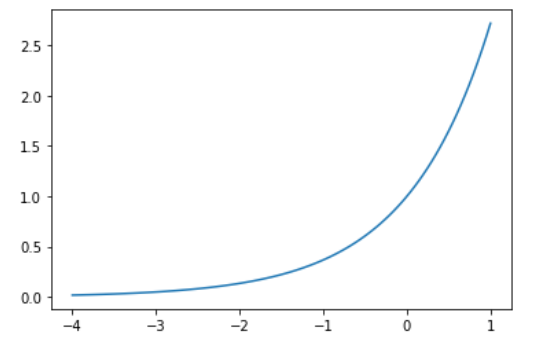
and linear relations closer to 3
import seaborn as sns
x = np.array([np.random.rand() * 100 for _ in range(100)])
y = x * 5 + np.random.randn(n) * 2
sns.scatterplot(x, y)
mutual_info_regression(x.reshape(-1, 1), y.reshape(-1, 1))
>>> 3.12
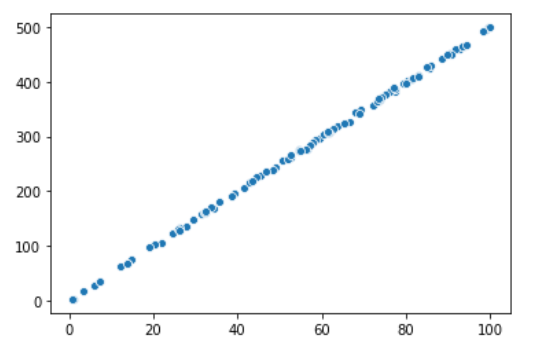
I know it is not yet widely adopted by the community, but I think it is a great addition to your toolkit to quickly understand the general relationship between the target and the covariates.
There would be no difference to apply it to determine the relationship between variables, as the same function is always applied, here.
In general, there are no many examples of its use, I think a general acceptance is values above zero, but not sure what relationship is detected for value between zero and one.
It is equal to zero if and only if two random variables are independent, and higher values mean higher dependency.
An example from sklearn.
Hi @TremaMiguel
Thanks for the detail and the plots.
I hear the pros: a fairly simple code modification, would allow the use of this technique, and virtually any other.
On the downside, not having the threshold check, may encourage users to use any value, so for users less familiar with correlation, we would not be guiding them, when setting up the transformer, to choose a value that is suitable, for the more used correlation metrics.
If this technique was widely used, I would say, yes, let's remove the threshold check. But since we are not sure that this is the case, I am disinclined to proceed.
Has the mutual information been used at all to select features? maybe we need to explore more this, and if yes, we create a dedicated transformer, to keep things simple and clear. The smartcorrelation selects based on correlation, and then, if suitable, we would have a selector based on mutual info. But I have not heard of this so far.
Regarding
On the downside, not having the threshold check, may encourage users to use any value, so for users less familiar with correlation, we would not be guiding them, when setting up the transformer, to choose a value that is suitable, for the more used correlation metrics.
We notice that method SmartCorrelatedSelection is highly dependent on three correlation measures (spearman, kendall and pearson) this turns out the method inflexible to consider other correlation measures.
So as you say, we can tackle this with two approaches:
- Modify
SmartCorrelatedSelectionto remove that high dependency and make it flexible for other methods. (It already accepts any kind of function, we just need to extend the selection or threshold criteria). I think threshold can be a method appropiate to the range of the correlation measure.
- check_zero_one: For correlation measures range ranging from zero to one.
- check_zero_inf: For correlation measures range ranging from zero to inf (mutual information).
any other ideas ?
- Separate transformer with Mutual Information method. This can be an experiment feature that could be further integrate into
SmartCorrelatedSelection, it will basically adapt the behavior ofSmartCorrelatedSelectionto Mutual Information.
and regarding
Has the mutual information been used at all to select features? maybe we need to explore more this, and if yes, we create a dedicated trasformer, to keep things simple and clear. The smartcorrelation selects based on correlation, and then, if suitable, we would have a selector based on mutual info. But I have not heard of this so far
From my own experience using this method, I see this as an easy and quick way to detect relationships, If we offer such a method with a quick and easy way to calculate relations, this could have an impact on the visibility of feature-engine, also see it the only library currently offering this method.
After considering this further, I think if the idea is to select features with the mutual information, we should have this in a dedicated transformer, where we apply that function instead of correlation.
Here are some links: https://jmlr.csail.mit.edu/papers/volume13/brown12a/brown12a.pdf https://www.researchgate.net/publication /3301850_Using_Mutual_Information_for_Selecting_Features_in_Supervised_Neural_Net_Learning
mutual info an correlation are not the same statistical technique, and in feature-engine, we try and keep each transformer to handle a specific technique, for 2 reasons:
- make it simple for users to understand what the transformer is about
- limit the amount of code (and logic) that goes into each transformer, to make developer's life easier as well