validation loss is not decreasing on NAT with zh-en data
hi, i want to train a NAT model for zh-en (about 260k) . I get about 30 BLEU on teacher model , but always overfit on student model
There are the following scripts:
zh-en preprocessing:
fairseq-preprocess --source-lang zh --target-lang en --trainpref ${data}/train.distill.bpe --validpref ${data}/valid.bpe --testpref ${data}/test.bpe --joined-dictionary --destdir ${data_dir}_distill --workers 32 \
train stu model:
fairseq-train ${data_dir}_distill --save-dir ${model_save} \
--task translation_lev \
--criterion nat_loss --arch nonautoregressive_transformer \
--noise full_mask --share-all-embeddings \
--optimizer adam --adam-betas '(0.9, 0.98)' \
--lr 5e-4 --lr-scheduler inverse_sqrt \
--stop-min-lr '1e-09' --warmup-updates 4000 \
--warmup-init-lr '1e-07' --label-smoothing 0.1 \
--dropout 0.3 --weight-decay 0.01 \
--decoder-learned-pos \
--encoder-learned-pos \
--pred-length-offset \
--length-loss-factor 0.1 \
--apply-bert-init --fp16 \
--log-format 'simple' --log-interval 300 \
--max-tokens 4096 --save-interval-updates 5000 --max-update 100000 \
--keep-interval-updates 5 --keep-last-epochs 5\
I find the validation loss is not decreasing.
Here is train and validation loss graph:
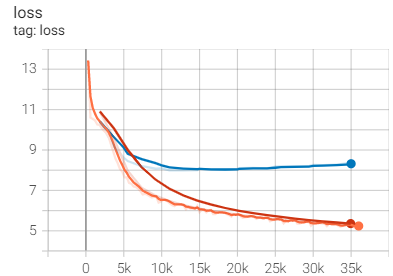 What is wrong?
Thanks!
What is wrong?
Thanks!
Hi, I am not familiar with teacher and student model. So I have some questions. How is the teacher's validatoin loss? Does that red curve represent teacher's validation loss? There are also several half transparent curves, what do they mean?
Aside from my quesionts, I would like to say it is quite common to see validation loss(the blue one?) drop for first several epochs and then go up slightly later on. In this case, I guess changing learning rate, batchsize and increasing distill data will make the student's validation loss drop a little further.
@gmryu Hi, forgive me for not making it clear. The above picture is the loss figureof the student model, and I did not save the loss figure of the teacher model. In the above figure, the red line is the train loss, blue line is the valid loss, and the orange line is the train_inner loss,other lines is not important. In the teacher model loss figure, when the model is fitted, the train loss and the valid loss will be close and flattened,but the student model does not. And, i use the same learning rate/batchsize as the teacher model to train stu model(like here) I think it would defeat the purpose of this method in the notes if adding extra distillation data
First of all, I probably won't be helpful at all. Feel free to ignore me.
So if you had time, would you mind sharing your knowledge with me? For what I understand, teacher model is trained with well-quality data and
- If there is a lot of unlabeled data, one can use teacher model to create estimated labels so the student model can be trained with more data
- or the student model is meant to be a distilled version of the teacher model.
If it is 1. I believe the student is supposed to get more data, otherwise there is no need of the teacher since labels comming from estimation may not be close enough to the original quality. If it is 2. there is no guaranteen that the student can achieve the same score with the original validation data.
So I do not understand why adding more data defeat the purpose if one wants to improve the student model.
Although, it is possible that extra data is not needed for this teacher-student approach. Then I assume data created by the teacher model should be good enought. Have you looked at a few sentences created by the teacher model and compare them with the student's ? How bad is the student model in human sense? (that 30 BLEU comes from fairseq-generate right?)
--
About that learning rate/batch size setups, your --max-tokens 4096 --noise full_mask is different than the original one, let alone your data is zh-en not en-de.
Critically, different max tokens means different batchsize and there is no telling which one is good at all.
I would say if you have the resource and time, you can try different setups to see what fits the best.
Hi, @gmryu thanks for your reply . I should belong to 2 . I use an autoregressive model as a teacher to distill the original knowledge, and I want to test how much a non-autoregressive model as a student can improve the distilled knowledge. I have tested that if you add data, it will add extra knowledge, and the student model will definitely improve, so the reason I won't add extra data for now is that I will confuse whether the improvement is due to distilled knowledge or added extra Knowledge. 30 bleu from teacher's fairseq generate Next I will try different hyperparameters, such as the maxtoken you mentioned, etc.