NEL benchmark: Add comparison of multiple evaluation runs
Description
Adds a step for the comparison of multiple evaluations, to simplify comparing e.g. multiple candidate generators. This includes
- persisting evaluation results as
.csvfiles for every execution ofspacy project run evaluatein a new directoryevaluationsand - a new workflow step merging all available individual evaluation results, sorting by run and then by model.
A run name can be configured (defaults to a stringified timestamp of format %Y-%m-%d_%H-%M-%S).
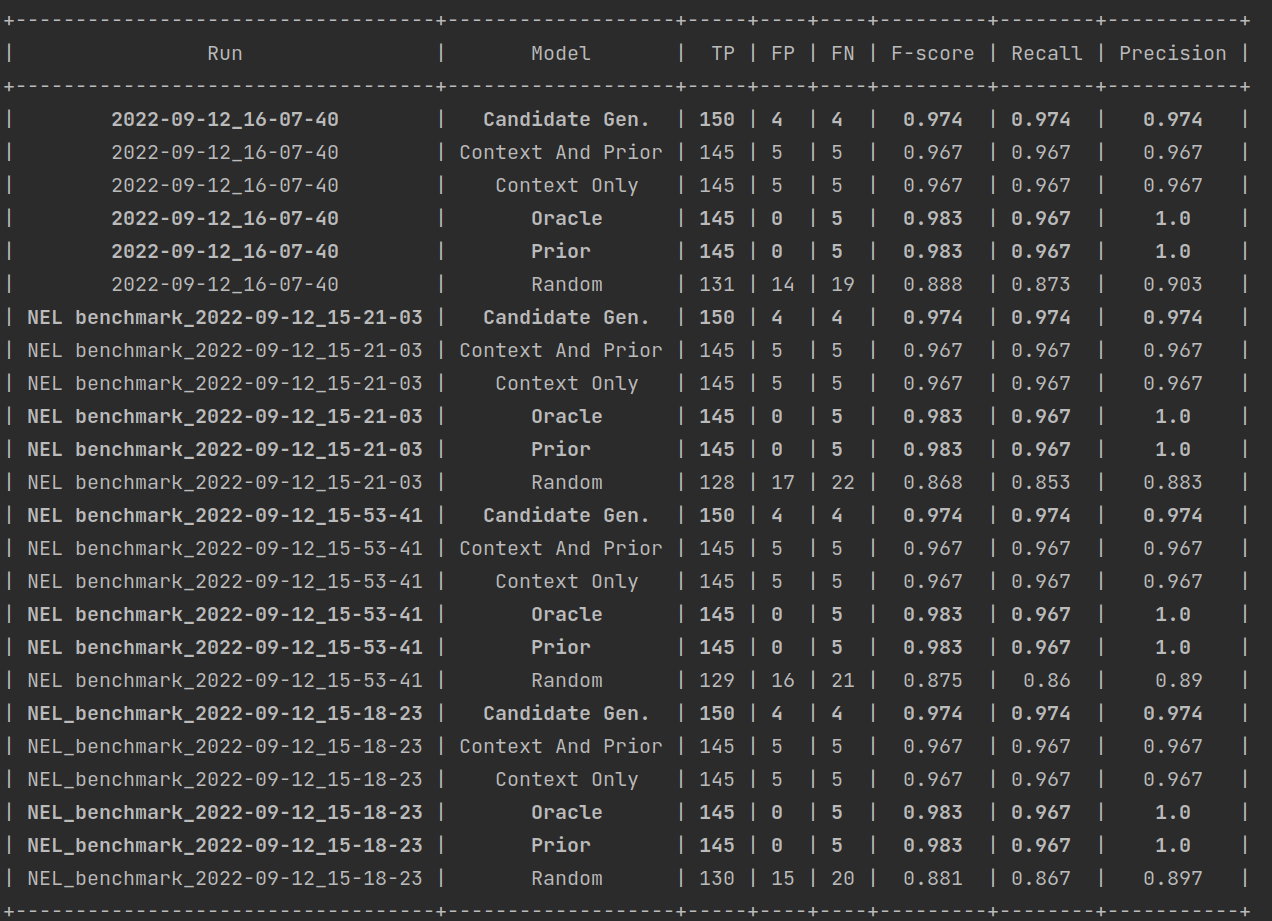
Example output:
============================ compare_evaluations ============================
Running command: env PYTHONPATH=. python ./scripts/compare_evaluations.py mewsli_9
16:30:45 INFO
+-----------------------------------+-------------------+-----+----+----+---------+--------+-----------+
| Run | Model | TP | FP | FN | F-score | Recall | Precision |
+-----------------------------------+-------------------+-----+----+----+---------+--------+-----------+
| 2022-09-12_16-07-40 | Candidate Gen. | 150 | 4 | 4 | 0.974 | 0.974 | 0.974 |
| 2022-09-12_16-07-40 | Random | 131 | 14 | 19 | 0.888 | 0.873 | 0.903 |
| 2022-09-12_16-07-40 | Prior | 145 | 0 | 5 | 0.983 | 0.967 | 1.0 |
| 2022-09-12_16-07-40 | Oracle | 145 | 0 | 5 | 0.983 | 0.967 | 1.0 |
| 2022-09-12_16-07-40 | Context Only | 145 | 5 | 5 | 0.967 | 0.967 | 0.967 |
| 2022-09-12_16-07-40 | Context And Prior | 145 | 5 | 5 | 0.967 | 0.967 | 0.967 |
| NEL benchmark_2022-09-12_15-21-03 | Candidate Gen. | 150 | 4 | 4 | 0.974 | 0.974 | 0.974 |
| NEL benchmark_2022-09-12_15-21-03 | Random | 128 | 17 | 22 | 0.868 | 0.853 | 0.883 |
| NEL benchmark_2022-09-12_15-21-03 | Prior | 145 | 0 | 5 | 0.983 | 0.967 | 1.0 |
| NEL benchmark_2022-09-12_15-21-03 | Oracle | 145 | 0 | 5 | 0.983 | 0.967 | 1.0 |
| NEL benchmark_2022-09-12_15-21-03 | Context Only | 145 | 5 | 5 | 0.967 | 0.967 | 0.967 |
| NEL benchmark_2022-09-12_15-21-03 | Context And Prior | 145 | 5 | 5 | 0.967 | 0.967 | 0.967 |
| NEL benchmark_2022-09-12_15-53-41 | Candidate Gen. | 150 | 4 | 4 | 0.974 | 0.974 | 0.974 |
| NEL benchmark_2022-09-12_15-53-41 | Random | 129 | 16 | 21 | 0.875 | 0.86 | 0.89 |
| NEL benchmark_2022-09-12_15-53-41 | Prior | 145 | 0 | 5 | 0.983 | 0.967 | 1.0 |
| NEL benchmark_2022-09-12_15-53-41 | Oracle | 145 | 0 | 5 | 0.983 | 0.967 | 1.0 |
| NEL benchmark_2022-09-12_15-53-41 | Context Only | 145 | 5 | 5 | 0.967 | 0.967 | 0.967 |
| NEL benchmark_2022-09-12_15-53-41 | Context And Prior | 145 | 5 | 5 | 0.967 | 0.967 | 0.967 |
| NEL_benchmark_2022-09-12_15-18-23 | Candidate Gen. | 150 | 4 | 4 | 0.974 | 0.974 | 0.974 |
| NEL_benchmark_2022-09-12_15-18-23 | Random | 130 | 15 | 20 | 0.881 | 0.867 | 0.897 |
| NEL_benchmark_2022-09-12_15-18-23 | Prior | 145 | 0 | 5 | 0.983 | 0.967 | 1.0 |
| NEL_benchmark_2022-09-12_15-18-23 | Oracle | 145 | 0 | 5 | 0.983 | 0.967 | 1.0 |
| NEL_benchmark_2022-09-12_15-18-23 | Context Only | 145 | 5 | 5 | 0.967 | 0.967 | 0.967 |
| NEL_benchmark_2022-09-12_15-18-23 | Context And Prior | 145 | 5 | 5 | 0.967 | 0.967 | 0.967 |
+-----------------------------------+-------------------+-----+----+----+---------+--------+-----------+
Checklist
- [x] I confirm that I have the right to submit this contribution under the project's MIT license.
- [x] I ran the tests, and all new and existing tests passed.
- [x] My changes don't require a change to the documentation, or if they do, I've added all required information.
- have an export format that's more machine-readable, like a combined CSV?
You mean for the combined evaluation results table?
- highlight the run that maximizes some criteria, maybe just with an extra row that's empty or filled with *?
Makes sense. I'll add an option to pick the criterion to highlight.
Rows with highest scores are now logged in bold. Rows related to candidate generation are treated separately, since the other rows related to disambiguation. This is a bit confusing though, maybe we should move the candidate generation rows into a separate table? Also: not sure if just making it bold is enough. At least on my console it feels rather subtle. Note that many rows are highlighted here because they all have the same (max. precision) score.
Example output (here with precision as criterion for highlighting):
have an export format that's more machine-readable, like a combined CSV?
You mean for the combined evaluation results table?
Yes, for the combined results. But without a definite use case it's not really important, so just and idea.
I was able to run your changes locally without issue. The bold is also pretty subtle here, maybe you could do reverse video instead? For ANSI escapes I was going to suggest you use wasabi (which actually also has table formatting, now that I think of it), but it doesn't seem to support reverse video, though it'd be easy to add.
Yes, for the combined results. But without a definite use case it's not really important, so just and idea.
Added an export, stored as evaluation/{dataset name}/compare-{datetime.datetime.now().strftime('%Y-%m-%d_%H-%M-%S')}.csv. Does this make sense to you?
Following up on the question in the description:
Do we want to show the table by label (in analogy to the label-based table in spacy project run evaluate) as well?
Added an export, stored as evaluation/{dataset name}/compare-{datetime.datetime.now().strftime('%Y-%m-%d_%H-%M-%S')}.csv. Does this make sense to you?
That's great, thank you! I was easily able to navigate/sort that table with a CSV tool.
Do we want to show the table by label (in analogy to the label-based table in spacy project run evaluate) as well?
Is this just about the formatting/appearance? I don't really have a strong opinion either way, so I think it's fine as-is.
Is this just about the formatting/appearance? I don't really have a strong opinion either way, so I think it's fine as-is.
No. If you run evaluate, you'll see two tables: one with the results per method (random/oracle/...), one with results per method and label. In compare_evaluation there's only the former so far (so all results per method and run), because I thought that listing all results for method x run x label would be too much info. Not sure about that though (especially since we have the export now).
Ah, I see what you mean about labels. I agree that having that all in the output for visual inspection feels like just too much info. Even considering that it could be in the machine-readable output, since we don't have a concrete need for it at the moment, I don't feel it's imperative to add it now.