Port over one of the stack monitoring parity tests
Currently we have stack monitoring parity tests running in the Elastic Stack Testing Framework (ESTF). You can read more about these tests, particularly why they were created and how they work conceptually, over here: https://github.com/elastic/elastic-stack-testing/blob/master/playbooks/monitoring/README.md.
These parity tests are broken up by each stack product that shows up in the Stack Monitoring UI, viz. elasticsearch, logstash, kibana, and beats. This division is reflected in the sub-folders seen under https://github.com/elastic/elastic-stack-testing/tree/master/playbooks/monitoring.
It would be great to try and port over one of these product's parity tests over to the e2e-testing framework, mainly to see if there are any performance or maintainability gains in the process. To that end, I'd suggest porting over the parity tests for beats or logstash, as these are the least complex ones.
It might also be useful to see some samples of these tests running in CI. For that, you can start here: https://internal-ci.elastic.co/view/Stack%20Tests/job/elastic+estf-monitoring-snapshots+master/.
Hey @ycombinator, I can start working on this.
Let me start creating a gherkin file for this. We can iterate through it to start an implementation once we are satisfied. wdyt?
Feature: the documents indexed by the internal collection method are identical in structure to those indexed by Metricbeat collection
Scenario Outline: Metricbeat collection
Given "<the_product>" sends metrics to Elasticsearch using the "internal" collection monitoring method
When "<the_product>" sends metrics to Elasticsearch using the "Metricbeat" collection monitoring method
Then the structure of the documents for the "internal" and "Metricbeat" collection are identical
Examples:
| the_product |
| elasticsearch |
| kibana |
| beats |
| elasticsearch |
Hi @mdelapenya, that sounds great, thank you! I'm familiar with BDD in general but not specifically with Gherkin so I might need some hand-holding from time to time as we iterate through this.
The scenario you outlined makes sense. One small change I'd suggest, based on recent conversations (after this issue was created), let's call it "legacy" collection instead of "internal" collection. The latter is a term we're now using to mean something slightly different, so we've invented the former to help differentiate.
Ok, let's try:
Feature: Parity Testing
Scenario Outline: The documents indexed by the legacy collection method are identical in structure to those indexed by Metricbeat collection
Given "<the_product>" sends metrics to Elasticsearch using the "legacy" collection monitoring method
When "<the_product>" sends metrics to Elasticsearch using the "Metricbeat" collection monitoring method
Then the structure of the documents for the "legacy" and "Metricbeat" collection are identical
Examples:
| the_product |
| elasticsearch |
| kibana |
| beats |
In Gherkin, the definition language for BDD:
- the
Givenclause represent the setup of the preconditions for the scenario - the
Whenclause triggers the action represented in the scenario - the
Thenclause checks the outcomes/postconditions for the scenario - the
Examplesblock will define a list ready for iteration through all its elements (not run in parallel though), so thethe_productvariable will be interpolated in 3 different tests, one per item in the table
Thanks again, @mdelapenya. A couple more things (sorry, I just realized them!):
- Minor: I just noticed
logstashwas missing from the list. - In the case of most products, the name of the Metricbeat module used for stack monitoring will be
<the_product>-xpack. However in the case ofbeats, the module name isbeat-xpack(notice the singular in the module name).
Happy to continue the iteration here or in a PR, whatever's easier for you!
logstash is not there on purpose because I read this: "...this folder only contains parity tests for Elasticsearch, Kibana, and Beats. When we implement Metricbeat collection for Logstash, corresponding parity tests will be added to this folder", but we can add it in one millisecond :)
About the xpack addition, I'm not sure: is it an implementation detail that can be hidden from the specification? If so, we can internally check that the collection method is metricbeat and do the proper massaging in the code. On the other hand, if adding the xpack suffix is something to be considered at the business level, then I'm OK with adding it here. Something like:
Feature: Parity Testing
Scenario Outline: The documents indexed by the legacy collection method are identical in structure to those indexed by Metricbeat collection
Given "<product>" sends metrics to Elasticsearch using the "legacy" collection monitoring method
When "<stack_mon_product>" sends metrics to Elasticsearch using the "Metricbeat" collection monitoring method
Then the structure of the documents for the "legacy" and "Metricbeat" collection are identical
Examples:
| product | stack_mon_product |
| elasticsearch | elasticsearch_xpack |
| kibana | kibana_xpack |
| beats | beat_xpack |
I tend to think that adding internal state to the specification (gherkin file), which can be read by a business analyst/product manager/etc, adds a technical layer to the spec that is not needed at this level. But let me know your thoughts, thanks!
BTW, I did not mention that in this last iteration I'm not changing the step structure, only the variables (in double quotes), so I can continue working with what I have
this folder only contains parity tests for Elasticsearch, Kibana, and Beats. When we implement Metricbeat collection for Logstash,
Ah, doh! Indeed, that README needs updating. I'll make a PR.
About the xpack addition, I'm not sure: is it an implementation detail that can be hidden from the specification?
Yep, definitely an implementation detail. I was mentioning it only to showcase where the naming inconsistency shows up. As for the spec, I'm ++ to leaving it out (so going back to having just the product column).
... that README needs updating. I'll make a PR.
https://github.com/elastic/elastic-stack-testing/pull/532
Ok, let's keep it like this:
Feature: Parity Testing
Scenario Outline: The documents indexed by the legacy collection method are identical in structure to those indexed by Metricbeat collection
Given "<product>" sends metrics to Elasticsearch using the "legacy" collection monitoring method
When "<product>" sends metrics to Elasticsearch using the "metricbeat" collection monitoring method
Then the structure of the documents for the "legacy" and "metricbeat" collection are identical
Examples:
| product |
| elasticsearch |
| kibana |
| beats |
| logstash |
The implementation skeleton for the only two steps would be something like this:
// @product the product to be installed. Valid values: elasticsearch, kibana, beats, logstash
// @collectionMethod the collection method to be used. Valid values: legacy, metricbeat
func (sm *StackMonitoringTestSuite) sendsMetricsToElasticsearch(
product string, collectionMethod string) error {
log.Debugf("Installing %s", product)
if collectionMethod == "metricbeat" {
log.Debugf("Installing metricbeat configured for %s to send metrics to the elasticsearch monitoring instance", product)
} else {
log.Debugf("Enabling %s collection, sending metrics to the monitoring instance", collectionMethod)
}
log.Debugf("Running %[1]s for X seconds (default: 30) to collect monitoring data internally and index it into the Monitoring index for %[1]s", product)
log.Debugf("Stopping %s", product)
log.Debugf("Downloading sample documents from %s's monitoring index to a test directory", product)
log.Debugf("Disable %s", collectionMethod)
return godog.ErrPending
}
// @collectionMethod1 the collection method to be used. Valid values: legacy, metricbeat
// @collectionMethod2 the collection method to be used. Valid values: legacy, metricbeat
func (sm *StackMonitoringTestSuite) checkDocumentsStructure(
collectionMethod1 string, collectionMethod2 string) error {
log.Debugf("Compare the structure of the %s documents with the structure of the %s documents", collectionMethod1, collectionMethod2)
return godog.ErrPending
}
Hey @ycombinator, I have a question about this: is there a requirement to run the tests in different O.S.? After mentioning this initiative to @liza-mae, she fantastically saw the OS dependency: the Ansible tests run for different OS. With the framework we are enabling here, we rely on docker-compose, so only linux-based Docker images will be used.
If we need to cross-test different platforms, then I'd suggest stopping this poc here, but wanted to know your opinion.
Hi @mdelapenya, no there is no requirement to run these for a specific OS. The purpose of these tests is to check for parity between two methods of collecting stack monitoring data. As long as the components involved in both methods all run on the same OS, we are good!
Thanks for checking, though; appreciate it!
I've just realised that we are not taking into consideration the versions of the product to be monitored. Should we move to this spec?
Feature: Parity Testing
Scenario Outline: The documents indexed by the legacy collection method are identical in structure to those indexed by Metricbeat collection
Given "<product>"-"<version>" sends metrics to Elasticsearch using the "legacy" collection monitoring method
When "<product>"-"<version>" sends metrics to Elasticsearch using the "metricbeat" collection monitoring method
Then the structure of the documents for the "legacy" and "metricbeat" collection are identical
Examples:
| product | version |
| elasticsearch | 1.0.0 |
| kibana | 1.0.0 |
| beats | 1.0.0 |
| logstash | 1.0.0 |
On the other hand, we have a stackVersion global variable, which could represent that version state 🤔, and helps us run regression tests on CI.
What do you think about using the current stack here?
Good point re: version, @mdelapenya.
The current parity tests do run against multiple versions in CI, basically the ones that are currently being actively maintained. So, as of today, that would be 8.0.0 (master), 7.8.0 (7.x), 7.7.x (7.7), 7.6.x (7.6), and 6.8.x (6.8). As you can see from the links, each branch is being run in it's own Jenkins build job.
So we will need to be able to do a similar setup. Is that something that can be achieved via the stackVersion global, like a parameterized build job that would set it or something like that?
Yes! We can trigger a build with thee following input parameters, so at some point we could create a matrix job that uses this one as a downstream job
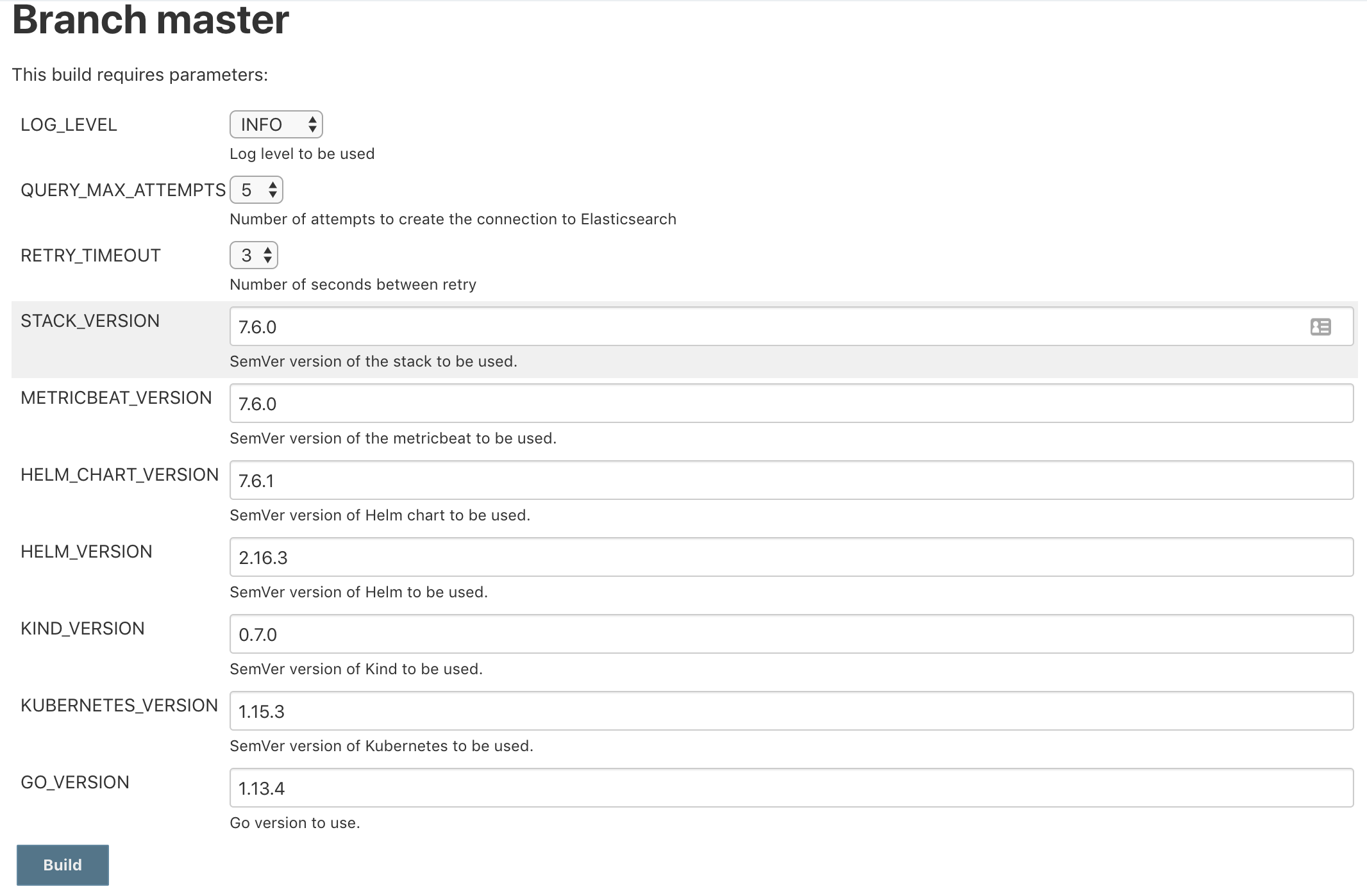
For maintenance branches (7.x), I think we must use the full version (7.6.1, 7.6.2), etc.
Another thing I've realised: the beats example. Does it represent a different test execution for each beat [audit|heartbeat|filebeat|metricbeat|packetbeat] in the ansible framework?
That would mean a change in the examples table, having this instead:
Examples:
| product | version |
| elasticsearch | 1.0.0 |
| kibana | 1.0.0 |
| logstash | 1.0.0 |
| auditbeat | 1.0.0 |
| filebeat | 1.0.0 |
| heartbeat | 1.0.0 |
| metricbeat | 1.0.0 |
| packetbeat | 1.0.0 |
We don't need to test monitoring of all different types of beats (Filebeat, Auditbeat, etc.). All Beats' monitoring data that's shown in the Stack Monitoring UI comes from libbeat, which is common to all types of Beats and APM Server as well. As a result, it's sufficient to only test with any one type of Beat. In the current parity tests, we use Filebeat (see here and here).