What should be the key_id value?
The Google tokens are now encrypted and saved in Postgres using Fields.Encrypted:

https://github.com/dwyl/app-mvp-phoenix/blob/9e1bf7dd5ac0b073f892ea9b93346f991a817407/lib/app/ctx/session.ex#L5-L12
However we do not save the key_id value yet.
I don't fully understand yet how the key value is selected. It seems to be done automatically by Fields, so I need to read the code of Fields to see how it's done and then to see if we need to select the key in the app itself first instead of letting Fields select it automatically.
The custom field Encrypted is defined in the following file:
https://github.com/dwyl/fields/blob/master/lib/encrypted.ex
When a token is saved the the dump function is called:
def dump(value) do
ciphertext = value |> to_string |> AES.encrypt()
{:ok, ciphertext}
end
The dump function uses the AES.encrypt function to encrypt the tokens:
https://github.com/dwyl/fields/blob/06aa7469a0eebe8cbaacafd2361fcdb4ad76c489/lib/aes.ex#L29-L38
def encrypt(plaintext) do
# create random Initialisation Vector
iv = :crypto.strong_rand_bytes(16)
# get the *latest* key in the list of encryption keys
key = get_key()
{ciphertext, tag} = :crypto.block_encrypt(:aes_gcm, key, iv, {@aad, to_string(plaintext), 16})
# "return" iv with the cipher tag & ciphertext
iv <> tag <> ciphertext
end
The get_key() function is used to select the key used for the encryption
# @doc """
# get_key - Get encryption key from list of keys.
# if `key_id` is *not* supplied as argument,
# then the default *latest* encryption key will be returned.
# ## Parameters
# - `key_id`: the index of AES encryption key used to encrypt the ciphertext
@spec get_key() :: String
defp get_key do
keys = Application.get_env(:fields, Fields.AES)[:keys]
count = Enum.count(keys) - 1
get_key(count)
end
and the function get_key/1 where the parameter is the index of the key in the list.
defp get_key(key_id) do
keys = Application.get_env(:fields, Fields.AES)[:keys]
Enum.at(keys, key_id)
end
So it looks like at the moment the key used when we encrypt the tokens is the current latest one.
Now when we look at the function which get the deciphered token: https://github.com/dwyl/fields/blob/06aa7469a0eebe8cbaacafd2361fcdb4ad76c489/lib/encrypted.ex#L30-L32
def load(value, key_id) do
{:ok, AES.decrypt(value, key_id)}
end
We can see that the function AES.decrypt takes the value to decrypt and the key_id. We know that by default the key used is the latest one in the list and we can see that we use this logic in the Field test for exemple:
https://github.com/dwyl/fields/blob/master/test/encrypted_test.exs
test ".load decrypts a value" do
{:ok, ciphertext} = Encrypted.dump("hello")
keys = Application.get_env(:fields, Fields.AES)[:keys]
key_id = Enum.count(keys) - 1 # Get the last key in the list
assert {:ok, "hello"} == Encrypted.load(ciphertext, key_id)
end
However I suspect that in our main application this will fail as we don't have a way to tell Fields to encrypt and decipher a value with a specific key.
@SimonLab we may need to update fields to "know" which key_id to use when extracting data from a Postgres record/row. 🤔
Yes I'm looking at the Ecto.Type documentation to see if there is a way to pass the key_id from our application to the Ecto logic (dump and load) functions. Hopefully this is possible and easy to implement
I've testing in iex getting back the tokens saved, it works but because the load function assume the key is the latest one agian:
# as above but *asumes* `default` (latest) encryption key is used.
@spec decrypt(any) :: String.t()
def decrypt(ciphertext) do
<<iv::binary-16, tag::binary-16, ciphertext::binary>> = ciphertext
:crypto.block_decrypt(:aes_gcm, get_key(), iv, {@aad, ciphertext, tag})
end
This means that if a new key is added at the end of the key list this will not work anymore.
My first idea to be able to save the token and the index of the key is for our custom type Encrypted to save a tupe or a map, eg: %{token: ..., key_id: 1}. From reading a few comments on Elixir forum I think this is doable (see https://elixirforum.com/t/ecto-3-custom-type-within-map-array-not-being-loaded-properly/25109)
If this can work it means that we don't have to create a specific key_id field in the database and session schema. For me this would look a bit nicer and we would let fields take the responsibility for getting the correct key index.
So I'm now looking at how to save a map with a custom type
I was also wondering if a custom ecto type could save data in two different fields (ie token, key_id) however it doesn't seem possible: https://elixirforum.com/t/ecto-type-for-two-fields-in-database/4914/4
Another solution mentioned on the last comment is to use a composite type in Postgres.
Reading again the phoenix-ecto-encryption-example: https://github.com/dwyl/phoenix-ecto-encryption-example#5-use-encryptedfield-ecto-type-in-user-schema
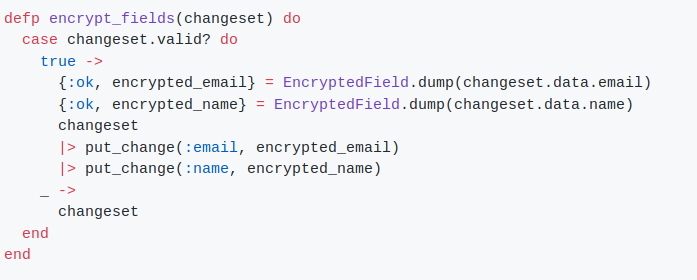
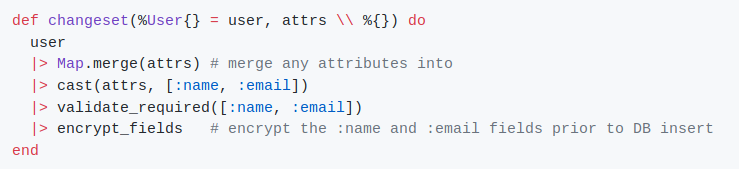
We can see that the dump function is called inside in the changeset.
I assumed that the dump and load functions were called on when Repo.insert or Repo.get were called and didn't thought it was possible to use them in the changeset.
From the documentation it is not clear for me when the function is called:
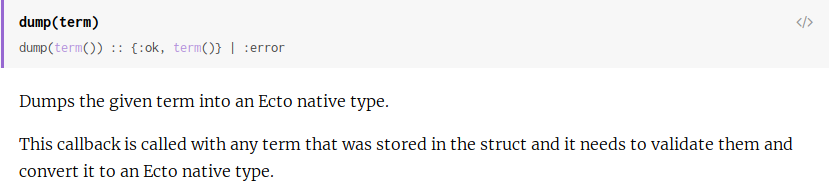
So we could use dump\2 in the changeset function to encrypt the token with a specific key (dump(token, key_id)), this means that the required callback dump/1 define by the behaviour Ecto.Type will never be used.
When retrieving the data from the database I think dump/1 will be first called then we could call dump/2 which will then decrypt the token. This means that dump/1 won't do the decrypting logic.
So in this case it seems that we bypass the behaviour Ecto.Type as we need to call the function which will encrypt/decrypt directly in the top applicaiton/changeset. I think defining a specific changeset in this case would be more logical.
I'm going to look at using the Encrypted ecto type to save a map which will contain the token and the key instead (as mention above https://github.com/dwyl/app/issues/250#issuecomment-559483909)
@SimonLab when I was writing the https://github.com/dwyl/phoenix-ecto-encryption-example
I initially considered the approach of assigning the first four bytes of "raw" data to the key_id
such that the key_id is prepended to the ciphertext before being stored in the field.
e.g: in the 3.1 Encrypt section it would be:
defmodule Encryption.AES do
@aad "AES256GCM" # Use AES 256 Bit Keys for Encryption.
@spec encrypt(any) :: String.t
def encrypt(plaintext) do
iv = :crypto.strong_rand_bytes(16) # create random Initialisation Vector
key_id = get_key_id()
key = get_key()
{ciphertext, tag} =
:crypto.block_encrypt(:aes_gcm, key, iv, {@aad, to_string(plaintext), 16})
key_id_str = String.pad_leading(to_string(key_id), 4, "0") # 1 >> "0001"
key_id_str <> iv <> tag <> ciphertext # "concat" key_id iv cipher tag & ciphertext
end
defp get_key_id do
keys = Application.get_env(:encryption, Encryption.AES)[:keys]
Enum.count(keys) - 1 # get the last/latest key from the key list
end
defp get_key do
key_id = get_key_id()
get_key(count) # use get_key/1 to retrieve the desired encryption key.
end
defp get_key(key_id) do
keys = Application.get_env(:encryption, Encryption.AES)[:keys] # cached call
Enum.at(keys, key_id) # retrieve the desired key by key_id from keys list.
end
@spec decrypt(String.t) :: String.t
def decrypt(ciphertext) do # patern match on binary to split parts:
<<key_id_str::binary, iv::binary-16, tag::binary-16, ciphertext::binary>> = ciphertext
key_id = Integer.parse(key_id_str)
key = get_key(key_id) # get encrytion/decryption key based on key_id
:crypto.block_decrypt(:aes_gcm, key, iv, {@aad, ciphertext, tag})
end
end
The reason I went with having the key_id as a separate field originally
was to save 4 bytes x number of fields per row.
For example the person schema in our App/MVP has 4 fields
that require encryption username, givenName, familyName and email
which means 16 bytes per row to store the key_id prepended to the ciphertext.
Whereas if the key_id is stored once per row in a dedicated column it only requires 1 byte per digit and we don't have to "plan ahead" for the number of bytes occupied by the id (Postgres handles storage optimisation...)
But I'm increasingly thinking that to avoid complexity we are just going to store the key_id prepended to the ciphertext regardless of how much data redundancy it creates.