Since upgrading from 17.09.0-ce connections between containers become stuck in CLOSE_WAIT and FIN_WAIT2
- [x] This is a bug report
- [ ] This is a feature request
- [x] I searched existing issues before opening this one
Expected behavior
https connections from one container to another should terminate properly
Actual behavior
Connections become stuck in pairs of CLOSE_WAIT and FIN_WAIT_2
Steps to reproduce the behavior
We have two containers running on the same host. The host runs an nginx proxy to direct traffic from different subdomains to these containers.
We make https connections from one container to the other container via the public address rather than local /docker link traffic (so we could move the other container to a different machine at some point without trouble). This went fine until recently when we upgraded the docker version from 17.09.0-ce. Now, the connections become stuck on the docker proxy:
$ netstat -ntp
tcp 0 0 172.17.0.1:33116 172.17.0.7:8080 FIN_WAIT2 21639/docker-proxy
...
tcp6 0 0 127.0.0.1:8081 127.0.0.1:60414 CLOSE_WAIT 21639/docker-proxy
This causes the initiating container to become unresponsive to http requests because its connection pool becomes depleted. It's entirely possible we're doing something wrong in our application's connection management, but these issues only crop up when upgrading the docker version so some hints towards what change might have caused this behaviour to surface would be extremely helpful.
Output of docker version:
Client:
Version: 18.03.1-ce
API version: 1.37
Go version: go1.9.5
Git commit: 9ee9f40
Built: Thu Apr 26 07:17:20 2018
OS/Arch: linux/amd64
Experimental: false
Orchestrator: swarm
Server:
Engine:
Version: 18.03.1-ce
API version: 1.37 (minimum version 1.12)
Go version: go1.9.5
Git commit: 9ee9f40
Built: Thu Apr 26 07:15:30 2018
OS/Arch: linux/amd64
Experimental: false
Output of docker info:
Containers: 7
Running: 6
Paused: 0
Stopped: 1
Images: 128
Server Version: 18.03.1-ce
Storage Driver: aufs
Root Dir: /var/lib/docker/aufs
Backing Filesystem: extfs
Dirs: 138
Dirperm1 Supported: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file logentries splunk syslog
Swarm: inactive
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 773c489c9c1b21a6d78b5c538cd395416ec50f88
runc version: 4fc53a81fb7c994640722ac585fa9ca548971871
init version: 949e6fa
Security Options:
apparmor
seccomp
Profile: default
Kernel Version: 4.4.0-127-generic
Operating System: Ubuntu 16.04.4 LTS
OSType: linux
Architecture: x86_64
CPUs: 2
Total Memory: 1.904GiB
Name: box006.drugis.org
ID: 7YEE:7CCT:TQ5P:VF2V:TW2W:42RF:I6V6:TRIW:4LAU:CH3N:33A2:CXWU
Docker Root Dir: /var/lib/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
WARNING: No swap limit support
I encounter the same issue
# docker version
Client:
Version: 18.03.1-ce
API version: 1.37
Go version: go1.9.5
Git commit: 9ee9f40
Built: Thu Apr 26 07:17:14 2018
OS/Arch: linux/amd64
Experimental: false
Orchestrator: swarm
Server:
Engine:
Version: 18.03.1-ce
API version: 1.37 (minimum version 1.12)
Go version: go1.9.5
Git commit: 9ee9f40
Built: Thu Apr 26 07:15:24 2018
OS/Arch: linux/amd64
Experimental: false
The FIN_WAIT2 keeps increasing even if I set tcp_fin_timeout to 10
# netstat -an | grep FIN_WAIT2 | wc -l
130110
But if check FIN_WAIT2 connections within the container, nothing there
# docker exec -ti uls netstat -an | grep FIN_WAIT2 | wc -l
0
It seems all of them are from docker-proxy or other docker component
Same issue, same version. Is there anything I can share to help work this out?
We have encountered similar problem on 18.09.0 version. Setup is nginx (not containerized) + our web service in container. We are processing 10-20 requests per second. After a while thousands of connections with docker-proxy are in CLOSE_WAIT and FIN_WAIT2 states and we are going out of file descriptors limit.
I have the same issue. Version is 18.09.1.
Typical scenario for me is the following:
- I start my container, which has an apache2 server,
- I run netstat in that container to monitor how things are going,
- For a while, I can establish connections properly from my host to that apache2 container. Connections are properly closed.
- After a while, seemingly randomly (heavier load seem to accelerate it, but is not necessary), every connection I make to that container is stuck in 'ESTABLISHED' and doesn't consume its "Recv-Q" until I close it client side. At that point, it still does not consume its "Recv-Q" and becomes stuck forever in 'CLOSE_WAIT' status until I restart the container.
Example of a connection from my host to my container, as seen by 'netstat -pantu' run inside the container:
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 454 0 172.27.0.9:80 172.27.0.1:46012 ESTABLISHED -
It remains in this state seemingly indefinitely, until I close it client-side (e.g., pressing "Esc" in my web browser). Then I get stuck at:
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 455 0 172.27.0.9:80 172.27.0.1:46012 CLOSE_WAIT -
From my host, 'netstat -pantu' shows the following line:
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 172.27.0.1:46012 172.27.0.9:80 FIN_WAIT2 29850/docker-proxy
If anyone has a workaround until there is a fix, or some pointers, it would be much appreciated.
For us the 'fix' was to simply downgrade docker again, but obviously that's not a sustainable solution.
Same here. The only fix I found is to restart networking devices. service networking restart &
But again, not sustainable solution.
Or to restart periodically your reverse proxy container.. with a cron...
Confirming the issue, ipv6 connections stay is state FIN_WAIT2 and ipv4 connections between nginx container and docker-proxy in state CLOSE_WAIT
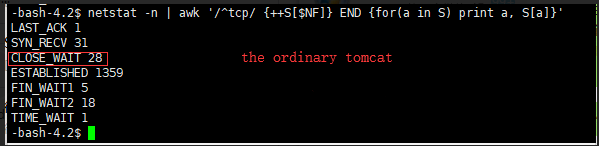
I have the same issue, my docker version is 17.05.0-ce. Run two identical tomcat services, One is the ordinary tomcat, The other is docker started tomcat. There are a lot of close wait cases for tomcat started by docker.


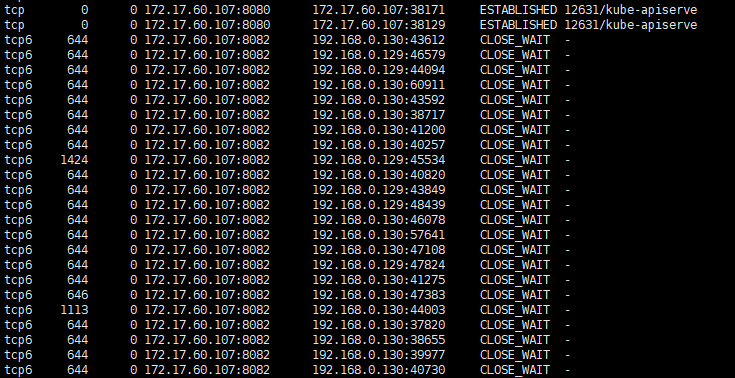
For us the 'fix' was to simply downgrade docker again, but obviously that's not a sustainable solution.
Could you please tell me which version of docker to use to avoid this problem?
For us the 'fix' was to simply downgrade docker again, but obviously that's not a sustainable solution.
Could you please tell me which version of docker to use to avoid this problem?
We went back to 17.09.0-ce and things worked OK. We've since then moved to kubernetes hosting however, so I can't tell you if newer dockers have fixed this issue.
For us the 'fix' was to simply downgrade docker again, but obviously that's not a sustainable solution.
Could you please tell me which version of docker to use to avoid this problem?
We went back to 17.09.0-ce and things worked OK. We've since then moved to kubernetes hosting however, so I can't tell you if newer dockers have fixed this issue.
Thank you, using the 17.09 version of docker, the connection in the close_wait state has been reduced a lot.
I seem to still experience this issue severely as well. Containers just run fine for a while, until CLOSE_WAIT connections start piling up and the containers finally stop responding, with connections hanging on SYN_SENT.
# docker version
Client: Docker Engine - Community
Version: 19.03.2
API version: 1.40
Go version: go1.12.8
Git commit: 6a30dfca03
Built: Thu Aug 29 05:29:49 2019
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 19.03.2
API version: 1.40 (minimum version 1.12)
Go version: go1.12.8
Git commit: 6a30dfca03
Built: Thu Aug 29 05:28:23 2019
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.2.6
GitCommit: 894b81a4b802e4eb2a91d1ce216b8817763c29fb
runc:
Version: 1.0.0-rc8
GitCommit: 425e105d5a03fabd737a126ad93d62a9eeede87f
docker-init:
Version: 0.18.0
GitCommit: fec3683
# netstat -na | grep CLOSE_WAIT -c
432
docker-proxy accepts external connections just fine and attempts to create the connection to the container, hanging forever. Connections get stuck in SYN_SENT within the container, until the client tears down the connection, making the transition to CLOSE_WAIT from the container perspective. Connection get stuck there forever.
This CLOSE_WAIT connections are never cleaned up. It is not even possible to stop or kill the container, as the process does not seem to be able to clean up its own fds. Is there any new development on this at all?
Please also note that such CLOSE_WAIT connection are only visible from the container's namespace, and not from the host's.
May this be relevant to what it is been observed here? https://blog.cloudflare.com/this-is-strictly-a-violation-of-the-tcp-specification/
What operating system do you all run? When running RHEL 7.7 (with Centos Docker-CE packages) we have this problem with Docker version 19.03.5, build 633a0ea. We updated to that version because we used to have problems with 18.03. Everything worked perfectly fine on 18.03 and one day this problem showed up and we are not able to figure out what caused this and how to solve this...
We experience the same issue with https connection through the gateway to the container. We're running on Ubuntu 16.04.5 LTS.
$ sudo netstat -an | grep FIN_WAIT2
tcp 0 0 10.174.174.1:33638 10.174.174.40:49443 FIN_WAIT2
$ sudo netstat -an | grep FIN_WAIT2 | wc -l
43
$ sudo docker version
Client:
Version: 17.09.1-ce
API version: 1.32
Go version: go1.8.3
Git commit: 19e2cf6
Built: Thu Dec 7 22:24:23 2017
OS/Arch: linux/amd64
Server:
Version: 17.09.1-ce
API version: 1.32 (minimum version 1.12)
Go version: go1.8.3
Git commit: 19e2cf6
Built: Thu Dec 7 22:23:00 2017
OS/Arch: linux/amd64
Experimental: false
Is there a correct workaround for it ?
@trourance We are recreating our Nginx container every couple of hours, which somehow frees up the stuck tcp connections. I think recreating our Mariadb container somehow does the same...
I've dome some investigations into stuck connections in FIN-WAIT-2 state for our Nimbus Eth 2.0 Node project which we were running with Docker 20.10.2 on Ubuntu 20.04.1, and the solution that we've chosen was to ditch the docker-proxy by setting userland-proxy:false, which as far as I can tell has fixed the problem with the growing number of FIN-WAIT-2 connections.
In my opinion the issue is caused by the combination of docker-proxy and a few other circumstances. I say this because we have many other pieces of software using docker-proxy without such stuck connections, so it's not just docker-proxy that triggers this issue.
Triggered at a fixed time every day, very strange. I can only kill the docker-proxy process and restart
Docker version 20.10.11 and Debian 11 With squid proxy in container, and many users, I can reach more than 35 0000 CLOSE_WAIT in container
Without docker nat the problem seems gone
ports: - "10.x.x.x:3128:3128"
EDIT: My issue is not between containers
Issue still happening for me on Debian 10 running latest Docker. Very low traffic site with hundreds of FIN_WAIT2 connections. Must be restarted periodically as they stack up. Docker version 23.0.3, build 3e7cbfd