OutOfMemoryError failure when process huge csv file.
Hi guys
csv-validator is a really powerful tool for efficient data exchange, thanks for your contribution!
I just met an problem when I validate a huge csv file which contains 10Millions+ records. That would be wonderful if you guys could fix the issue in the later version.
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at scalaz.DList$.fromList(DList.scala:78)
at scalaz.std.ListInstances$$anon$1.traverseImpl(List.scala:66)
at scalaz.std.ListInstances$$anon$1.traverseImpl(List.scala:14)
at scalaz.Traverse$Traversal.run(Traverse.scala:50)
at scalaz.Traverse$class.sequence(Traverse.scala:101)
at scalaz.std.ListInstances$$anon$1.sequence(List.scala:14)
at scalaz.syntax.TraverseOps.sequence(TraverseSyntax.scala:27)
at uk.gov.nationalarchives.csv.validator.AllErrorsMetaDataValidator$class.rulesForCell(AllErrorsMetaDataValidator.scala:62)
at uk.gov.nationalarchives.csv.validator.api.CsvValidator$$anon$2.rulesForCell(CsvValidator.scala:32)
at uk.gov.nationalarchives.csv.validator.MetaDataValidator$class.validateCell(MetaDataValidator.scala:275)
at uk.gov.nationalarchives.csv.validator.api.CsvValidator$$anon$2.validateCell(CsvValidator.scala:32)
at uk.gov.nationalarchives.csv.validator.AllErrorsMetaDataValidator$$anonfun$1.apply(AllErrorsMetaDataValidator.scala:44)
at uk.gov.nationalarchives.csv.validator.AllErrorsMetaDataValidator$$anonfun$1.apply(AllErrorsMetaDataValidator.scala:42)
at scala.collection.immutable.List.map(List.scala:273)
at uk.gov.nationalarchives.csv.validator.AllErrorsMetaDataValidator$class.rules(AllErrorsMetaDataValidator.scala:42)
at uk.gov.nationalarchives.csv.validator.api.CsvValidator$$anon$2.rules(CsvValidator.scala:32)
at uk.gov.nationalarchives.csv.validator.MetaDataValidator$class.validateRow(MetaDataValidator.scala:235)
at uk.gov.nationalarchives.csv.validator.api.CsvValidator$$anon$2.validateRow(CsvValidator.scala:32)
at uk.gov.nationalarchives.csv.validator.AllErrorsMetaDataValidator$class.validateRows$1(AllErrorsMetaDataValidator.scala:30)
at uk.gov.nationalarchives.csv.validator.AllErrorsMetaDataValidator$class.validateRows(AllErrorsMetaDataValidator.scala:35)
at uk.gov.nationalarchives.csv.validator.api.CsvValidator$$anon$2.validateRows(CsvValidator.scala:32)
at uk.gov.nationalarchives.csv.validator.MetaDataValidator$$anonfun$11.apply(MetaDataValidator.scala:186)
at uk.gov.nationalarchives.csv.validator.MetaDataValidator$$anonfun$11.apply(MetaDataValidator.scala:150)
at resource.AbstractManagedResource$$anonfun$5.apply(AbstractManagedResource.scala:86)
at scala.util.control.Exception$Catch$$anonfun$either$1.apply(Exception.scala:125)
at scala.util.control.Exception$Catch$$anonfun$either$1.apply(Exception.scala:125)
at scala.util.control.Exception$Catch.apply(Exception.scala:103)
at scala.util.control.Exception$Catch.either(Exception.scala:125)
at resource.AbstractManagedResource.acquireFor(AbstractManagedResource.scala:86)
at resource.DeferredExtractableManagedResource.either(AbstractManagedResource.scala:29)
at uk.gov.nationalarchives.csv.validator.MetaDataValidator$class.validateKnownRows(MetaDataValidator.scala:189)
at uk.gov.nationalarchives.csv.validator.api.CsvValidator$$anon$2.validateKnownRows(CsvValidator.scala:32)
Thanks!
Alex
Hi, as noted in the user guide, memory can be an issue with large files, particularly if you are using the uniqueness test, as the validator has to build a hashmap to be able to test for that. The user guide does describe how to increase the available Java heap http://digital-preservation.github.io/csv-validator/#toc16. The largest heap we've had to employ ourselves is 6GB.
If you're not using unique at all, then please let us know and we will investigate further, otherwise I will close this issue in a few days.
@DavidUnderdown there are improvements that we could make to 'unique' to reduce memory. For example switching the in-memory data structure to a trie, perhaps a bloom filter, and keeping the absolute map of unique values on persistent storage as opposed to in memory.
@autoasm @DavidUnderdown is there a publicly available huge CSV file and CSV schema we could use for testing?
Hey guys, just a bump on this. I've built a service that opens up an inputstream (from S3) and invokes the validate function.
Testing is showing this to be very memory hungry. For testing I'm processing a 179Mb input file with 1.5 million rows (found here: http://eforexcel.com/wp/downloads-18-sample-csv-files-data-sets-for-testing-sales/).
I'm seeing it use around 1.6Gb of heap, which seems like a rather large amount. Each peak in the following graph is a run of the service:
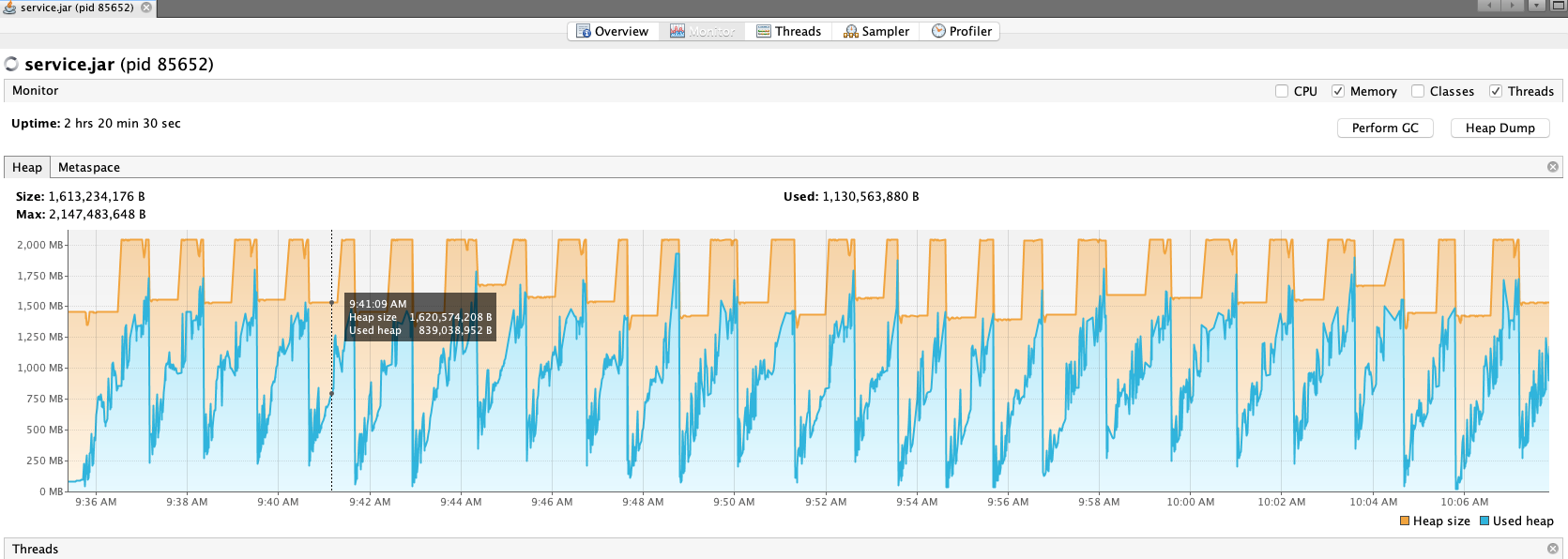
It looks like the biggest memory use is from scala.collection.immutable.$colon$colon:
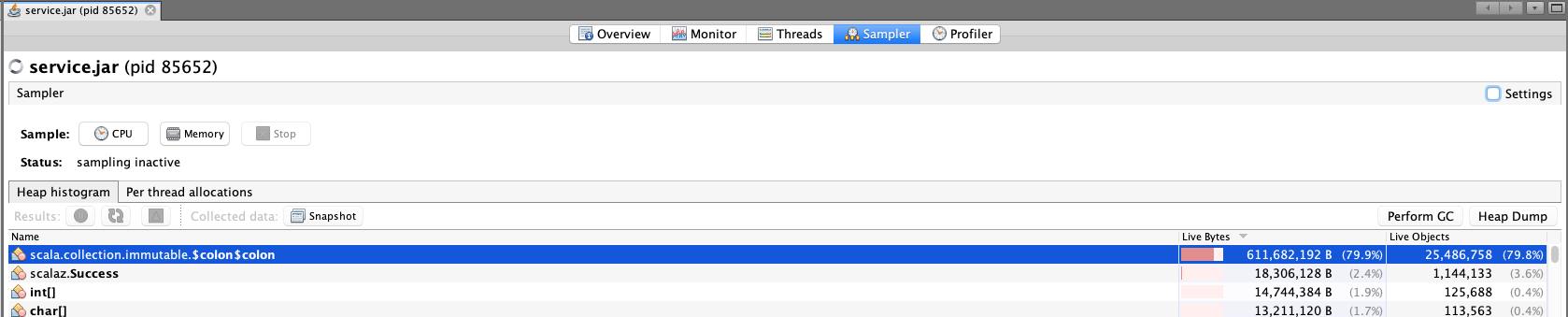
My schema is:
version 1.1
@totalColumns 14
Region: any("Asia","Australia and Oceania","Central America and the Caribbean","Europe","Middle East and North Africa","North America","Sub-Saharan Africa")
Country: notEmpty
"Item Type": any("Baby Food","Beverages","Cereal","Clothes","Cosmetics","Fruits","Household","Meat","Office Supplies","Personal Care","Snacks","Vegetables")
"Sales Channel": any("Offline","Online")
"Order Priority": any("C","H","L","M")
"Order Date": regex("^\d+/\d+/\d+$")
"Order ID": regex("^\d+$")
"Ship Date": regex("^\d+/\d+/\d+$")
"Units Sold": regex("^\d+$")
"Unit Price": regex("^\d+\.\d{2,2}$")
"Unit Cost": regex("^\d+\.\d{2,2}$")
"Total Revenue": regex("^\d+\.\d{2,2}$")
"Total Cost": regex("^\d+\.\d{2,2}$")
"Total Profit": regex("^\d+\.\d{2,2}$")
179Mb isn't even very big as far as the files I intend to process goes...
Just an update, my original testing was with Java 8 and version 1.1.1 of the validator.
An updated test on java 10 and the 1.2-RC2 performs much better as far as memory management goes for my test file. Memory use is stable for files up to 4Gb (without any unique checks)
There were some big improvements in #135 - they would certainly help with your example as caching of regex was introduced among other improvements. This is included 1.1.5 and 1.2-RC2
It might be worth adding -XX:+ExitOnOutOfMemoryError to the start up scritps, it will then stop the validation as soon as the first such error is reported, rather than limping on until the heap is full (see https://www.oracle.com/technetwork/java/javase/8u92-relnotes-2949471.html )
Do we know if this is still a problem?
Uniqueness checks excluded for this sort of problem I'd expect constant memory usage and linear execution time, and I'm not seeing anything in the code that looks 'wrong' in this regard. I'm expecting everything to be largely IO bound, but if we're doing anything CPU-heavy we might get some speedup through using fs2 throughout. It looks like we're making two passes through the data, the first one being to get the number of rows. Obviously if we don't need the first one that'll save us IO.
With regards to the uniqueness checks I'm not sure what approach to take. HashSet would be slightly better, but then obviously we can't tell the user the line number where the duplicate exists. My concern with bloom filters and other probabilistic approaches is that users of a validator might demand absolute certainty as to if something is valid or not. Putting an index in non-volatile might be the best bet, but I'm not sure what would be the best method. Moving the data into H2 or the like feels a bit overkill.
I'll do some performance testing and try to get a better picture of time and memory used.
It tends to happen if there's a lot of errors being encountered. Initially one problem was that 32-bit Java had quite a low max heap size, that is probably less of an issue now, but with the typical default heap size it is still possible to run in to issues. As well as my suggestion of adding -XX:+ExitOnOutOfMemoryError into the batch scripts there may be ways of ensuring heap size is normally set larger?
Ah okay. I was able to reproduce this, and the files don't need to be very large either - I was filling up 8GB of heap with a file about 70MB in size when using an inappropriate csvs file (i.e. a few errors per line).
Rather than trying to tune the JVM I think the best approach here is to output the errors straight to stderr when they occur (in the case of the cmd implementation) rather than accumulate them, perhaps via a callback function.
I'm doing a PoC streaming approach that does this under a different branch, and it doesn't have this problem (but it lacks some of the other features at the moment).
We will still have the issue of what to do with the uniqueness tests on huge files, of course....