dedededefo
dedededefo
> After creating the tokenizer, what does this returns ? > > ```python > for i, vocab in enumerate(tokenizer.vocab): > print(f'vocab {i}: {len(vocab)} tokens') > ``` 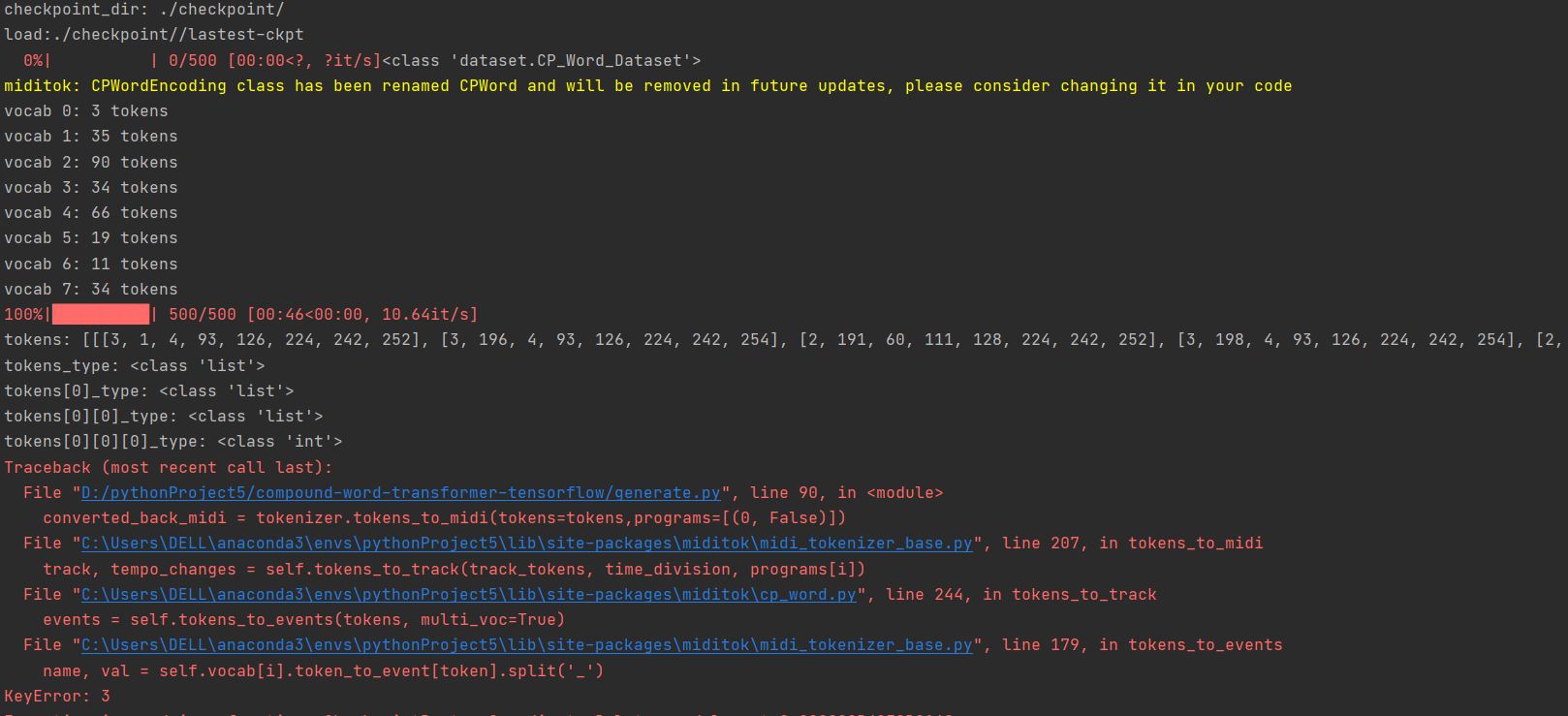
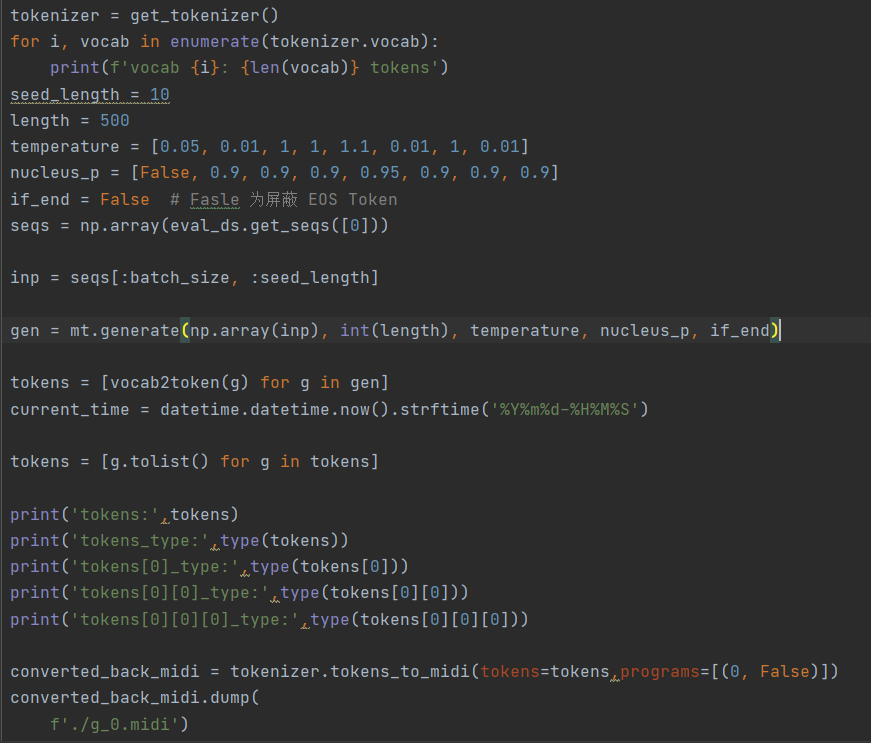
It's OK for me to rewrite MIDI using the existing MIDI data. I compare the type of data sequence generated by the model with the existing MIDI data type and...
> 我可以使用现有的 MIDI 数据重写 MIDI。我将模型生成的数据序列的类型与现有的 MIDI 数据类型进行比较,发现是一致的。list 和 int 都满足输入要求 
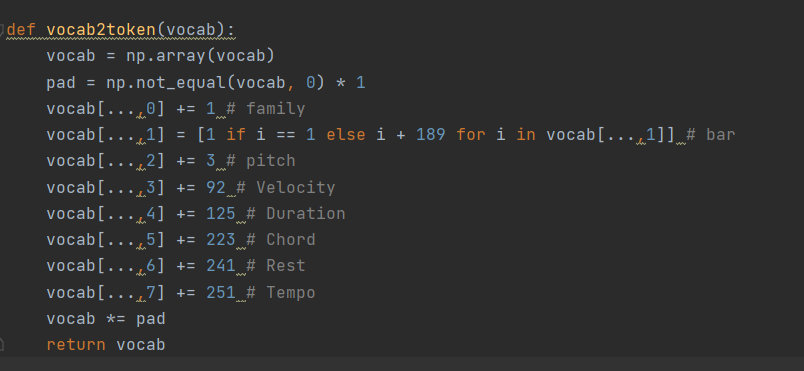 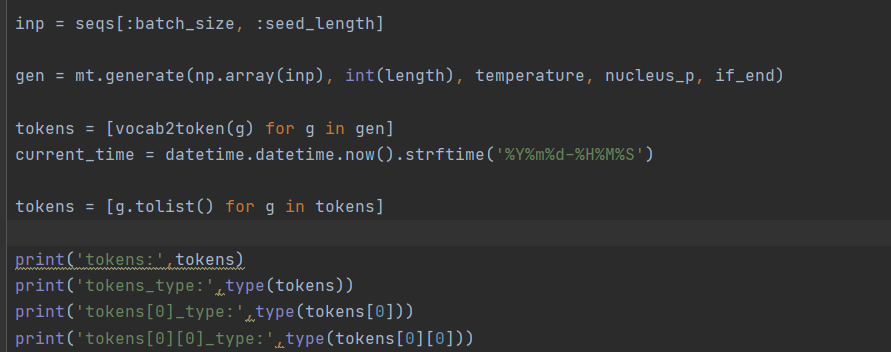 Maybe is the problem of vocab2token()?
Because I did token2vocab during model training, I got the corresponding vocab when the model generated midi. I need to restore it to token and then generate midi 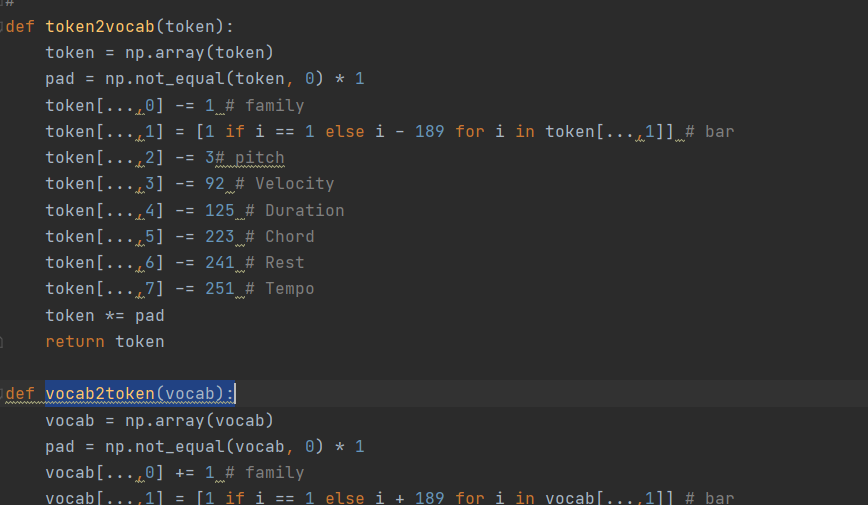 I'm...
I feel I need to retrain the model!Thank you for your advice! be deeply grateful!
> 好的,错误是因为您试图解码第一个索引(令牌系列)值为 3 的令牌,而词汇表仅包含 3 个令牌(0 到 2)。 > > 的作用是`vocab2token`什么?为什么要增加令牌? 与`gen`采样令牌一样,是否足以通过它`tokenizer.tokens_to_midi`? > 不客气,感谢您的错误报告! 我仍然不确定 and 的用途`token2vocab`,`vocab2token`因为 miditok 给出的标记应该被很好地格式化以直接与模型一起使用(范围从 0 到 len(vocab))。 Hello! Sorry, I went to dinner just now!...
 It seems that a [eos]family token is added
> Hi, > > It's an interesting question. We did have such kind of discussion at the early stages. We used to run validation during training and found the validation...